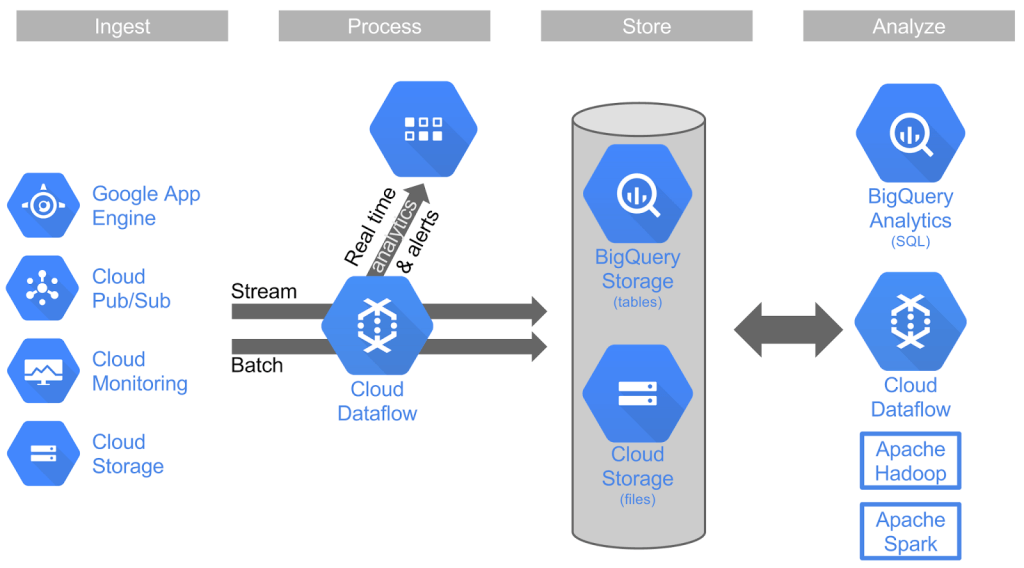
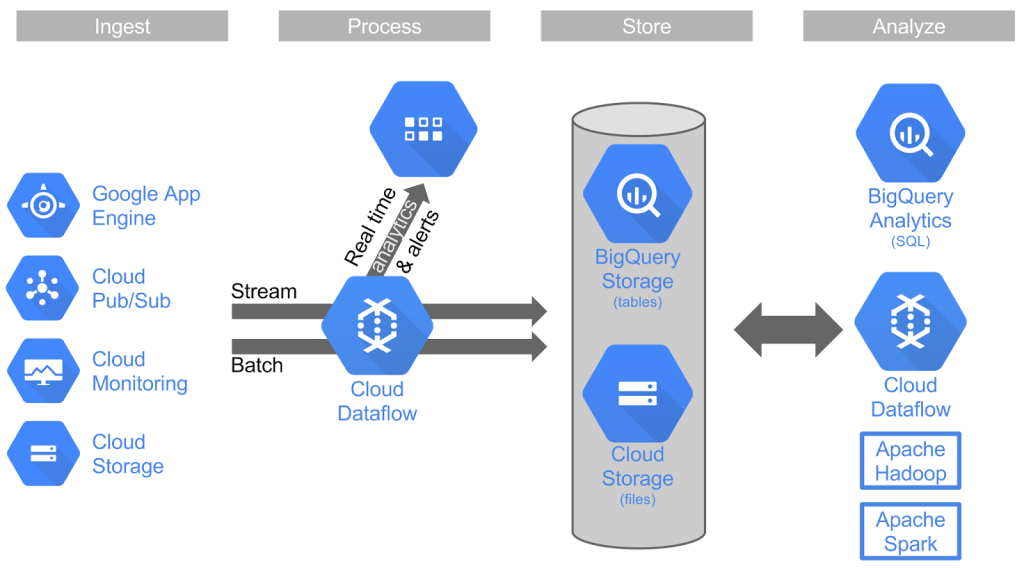
AlphaGo 完勝世界頂尖棋手的捷報下,機器學習 (Machine Learning) 儼然成為現今網路科技的顯學。機器學習涵蓋了跨領域的 know-how、演算法以及數據。其中數據又是決定機器學習品質重要的一環。Google 深耕大數據分析及應用多年,無所不能的搜尋引擎就是最好的例子。在資料提取 (data ingestion)、資料處理 (data process)、資料分析 (data analytics) 以及資料視覺化 (data virtualization) 等,Google 終將這些數據的工作流程,以 Apache Beam 技術轉化為一個一個簡單管理的元件 Dataflow,提供給 Google Cloud Platform (GCP) 的使用者使用。
GCP 中的大數據服務包含了:Cloud Pub/Sub、Cloud Dataflow、BigQuery 以及 Dataproc。其中 Cloud Pub/Sub 之於資料提取的管理;Cloud Dataflow 之於資料處理的管理;BigQuery 之於資料分析及資料倉儲 (data warehouse);Dataproc 之於整合 Hadoop 完整的生態系及 Spark。
本文從資料處理作為切入,從簡述 Cloud Dataflow 的 programming framework 源頭 – Apache Beam 談起,並將Cloud Dataflow與現今常用的幾個大數據產品:Spark、Flink 做初步的比較,好讓資料工程師、資料科學家做進一步的了解。
