集結國內外精選文章,掌握最新雲端技術新知與應用
在本教程中,您將探索一個結構化數據集,然後為機器學習 (ML) 模型創建訓練和評估數據集。 這是一系列教程中的第一部分; 您可以繼續第二部分:訓練模型和第三部分:部署 Web 應用程序。
您可以使用 Google Cloud Platform (GCP) 的 Cloud Datalab 進行數據探索,並使用 Cloud Dataflow 來創建您的數據集。作為資料來源的數據集儲存在 BigQuery 中。
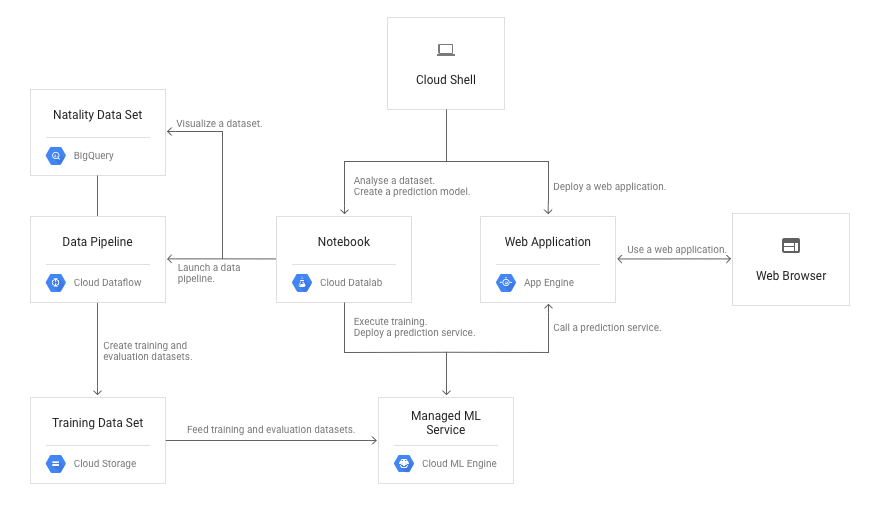
以下是教程的架構:
使用 Cloud Datalab 探索公開數據集。 執行查詢以從 Natality 數據集收集樣本數據,這是來自美國疾病控制和預防中心 (CDC) 的公開 BigQuery 數據集。 確定要在 ML 模型中使用的功能。 使用 Python 數據分析工具 Pandas 以可視化數據 (https://pandas.pydata.org/)。 Pandas 數據框是一種可用於統計計算和數據可視化的內存數據結構。 使用 Cloud Dataflow 將數據分割為訓練和分析數據文件。 使用 Cloud Dataflow 啟動預處理管道來創建訓練和評估數據集。 架構 本教程使用結構顯示於下圖中虛線內: 費用 本教程使用 Cloud Platform 的收費組件包括: Compute Engine Persistent Disk Cloud Dataflow Cloud Storage BigQuery 根據這個定價計算器,假定您一整天使用每個資源,運行這部分教程的估算價格約為 1.45 美元。 在開始之前 1. 選擇或創建一個雲端平台項目。 進入管理資源頁面 2. 為您的專案啟用計費功能。 啟用計費功能 3. 啟用 BigQuery、Cloud ML Engine、Cloud Source Repositories、Cloud Dataflow 和 Cloud Datalab API。 啟用 API 啟動 Cloud Datalab 按照以下步驟創建一個 Cloud Datalab 執行個體: 1. 打開 Cloud Shell。 除非另有說明,否則您將從 Cloud Shell 內執行本教程的其餘部分。 打開 Cloud Shell 2. 運行以下命令來獲取您的項目 ID。 請記下它,以便於本教程的後面使用。 gcloud config list project --format "value(core.project)" 3. 創建一個 Cloud Datalab 執行個體。 datalab create --zone us-central1-a mydatalab 創建執行個體可能需要一分鐘或更多時間。 創建執行個體後,Cloud Datalab 將顯示以下輸出。 The connection to Datalab is now open and will remain until this command is killed. Click on the Web Preview (up-arrow button at top-left), select port 8081, and start using Datalab. 注意:為確保下次要使用相同的執行個體,請執行 datalab connect mydatalab 4. 點擊 Cloud Shell 中的 Cloud Shell Web preview 以啟動 Cloud Datalab 筆記本列表頁面。 5. 選擇更改連接阜 (port),然後點擊 Port 8081 以打開瀏覽器新分頁。 複製 Cloud Datalab 筆記本 現在您已擁有 Cloud Datalab 實體,請下載本教程的 Cloud Datalab 筆記本文件。 1. 