GCP Machine Learning Engine 幫您節省大量維運成本!
隨著近期機器學習( Machine Learning,以下簡稱 ML )的熱潮,企業拿自己的機器學習模型做測試已經是司空見慣,且在這之中大部分的企業會選擇使用 TensorFlow。因 TensorFlow 開放原始碼,您可以在自己的電腦上做原型測試,讓您可以在小規模的程式驗證執行上快速測試。當您測試完畢,您可以將你在電腦上測試好的 TensorFlow 資料放進 Google Cloud,並可混合架構上的 CPU、GPU 甚至 TPU 達到優化效果。
* TensorFlow 機器學習軟體
* TPU 比 GPU 快 15~30 倍的處理器
當您準備好將你的 ML 工作提升到下一個階段,您就必須針對基本設定做一些調整。一般來說,這些選擇將會影響到運作工程和 ML 工程花費的時間。
為了幫助您快速了解,我們已經發佈一系列的教學課程,像是關於如何在 Google Compute Engine 上創立和執行,以及如何執行相同的程式在 Google Machine Learning Engine 上訓練模型。我們使用 MNIST model 作為 ML 的基礎模型,或許這不是最好的運作數據庫,但我們能夠用來加強解決工程方面的問題。
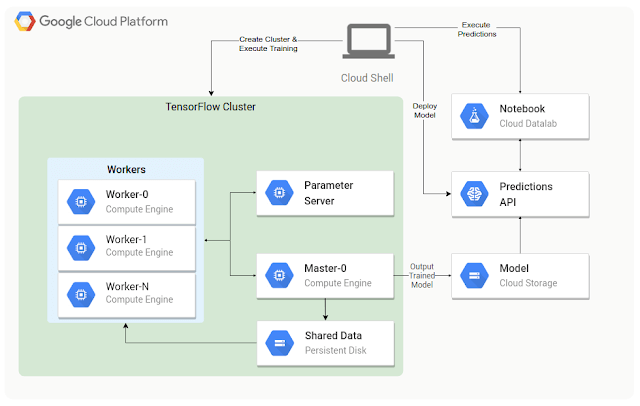
在上述已經提過 TensorFlow 有開放原始碼,所以您可以在自己的筆電上運作,或是在自有機房的 sever 端運作,甚至在 Raspberry PI 上運行。TensorFlow 可以在分散式叢集中運作,讓您可以分散程式運行的工做到多台機器上,以節省時間。第一個實例是如何在 Compute Engine 上運行 TensorFlow,如(圖 1) 所示,藉由創造一個可重複使用的客製化映像檔,並且利用 Cloud Shell 執行初始化腳本。創建一個能夠正常執行的環境需要許多步驟。儘管這些步驟不是很複雜,不過這些維運相關的步驟的確會花掉一些本來可以用在ML開發上的時間。
* distributed cluster 分散式管理不同項目內容
* Cloud Shell 可以方便管理雲端資源的瀏覽器
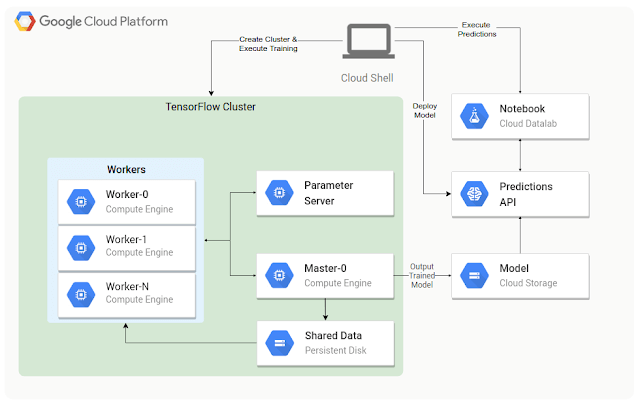
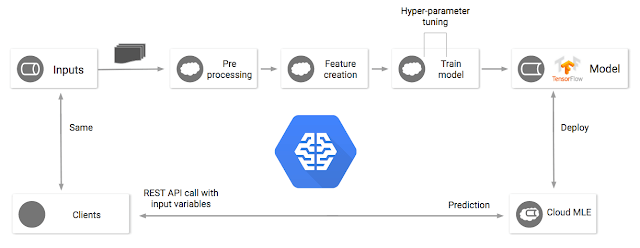
第二個實例是使用相同的程式碼在 Cloud ML Engine 運行,且只需一行指令便能自動配置訓練模型所需的資源。這項解決方案也深入解決了神經網路和分散式訓練的細節。如 (圖2) 所示,您甚至能夠使用 TensorBoard 將訓練機器的成果視覺化。而在分配資源上所節省的時間能夠花費在分析您的ML。
無論您如何訓練您的模型,最終所希望達成的目標是能夠“預測”。
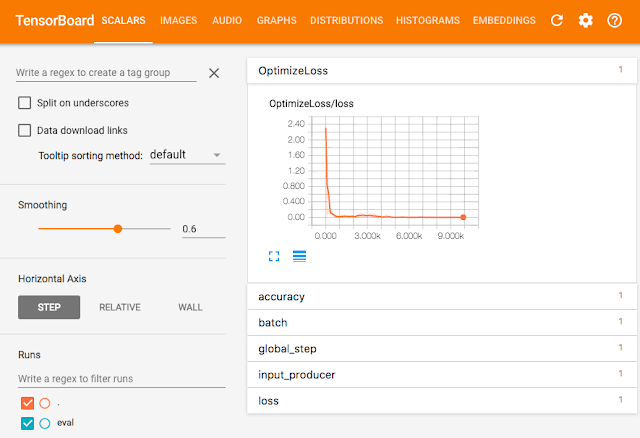