Apache Beam 的小歷史
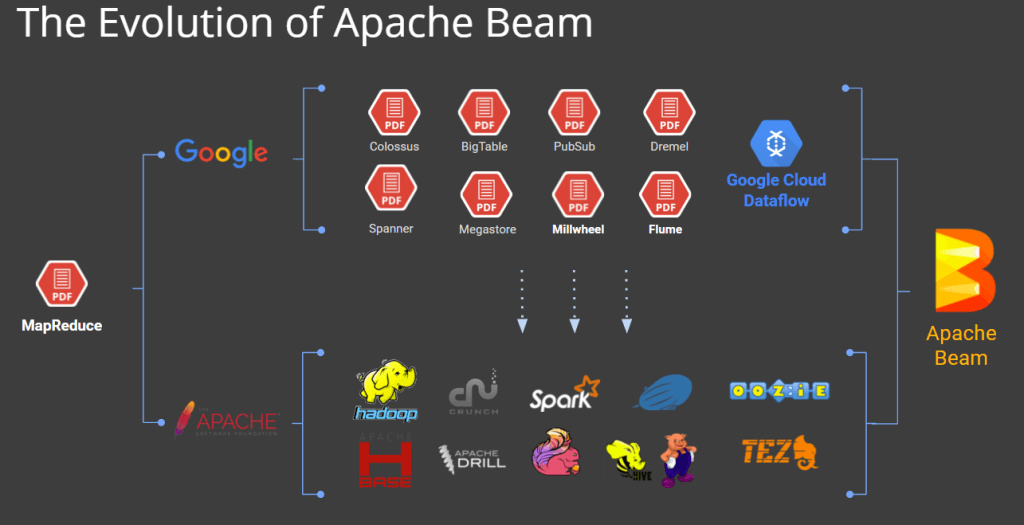
Apache Beam 是由 Google 主導的一個開源(open source)專案。2003 年 Google 發布了重要的三篇大數據的論文:Google FS、MapReduce、BigTable,震驚了資料界,也奠定了Google 在網路科技霸主的地位。但是隨後當時的 Hadoop 之父- Doug Cutting 根據這些論文發展了 Hadoop 及 MapReduce、甚至到後來處理串流資料的 Spark 等,讓 Google 決定不單貢獻於內部專案,而想親身參與、和全世界一起打造大數據平台。Apache Beam 就是因應這樣的趨勢而誕生。
Apache Beam 的主要負責人 – Tyler Akidau 於他的部落格上說明為什麼要做 Apache Beam:
要為這個世界貢獻一個易用且強大的模型,這個模型既可以掌握批次處理又可以實作串流處理,而且能在不同平台上移轉實作。當然 Google 並不滿足於此,他將這樣的技術包裝於 Cloud Dataflow 中,讓使用 Apache Beam 的使用者,也可以在 GCP 上更方便地使用。我們從(如圖一)可以發現,從 Google 原本「惦惦呷三碗公」到之後於開源世界演進出 Hadoop、Spark, Flink 等產品,也算是耐人尋味。
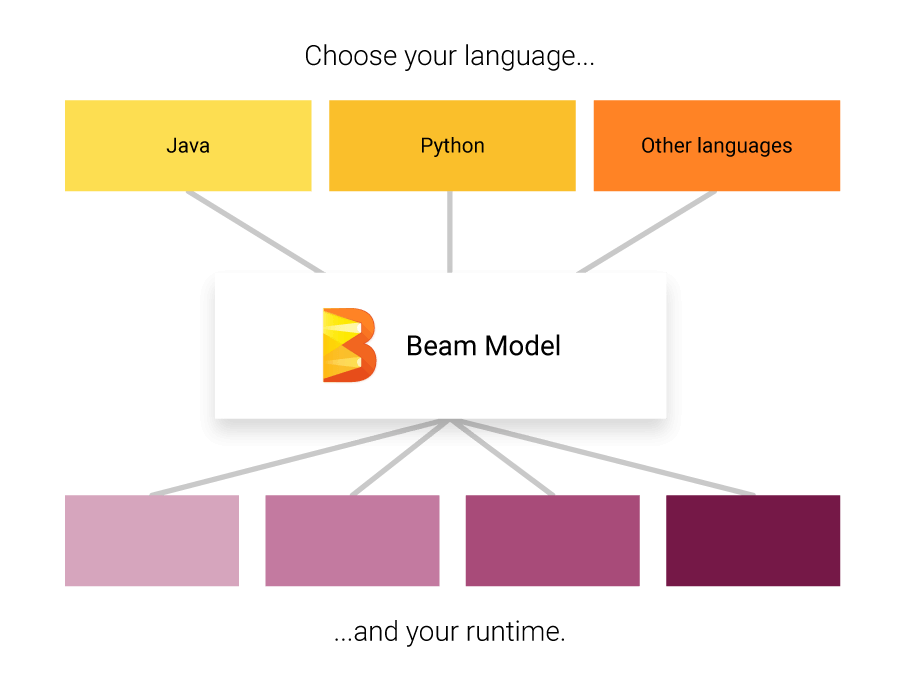
Apache Beam, The Dataflow SDK
說了這麼多,統整一下 Apache Beam 的特點:
- 統一處理 batch 資料及 streaming 資料
