
目前,大多數企業選擇使用 Apache Spark 作為資料工程、資料探勘和機器學習使用的工具,是因為它的速度、簡易性和程式語言靈活性。然而,管理叢集和調整資源架構的效率極差,而且缺乏針對不同使用案例的整合經驗,正大幅消耗生產力、增加了管理風險並降低了企業能透過 Spark 所實現的潛在價值。
今天,我們推出了 Serverless Spark ,一般可用(general availability)版,這是業界第一個自動規模化的無伺服器 Spark。我們也推出透過 BigQuery 的無伺服器 Spark 非公開預覽功能,讓 BigQuery 使用者能使用無伺服器 Spark 以及 BigQuery SQL 進行資料分析,使用者能更容易地運作大規模 ETL、資料科學、和資料分析使用案例。
Spark 的 Dataproc 無伺服器(Dataproc Serverless)成為一般可用(GA)
根據 IDC,開發人員花費40%的時間編寫程式、以及60%的時間調整資源架構和管理叢集。此外,並非所有 Spark 開發人員都是資源架構專家,導致了更高的成本、並且影響生產力。
- 開發人員能夠專注於程式碼和邏輯。他們不需要管理叢集或調整資源架構。他們於 UI 介面上提交 Spark 作業,而過程所需資源則會自動規模化。
- 資料工程團隊不需要為終端使用者管理和監控資源架構。他們便會有更多時間進行具有更高價值的資料工程職能。
- 只為作業時間付費,而非為資源架構時間付費。
OpenX如何運用Serverless Spark:從大量繁重的叢集管理到無伺服器
OpenX(發行商和需求夥伴的最大獨立廣告交易平台)正在轉移舊的MapReduce pipeline。先前的 MapReduce 叢集在眾多工作之間被共享,這需要頻繁的叢集大小更新、自動規模化、並且由於升級以及其他無法回復的原因,不時需要重建叢集。