在 Cloud Datalab 中,單擊左上角的 +Notebook 圖案創建一個新筆記本。 筆記本會在新分頁中打開。 2. 將下面的命令複製並在新筆記本的第一個單元格中貼上。 !git clone https://github.com/GoogleCloudPlatform/training-data-analyst 3. 單擊頁面頂部的 Run 以下載本教程的筆記本。 4. 在 Cloud Datalab 中,打開筆記本。 training-data-analyst/blogs/babyweight/babyweight.ipynb 5. 在下拉選單中的 Clear,單擊 Clear all Cells。這是筆記本的前四個單元格: 6. 按步驟填寫單元格: 在第一個單元格中,將變數 PROJECT 設定為您的項目 ID 在第一個單元格中將變數 BUCKET 設定為您的 Bucket 名稱。 對於您的 Bucket 名稱,請使用您的項目 ID 的前綴和 my-bucket: project-ID-my-bucket 將 REGION 保留為 us-central1 7. 選擇第一個單元格後,單擊 Run 以在第一個單元格中執行程式碼。 重複接下來的三個單元格。 8. 跑完上述的四格單元格後,再到最前面的單元加入以下的指令並點選 Run 來安裝必備的套件,如圖: pip install pip==9.0.3 本筆記本包含有關創建 ML 模型的端到端流程中所有步驟的詳細信息。本節提供筆記本第一部分的概述和背景。 探索公共 Natality 數據集 您可以使用公共 Natality 數據集創建一個 ML 模型,根據孕期和母親的許多因素預測寶寶的體重。 要訓練模型,您必須要探索數據集和了解其結構,並檢查數據中的關係。 然後在數據中分離並構建相關特徵。特徵是影響您的模型預測的信息。特徵可以是源數據集中的數據字段,也可以使用一個或多個原始字段形成特徵。識別您的模型的相關特徵稱為特徵工程。 您還必須轉換,合併和提取數據以對其進行格式化以訓練模型。 這被稱為數據預處理。 在功能工程和預處理過程中: 選擇您想要預測內容的相關功能。 將數據轉換為適合訓練的格式。 將數據分成訓練集和評估集 (也稱為測試集)。 查詢數據 首先查詢數據並查看一些樣本。使用筆記本的“探索數據”部分中的前兩個單元格,對BigQuery 表格運行查詢並將結果儲存在 Pandas 數據框中。 使用雜湊值拆分數據 您使用雜湊值分割數據以確保: 您可以為訓練和評估集使用相同的源數據子集。 如果設定不一致,則不能可靠地比較評估結果,以及您的訓練調整是不精確的。 您可以避免評估集中的數據歪斜。 hashmonth字段是根據 BigQuery 表格中每條記錄的年份和月份列計算的雜湊值。 從表中收集年份和月份列時,可7以使用 FARM_FINGERPRINT 函數添加此列: FARM_FINGERPRINT(CONCAT(CAST(YEAR AS STRING), CAST(month AS STRING))) AS hashmonth Cloud Dataflow 使用以下 Python 程式碼片段來創建分割。您為評估集指定了四分之一的數據。您使用「將雜湊除以 4 的餘數」(使用函數 modulo) 來定義兩個數據集。 for step in ['train', 'eval']: if step == 'train': selquery = 'SELECT * FROM ({}) WHERE MOD(ABS(hashmonth),4) < 3'.format(query) else: selquery = 'SELECT * FROM ({}) WHERE MOD(ABS(hashmonth),4) = 3'.format(query) 使用這種技巧可以確保您獲得每個數據集中源數據的隨機採樣,這比不使用隨機化的數據劃分更好,因為它可以降低意外偏差評估集的風險。 