- 能在任何 engine 上運行
這些為數據提供了統一的模型,同時包含資料提取、資料處理、資料整合。為了整合這些實作,Apache Beam 設計了 The Dataflow SDK (如圖二),整合目前市面上的所有大數據工具,無論是想使用MapReduce做batch檔案的處理、還是使用 Spark 處理 streaming 檔案都沒有關係。因為您只需專注於撰寫好 pipeline,在最後 runtime 執行時,選擇任何一款:Flink, Spark, Pipeline, Google Cloud Dataflow 都可以。
- Pipeline 第一 ‧ Runtime 第二:您僅需要專注於 Dataflow SDK。
- 可攜性:可在跨 runtime 之間攜帶,增加擴充性。
- 統一整合的模型:batch 資料與 streaming 資料都可以使用。
- 開發者工具:都是開發者導向的工具,包含程式庫(libraries)、開源工具等。
其中 pipeline為一個資料管線,該管線由一組可以讀取輸入的數據源,轉換數據(data transformation)以及輸出結果的操作所組成。管線中的數據和變換對於該管線是唯一的,並且屬於該管線。您的程序可以創建多個管線,但這些管線不能共享數據或轉換。
因此,Tyler Akidau 又說了:「streaming 資料流處理和 batch 資料流處理的未來在於 Apache Beam,而 runtime engine 的選擇權在於使用者。」
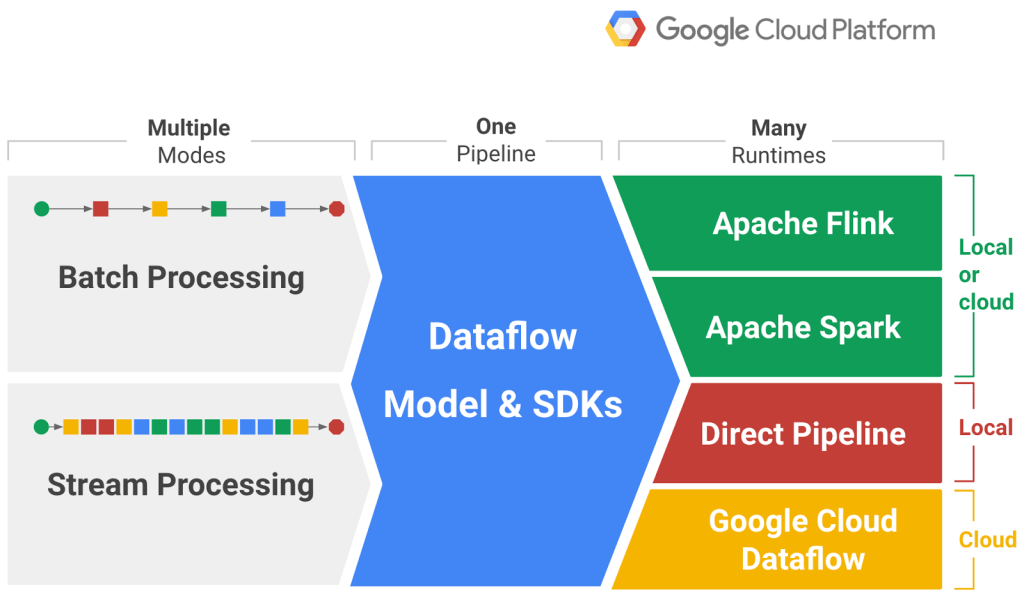
各種 Runtime 的相容能力