OpenX 使用 Google Cloud 的無伺服器 Spark 來將重心專注於作業本身,而非叢及資源管理,大幅幫助提高了團隊的生產力,同時減低了管理資源架構的成本。事實證明,對於 OpenX ,從資源的角度來看,無伺服器 Spark 更加便宜,更不用說叢集生命週期管理的維護成本。
在實施過程中,OpenX 首先評估了現有管道(pipeline)特性。它每小時批次工作量的輸入大小從每小時 1.7 TB 到 2.8 TB 不等的 Avro 壓縮檔。管道與其他作業一起在共享叢集上運行,而不需要資料隨機重新排序。
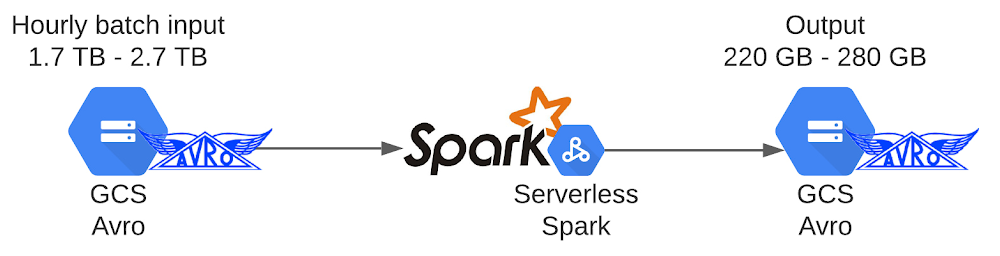
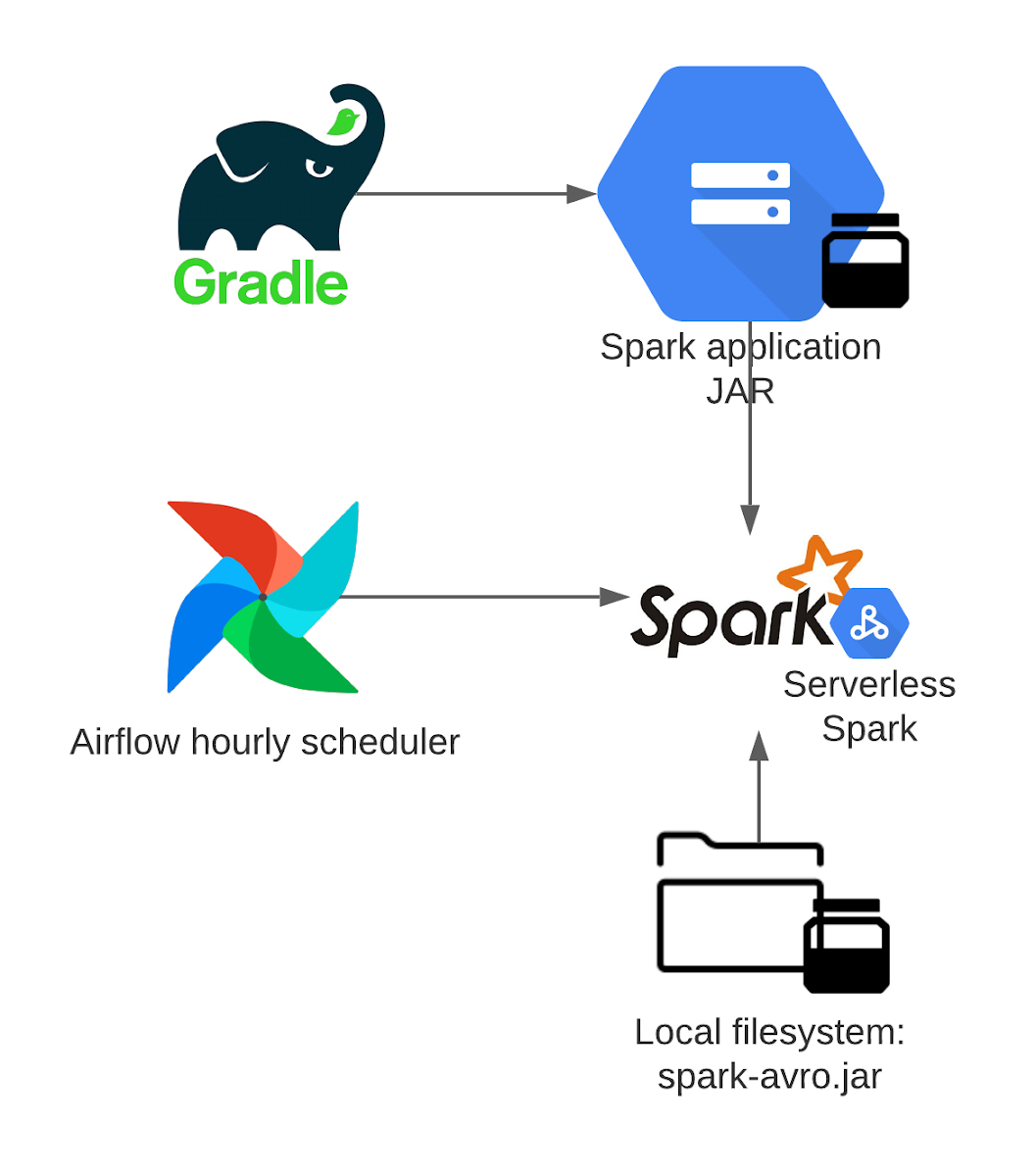
為了設置流程,會分配一個工作負載身份(workload identity)給 Airflow Kubernetes 工作人員,使用 