例如,如果您為評估集指定排序的最高四分之一,則可以選擇其餘數據中不存在的特徵的數據。確保評估集,表示數據的一般特徵,以便評估訓練過的模型的一般化性能,這一點非常重要。 確定訓練功能有效 接下來,您可以確定哪些功能會影響您想要預測的值:寶寶的體重。 檢查源數據中的列,檢查在源數據中的縱列,以確定每一行縱列和所述目標之間是否存在關聯。 使用 Cloud Datalab 的互動式筆記本執行此步驟可快速查看每個關係,如示例筆記本中所示。強烈的相關性表現可以解釋為數學函數的線條,如線性或二次方程。 在此解決方案,您可以使用以下列中進行預測: is_male, mother_age, plurality, gestation_weeks 因為嬰兒體重可能存在歷史趨勢,請限制按年代順序排列的數據。 使用舊數據進行訓練可能會降低模型預測未來出生嬰兒體重的準確性。 但是,您不應該僅限於去年的數據,因為結果數據集太小。 在筆記本中繪製條形圖的函數是 get_distinct_values。 此功能僅收集 BigQuery 表中在 2001 年後的數據。 2001 年的門檻值是任意的。 但是,為了平衡兩個因素,您可能會試驗這些數值 (而非參數):「對新數據的需求」和「足夠的數據來實現良好模型性能的需求」。 您在獲取新數據時更新模型,以便模型反映最新趨勢。 使用 Cloud Dataflow 創建 ML 數據集 接下來,您會使用 Cloud Dataflow 來提取數據。 您指定的縱行將從 BigQuery 中移出並儲存在 Cloud Storage bucket 中的 CSV 文件中。 您可以使用 hashmonth 將數據集分成訓練集和評估集,並將其儲存在單獨的文件中。您將使用這些文件來訓練您的 ML 模型。 產生合成數據 您可以使用 Cloud Dataflow 產生合成數據,令模型更通用以應付部分或未知輸入值。 例如,在歷史數據集中,數據集中的每一行都包含嬰兒的性別,因為嬰兒出生後就知道該性別。 但是,您正在建立一個模型來預測寶寶出生前的體重。只有在懷孕期間進行超聲波檢查時,才知道嬰兒的性別。 如果沒有進行超音波檢查,醫生會以 Unknown 的形式輸入嬰兒的性別。 但是歷史數據集中的性別列沒有 Unknown 值。您可以通過將每個歷史數據點寫入兩次,一次使用 is_male 列的原始值 (True或 False) 並將 is_male列值替換為 Unknown來產生人造數據。 此外,很難對沒有超聲波的嬰兒數量進行計數,因此,當醫生可以判斷是否有一個嬰兒或多個嬰兒時,他們不能區分雙胞胎和三胞胎。 在寫出數據以模擬沒有超聲波時,可以用字符串值 (Single 或 Multiple) 替換多個數字。 提交數據處理作業 在筆記簿中,請到 Creating a ML dataset using Dataflow 的第一個單元格,包含用 Apache Beam SDK 編寫的數據處理程式碼,按下 Run。當您執行 cell 時,將數據處理作業提交給 Cloud Dataflow。您會在最下方得到警告訊息,可以安心略過。 查找正在運行的作業 您可以使用 Google Clous Platform 控制台中的 Cloud Dataflow 頁面尋找正在運行的作業。 打開Cloud Dataflow 您會發現兩條管道,一條包含訓練集,另一條包含評估集。 該過程通常需要大約30分鐘才能完成,但可能會因設定而異。 下圖顯示了 Cloud Dataflow 數據處理管道: 查找用於評估和訓練的 CSV 文件 執行完 Dataflow job 之後,這項 job 將會創造了兩組多個 CSV 文件。