最後,我們來參考以下 Apache Beam 的 Skill Matrix,下圖展示了 Apache Beam pipeline 在不同 runtime 的相容能力。
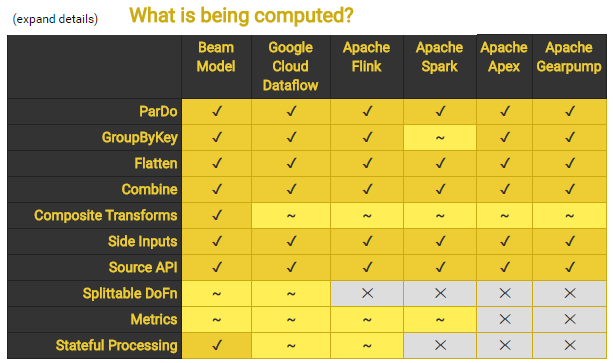
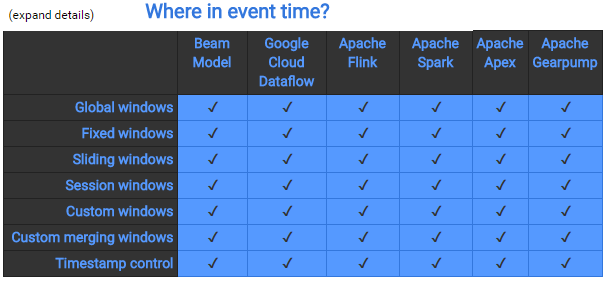
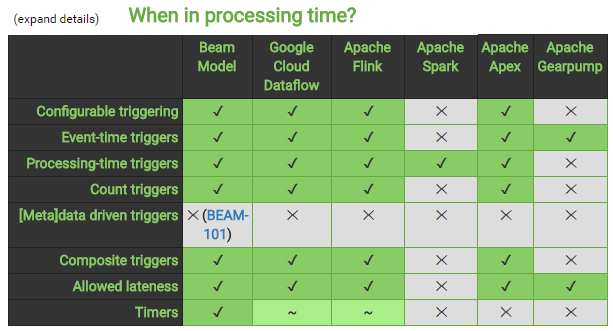

簡而言之,眾多 runtime 中,Google Cloud Dataflow 及 Flink 是真正的「streaming導向的runtime」,Spark 是「micro-batch」,是把 batch 的時間變得很短來模擬 streaming,本身其實是 batch engine。另外 Beam 對 Flink 相容最好。以上表格是比較先前的資料,另有高手指點說明,上表 Flink “~” 的部分,其實都是打勾的,有興趣的朋友可以自行測試看看。其中無論是 Cloud Dataflow、Flink、Spark 等用來做 ETL、Pipeline 都不是什麼問題。當然,您也可以選擇是否要使用 Beam 這層框架來處理。
下篇文章會專講 Google Cloud Dataflow 的功能以及整合了哪些GCP原生的產品,來迅速、有效地解決您數據相關的問題,敬請期待!
參考資料:
[2]https://cloud.google.com/blog/big-data/2016/05/why-apache-beam-a-google-perspective
[3]https://beam.apache.org/documentation/runners/capability-matrix/#cap-summary-what
閱讀更多: