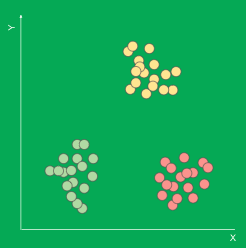
機器學習系統是如何被訓練的?(三)
在了解 AI、Machine Learning、深度學習的差異以及如何選擇正確且合適的資料後,我們來看看機器學習系統是如何被訓練的吧!
監督式學習
Machine learning program 提供了帶有標籤的訓練數據,它可以告訴系統如何對示例數據進行分類,舉例來說:
| 顏色 | 重量 | 標籤 |
| 紅色 | 200g | 蘋果 |
| 橘色 | 300g | 橘子 |
| 綠色 | 150g | 蘋果 |
這裡的每一列數據,都是由我們告訴系統:在給定兩個輸入(顏色和重量)的條件下,預期的輸出標籤應該是什麼(是蘋果?還是橘子?)。接下來,機器學習系統會依據給定的資料進行預測,以決定新的輸入(顏色和重量)代表的是蘋果或是橘子。較多研究集中在這個領域。
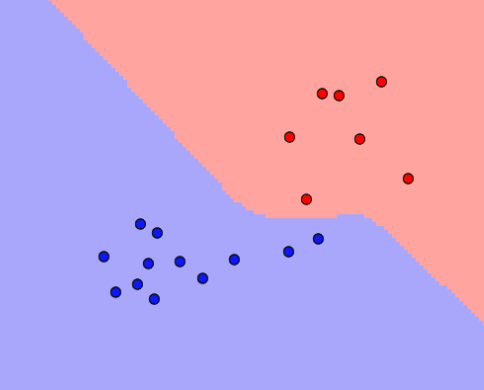
非監督式學習
機器必須從一個未標記的數據集中學習。
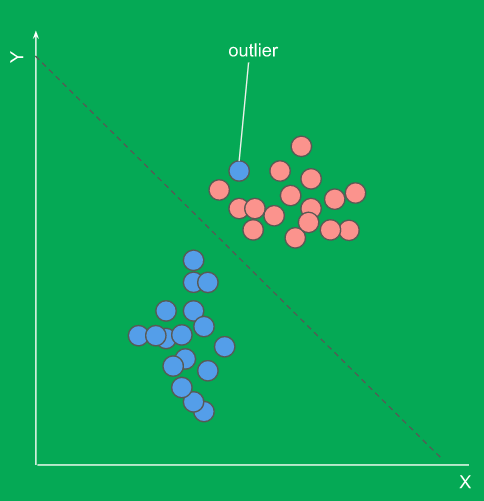
想像一下,一個圖表上有一堆點分別代表三個不同的東西,機器必須替3個不同的集群完成分類。這是非常棘手的,因為事前並不知道集群的數量,所以必須做出最好的猜測。另外,有時這些叢集不像這裡顯示的那樣清楚。
 當它失敗時,我們則不給予獎勵 (或是負面的獎勵) 。
當它失敗時,我們則不給予獎勵 (或是負面的獎勵) 。
隨著時間的推移,它會學習如何在沒有人明確地告訴它規則的情況下將報酬最大化。當它做出以前從來沒有人想過的動作時,它可以比人的表現更好。
它們是怎麼運行的?
ML 系統可以嘗試多種學習模式來提交數據給它來進行分類,我們將通過接下來幾個非常簡單的例子 (真正的 ML 系統經常使用兩個以上的維度) 帶您了解一些系統背後的概念與見解。
事實上,在頂尖的研究成果背後所使用的數學方法和理論會比這些簡單的例子還要複雜,(有時甚至會同時結合數個複雜的數學方法以達到更好的成果,不過這部分已經超過本文所探討的內容),但是透過數學來找到模型的基本原則仍是相同的。
現在聯繫 iKala Cloud,瞭解更多 GCP 加值服務!
範例一
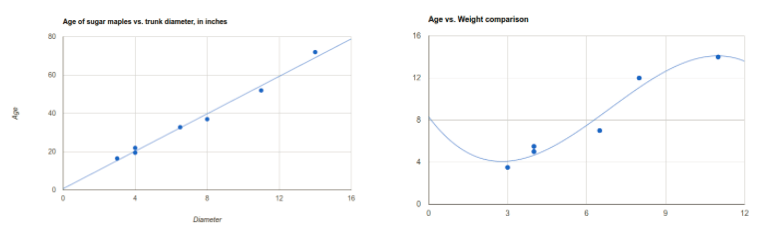
記得在高中時,你必須繪製一個X,Y圖上的點,然後繪製一條最切合的線? 這就像一個非常簡單的ML系統。在這個例子中,用你繪製的那一條線,你可以預測給定的X,可能會有什麼Y值 – 即使是未知的值,這是一種 “迴歸分析” 的形式。
ML程序靠自己來計算這些線。


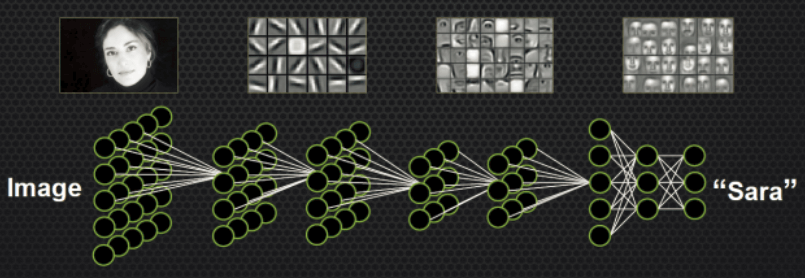
深度神經網路
深度神經網路 (DNN) 只是由輸入和輸出之間的許多 “隱藏層” 組成。 每一層都可以從中學到更高層次的學習。 這些隱藏層通常具有較低的維度,因此它們可以更好地概括,而不會過度地適應輸入數據。系統中的這些中間層可以學習功能的特徵。例如一連串的“邊緣”特徵可能會導致辨識出 “部分面容” ,最後系統可以識別出 “臉”。
連續輸出
這意味著ML系統的輸出是十進位制數,例如 8.3984。
因此給了一些輸入,你將得到一些數字的輸出。 舉例來說,假設一個橘子重200克,其半徑是4.2英寸,這裡將得到的輸出是4.2,這是ML系統嘗試預測出來的。 線性回歸試圖擬合一條直線到數據,以便您可以給定輸入 (x) 來預測某個值 (y)
分類
所有數據的類別 (或標記) 是由一組輸入所決定,而輸出為離散的。舉例來說:
輸入:頭髮,爪子,鬍鬚
輸出:貓
輸出的會是一個標籤,而不是像迴歸分析或概率估計那樣是個數字。
概率估計
這意味著ML系統的輸出是介於0到1之間的十進位制數,表示我們認為給定輸入是某個期望輸出的機率 (0.751 == 75.1%) 。舉例來說:ML系統可以預測瓶子裡有多少個白色磚塊,如果它以54.3%的概率輸出 “9”,那麼我們就可以根據這個資訊和信心指數做一些很有用的事情。
輸出的使用
一旦你以迴歸分析、概率估計、或分類的形式輸出,那麼程式設計師就可以做一些有用的事以獲取資訊。假設我們80%確定我們看到的是一隻貓,也許我們會想要餵牠。 但如果我們只有75%的把握,也許我們會等待直到我們更確定。
延伸閱讀
1. 人工智慧、機器學習、深度學習是什麼? – Machine Learning 教學系列 (一)
2. 該怎麼選擇資料,來訓練機器學習系統? – Machine Learning 教學系列(二)