以下是評估集和訓練集的第一個 CSV 文件: gs://${BUCKET}/babyweight/preproc/eval.csv-00000-of-00016 gs://${BUCKET}/babyweight/preproc/train.csv-00000-of-00040 查看 CSV 文件 使用 Google Cloud Platform 控制台中的 Cloud Storage 頁面查看 bucket 中的 babyweight/preproc 目錄中的整個文件集。打開 Cloud Storage 訓練和評估集 使用訓練集訓練 ML 模型,評估集評估訓練模型的預測精度。 在一般情況下,訓練模型是用於訓練集比評估組更準確。如果評估集的準確度遠遠低於訓練集的準確度,那麼該模型會出現過度擬合。 過度擬合模型不能很好地預測新數據。 換句話說,訓練模型的預測不能推廣到新數據。 您必須使用未用於訓練的評估集評估模型一般化之後的效能。在本系列的第 2 部分中,您使用高階 TensorFlow 界面的 Estimator API 來自動執行此評估過程。 清理資源 如果您打算繼續本教程系列的第 2 部分,請保持您在此步驟中創建的資源不變。 否則,為避免繼續收費,請轉到 Google Developers Console Project List,選擇您為此實驗室創建的項目並刪除它。 接下來是什麼? 繼續閱讀第 2 部分「訓練模型」,該模型會使用本教程的部分,並介紹如何使用 TensorFlow 開發 ML 模型以預測嬰兒的出生體重和使用 Cloud ML Engine 訓練模型。 它還向您展示如何將訓練過的模型部署為 API 服務。 訪問公開資料集以查找可用於構建 ML 模型的其他公開資料集。 嘗試以下相關教程: 用金融時間序列數據進行機器學習 在 Cloud ML Engine 和 Cloud Datalab 中使用分佈式 TensorFlow 在計算引擎上運行分佈式 TensorFlow 嘗試其他 Google Cloud Platform 功能。 看看我們的教程。 延伸閱讀: 機器學習與結構化數據 (2):訓練模型 (原文翻譯自 Google Cloud。)
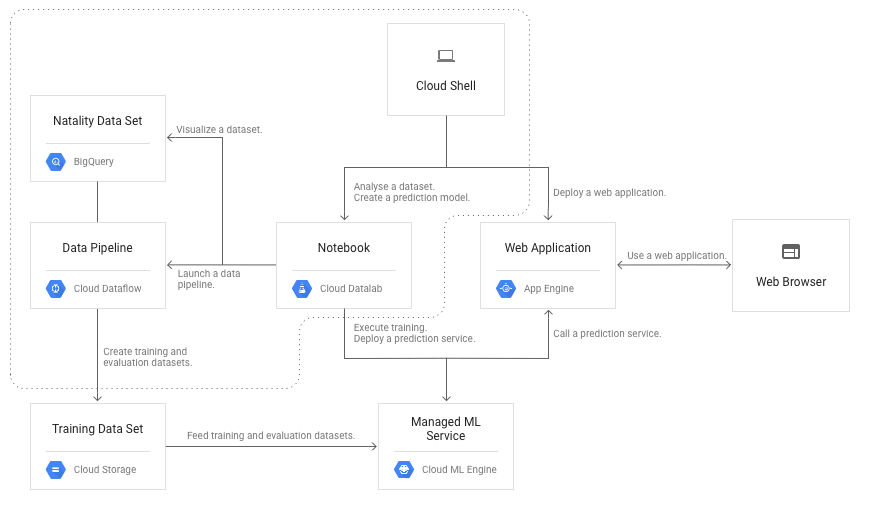
本教程使用結構顯示於下圖中虛線內:
本教程使用 Cloud Platform 的收費組件包括:
根據這個定價計算器,假定您一整天使用每個資源,運行這部分教程的估算價格約為 1.45 美元。
1. 選擇或創建一個雲端平台項目。 進入管理資源頁面
2. 為您的專案啟用計費功能。 啟用計費功能
3. 啟用 BigQuery、Cloud ML Engine、Cloud Source Repositories、Cloud Dataflow 和 Cloud Datalab API。 啟用 API
按照以下步驟創建一個 Cloud Datalab 執行個體: 1. 打開 Cloud Shell。 除非另有說明,否則您將從 Cloud Shell 內執行本教程的其餘部分。 打開 Cloud Shell
2. 運行以下命令來獲取您的項目 ID。 請記下它,以便於本教程的後面使用。
gcloud config list project --format "value(core.project)"
3. 創建一個 Cloud Datalab 執行個體。
datalab create --zone us-central1-a mydatalab
創建執行個體可能需要一分鐘或更多時間。 創建執行個體後,Cloud Datalab 將顯示以下輸出。
The connection to Datalab is now open and will remain until this command is killed. Click on the Web Preview (up-arrow button at top-left), select port 8081, and start using Datalab.