傳統上,這是需要花費最多工程去完成的部分。如果您想要用 web-service 去做預測,您最少需要做設定配置、網路安全、伺服器、負載平衡、監視等等,以及自行創建某種執行程式。在這兩種實例中,您將會使用 Cloud ML Engine 預測服務,能夠幫助您有效的省下維運工作,讓您的模型能夠在穩定、有彈性且安全的環境中運行。一旦建立了預測模型,您將快速建立 Cloud Datalab 並下載一個簡單的範例去執行預測測試。在這個範例中,您能夠用滑鼠或觸控板畫一個數字(如圖 3 所示),此數字將會被轉換到與 MNIST data 中相互匹配的矩陣格式。分析完後,這個範例將會發送圖像到新的預測 API 中,並且告訴您數據分析的結果如 (圖 4)。
上述的過程同時也展示了一項在管理模型時非常重要但卻容易被忽略的重點,而這項重點也是可以藉由 Cloud ML Engine 和 Cloud Dataflow 輕易解決的。當使用預先建立好的機器學習模型處理標準資料時,容易忽略機器學習的訓練、部署,而預測結果為一系列數據分析後的表層結果。事實上,您所掌握的數據通常並不是為了提供機器學習而刻意搜集的,而且搜集的資料通常也不能在不經處理的狀態下直接使用。
在進行預測的時候,您從客戶端收到的資料即是前述的未經整理的資料。然而,您的 TensowFlow model 是經由(…各種整理方式…)所清理過的資料所訓練出來的。
而您用來支持預測工作的基礎設施可能不是由 Python 撰寫的。在這樣的形況下,為了能重現前述在訓練 TensorFlow model 之前的預處理步驟,您可能需要花費大量時間,以在基礎設施上運用既有環境及程式語言重建這些預處理步驟。在許多狀況下,這些用不同語言或環境重建出的預處理步驟會和原本的處理方式不一致,即使不一致的部分相當少,也可能導致預測成果不如預期。
藉由Cloud Dataflow去執行預處理以及由Cloud ML Engine去執行預測,可以大幅減少額外的工程工作。因為 Cloud Dataflow 可以將預處理的程式碼同時用於訓練前的資料處理以及預測時的資料處理。
總結
TensorFlow增加了新的 APIs和抽象層讓您能夠隨心所欲的發展自己的機器學習模型。Cloud Machine Learning Engine 是構築在 TensorFlow 之上的,所以您不會被綁在特定的代管服務上。如果您需要的話,您也可以在 Compute Engine 上自行建立 TensorFlow 集群,就如同前述的第一個使用範例。但我們認為您應該希望能更快速的完成工程工作以及建置預測訓練的環境,並且把時間花在轉換、分析以及改善您的模型。藉由Cloud Machine Learning Engine、Cloud Datalab以及Cloud Dataflow的幫助, 您可以大幅縮短您的時間。將維運的部份交給我們,把寶貴的時間花在分析資料,將分析結果視覺化,以及搭建可同時用於訓練和預測的預處理架構。