注意:為確保下次要使用相同的執行個體,請執行 datalab connect mydatalab 4. 點擊 Cloud Shell 中的 Cloud Shell Web preview 以啟動 Cloud Datalab 筆記本列表頁面。
5. 選擇更改連接阜 (port),然後點擊 Port 8081 以打開瀏覽器新分頁。
現在您已擁有 Cloud Datalab 實體,請下載本教程的 Cloud Datalab 筆記本文件。
1. 在 Cloud Datalab 中,單擊左上角的 +Notebook 圖案創建一個新筆記本。 筆記本會在新分頁中打開。
2. 將下面的命令複製並在新筆記本的第一個單元格中貼上。
!git clone https://github.com/GoogleCloudPlatform/training-data-analyst
3. 單擊頁面頂部的 Run 以下載本教程的筆記本。 4. 在 Cloud Datalab 中,打開筆記本。
training-data-analyst/blogs/babyweight/babyweight.ipynb
5. 在下拉選單中的 Clear,單擊 Clear all Cells。這是筆記本的前四個單元格:
6. 按步驟填寫單元格:
my-bucket: project-ID-my-bucket
7. 選擇第一個單元格後,單擊 Run 以在第一個單元格中執行程式碼。 重複接下來的三個單元格。
8. 跑完上述的四格單元格後,再到最前面的單元加入以下的指令並點選 Run 來安裝必備的套件,如圖:
pip install pip==9.0.3
本筆記本包含有關創建 ML 模型的端到端流程中所有步驟的詳細信息。本節提供筆記本第一部分的概述和背景。
您可以使用公共 Natality 數據集創建一個 ML 模型,根據孕期和母親的許多因素預測寶寶的體重。
要訓練模型,您必須要探索數據集和了解其結構,並檢查數據中的關係。 然後在數據中分離並構建相關特徵。特徵是影響您的模型預測的信息。特徵可以是源數據集中的數據字段,也可以使用一個或多個原始字段形成特徵。識別您的模型的相關特徵稱為特徵工程。
您還必須轉換,合併和提取數據以對其進行格式化以訓練模型。 這被稱為數據預處理。
在功能工程和預處理過程中:
首先查詢數據並查看一些樣本。使用筆記本的“探索數據”部分中的前兩個單元格,對BigQuery 表格運行查詢並將結果儲存在 Pandas 數據框中。
您使用雜湊值分割數據以確保:
hashmonth字段是根據 BigQuery 表格中每條記錄的年份和月份列計算的雜湊值。 從表中收集年份和月份列時,可7以使用 FARM_FINGERPRINT 函數添加此列:
FARM_FINGERPRINT(CONCAT(CAST(YEAR AS STRING), CAST(month AS STRING))) AS hashmonth
Cloud Dataflow 使用以下 Python 程式碼片段來創建分割。您為評估集指定了四分之一的數據。您使用「將雜湊除以 4 的餘數」(使用函數 modulo) 來定義兩個數據集。
for step in ['train', 'eval']: if step == 'train': selquery = 'SELECT * FROM ({}) WHERE MOD(ABS(hashmonth),4) < 3'.format(query) else: selquery = 'SELECT * FROM ({}) WHERE MOD(ABS(hashmonth),4) = 3'.format(query)
使用這種技巧可以確保您獲得每個數據集中源數據的隨機採樣,這比不使用隨機化的數據劃分更好,因為它可以降低意外偏差評估集的風險。
例如,如果您為評估集指定排序的最高四分之一,則可以選擇其餘數據中不存在的特徵的數據。確保評估集,表示數據的一般特徵,以便評估訓練過的模型的一般化性能,這一點非常重要。
接下來,您可以確定哪些功能會影響您想要預測的值:寶寶的體重。 檢查源數據中的列,檢查在源數據中的縱列,以確定每一行縱列和所述目標之間是否存在關聯。
使用 Cloud Datalab 的互動式筆記本執行此步驟可快速查看每個關係,如示例筆記本中所示。強烈的相關性表現可以解釋為數學函數的線條,如線性或二次方程。
在此解決方案,您可以使用以下列中進行預測:
is_male, mother_age, plurality, gestation_weeks
因為嬰兒體重可能存在歷史趨勢,請限制按年代順序排列的數據。 使用舊數據進行訓練可能會降低模型預測未來出生嬰兒體重的準確性。 但是,您不應該僅限於去年的數據,因為結果數據集太小。
在筆記本中繪製條形圖的函數是 get_distinct_values。 此功能僅收集 BigQuery 表中在 2001 年後的數據。
2001 年的門檻值是任意的。 但是,為了平衡兩個因素,您可能會試驗這些數值 (而非參數):「對新數據的需求」和「足夠的數據來實現良好模型性能的需求」。
您在獲取新數據時更新模型,以便模型反映最新趨勢。
接下來,您會使用 Cloud Dataflow 來提取數據。 您指定的縱行將從 BigQuery 中移出並儲存在 Cloud Storage bucket 中的 CSV 文件中。
您可以使用 hashmonth 將數據集分成訓練集和評估集,並將其儲存在單獨的文件中。您將使用這些文件來訓練您的 ML 模型。
您可以使用 Cloud Dataflow 產生合成數據,令模型更通用以應付部分或未知輸入值。
例如,在歷史數據集中,數據集中的每一行都包含嬰兒的性別,因為嬰兒出生後就知道該性別。 但是,您正在建立一個模型來預測寶寶出生前的體重。只有在懷孕期間進行超聲波檢查時,才知道嬰兒的性別。 如果沒有進行超音波檢查,醫生會以 Unknown 的形式輸入嬰兒的性別。 但是歷史數據集中的性別列沒有 Unknown 值。您可以通過將每個歷史數據點寫入兩次,一次使用 is_male 列的原始值 (True或 False) 並將 is_male列值替換為 Unknown來產生人造數據。
此外,很難對沒有超聲波的嬰兒數量進行計數,因此,當醫生可以判斷是否有一個嬰兒或多個嬰兒時,他們不能區分雙胞胎和三胞胎。 在寫出數據以模擬沒有超聲波時,可以用字符串值 (Single 或 Multiple) 替換多個數字。
在筆記簿中,請到 Creating a ML dataset using Dataflow 的第一個單元格,包含用 Apache Beam SDK 編寫的數據處理程式碼,按下 Run。當您執行 cell 時,將數據處理作業提交給 Cloud Dataflow。您會在最下方得到警告訊息,可以安心略過。
您可以使用 Google Clous Platform 控制台中的 Cloud Dataflow 頁面尋找正在運行的作業。 打開Cloud Dataflow
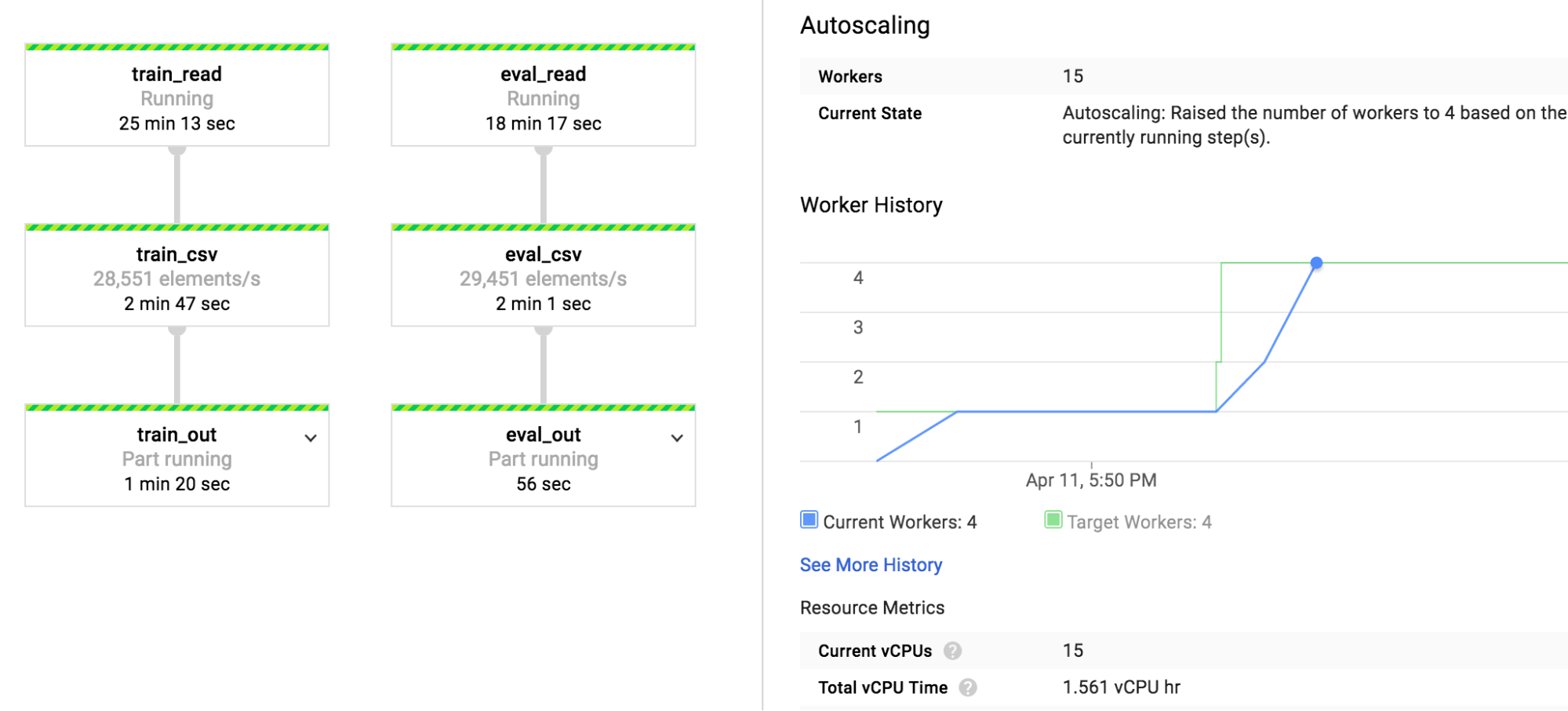
您會發現兩條管道,一條包含訓練集,另一條包含評估集。 該過程通常需要大約30分鐘才能完成,但可能會因設定而異。 下圖顯示了 Cloud Dataflow 數據處理管道:
執行完 Dataflow job 之後,這項 job 將會創造了兩組多個 CSV 文件。以下是評估集和訓練集的第一個 CSV 文件:
gs://${BUCKET}/babyweight/preproc/eval.csv-00000-of-00016 gs://${BUCKET}/babyweight/preproc/train.csv-00000-of-00040
使用 Google Cloud Platform 控制台中的 Cloud Storage 頁面查看 bucket 中的 babyweight/preproc 目錄中的整個文件集。打開 Cloud Storage
使用訓練集訓練 ML 模型,評估集評估訓練模型的預測精度。
在一般情況下,訓練模型是用於訓練集比評估組更準確。如果評估集的準確度遠遠低於訓練集的準確度,那麼該模型會出現過度擬合。
過度擬合模型不能很好地預測新數據。 換句話說,訓練模型的預測不能推廣到新數據。 您必須使用未用於訓練的評估集評估模型一般化之後的效能。在本系列的第 2 部分中,您使用高階 TensorFlow 界面的 Estimator API 來自動執行此評估過程。
如果您打算繼續本教程系列的第 2 部分,請保持您在此步驟中創建的資源不變。 否則,為避免繼續收費,請轉到 Google Developers Console Project List,選擇您為此實驗室創建的項目並刪除它。
機器學習與結構化數據 (2):訓練模型
(原文翻譯自 Google Cloud。)