Airflow 的外掛程式 DataprocCreateBatchOperator 將工作提交給 Dataproc 無伺服器批次服務。批次處理作業本身會被指派到一個特製的服務帳戶,並且使用 gradle 外掛程式,將 Spark 應用程式 jar 發送到 Google Cloud Storage,因為 Dataproc 批次處理可以直接從那裡載入一個 jar。另一個作業相依關係(Spark-Avro)是從驅動程式或工作檔案系統載入。然後以100個執行程式(1vCPU + 4GB RAM)的原始大小啟動批次處理作業,而自動規模化控制器會添加所需資源,因為一天中每小時的資料量大小有所不同。
透過 BigQuery 實作無伺服器 Spark 服務(預覽版)
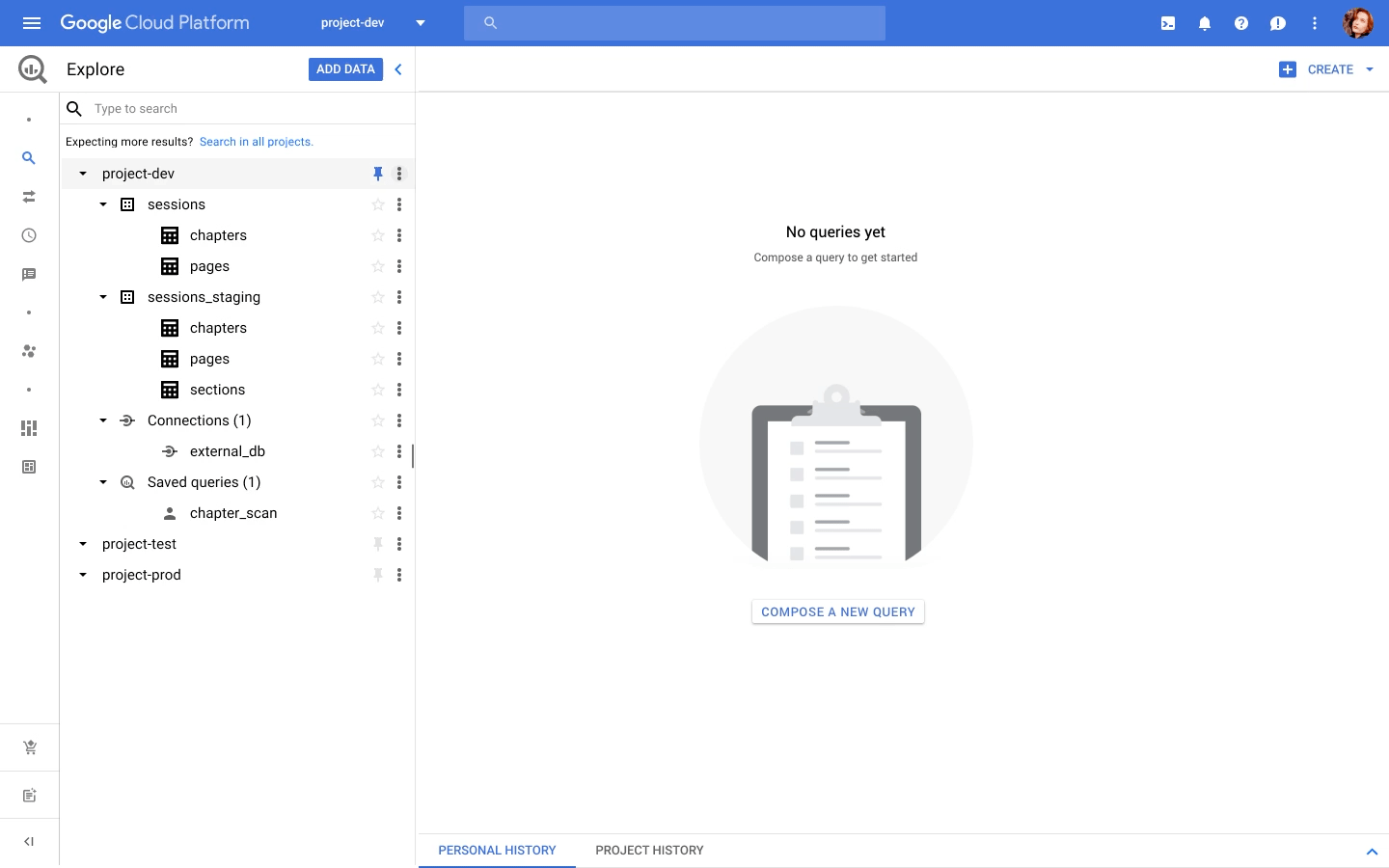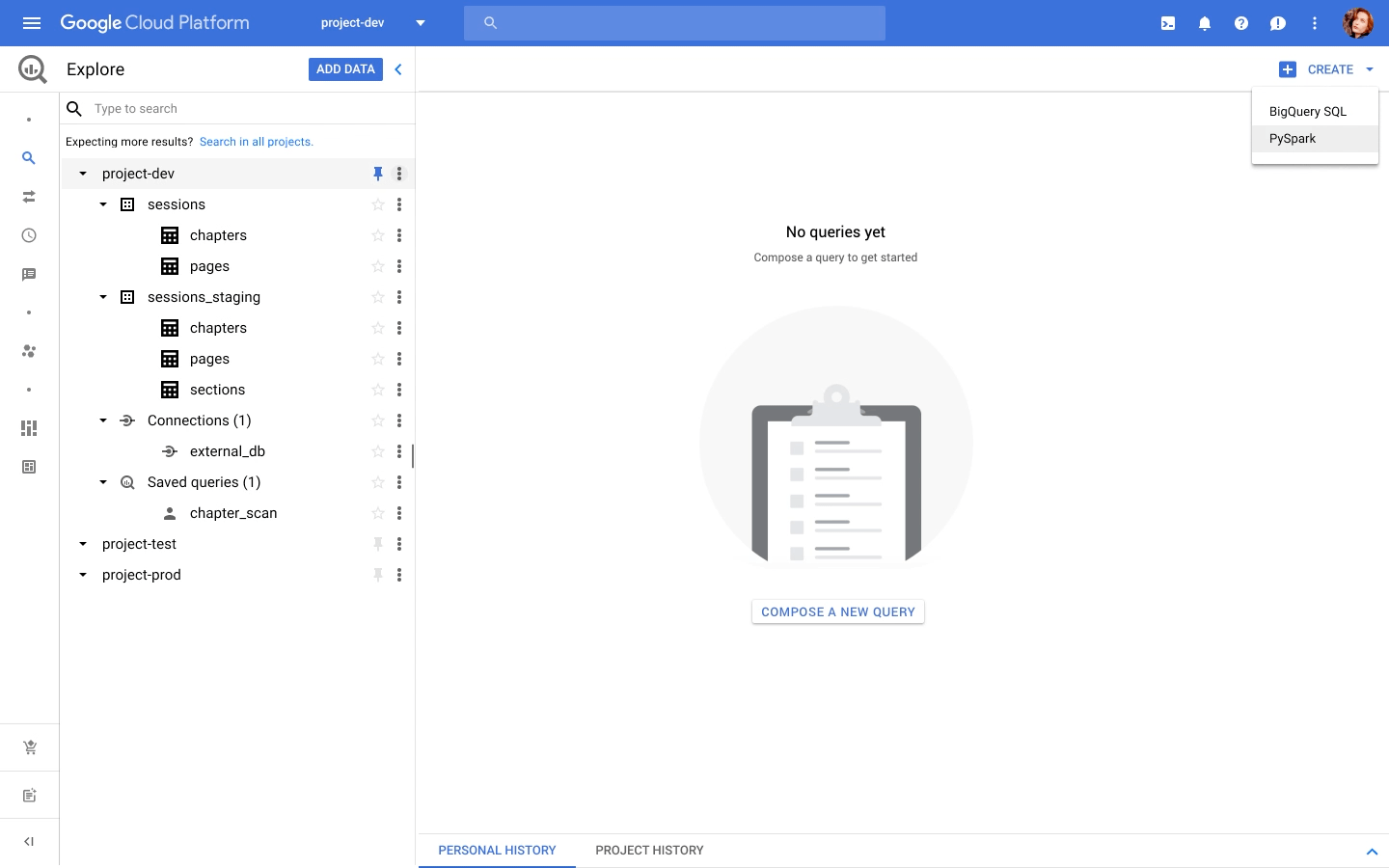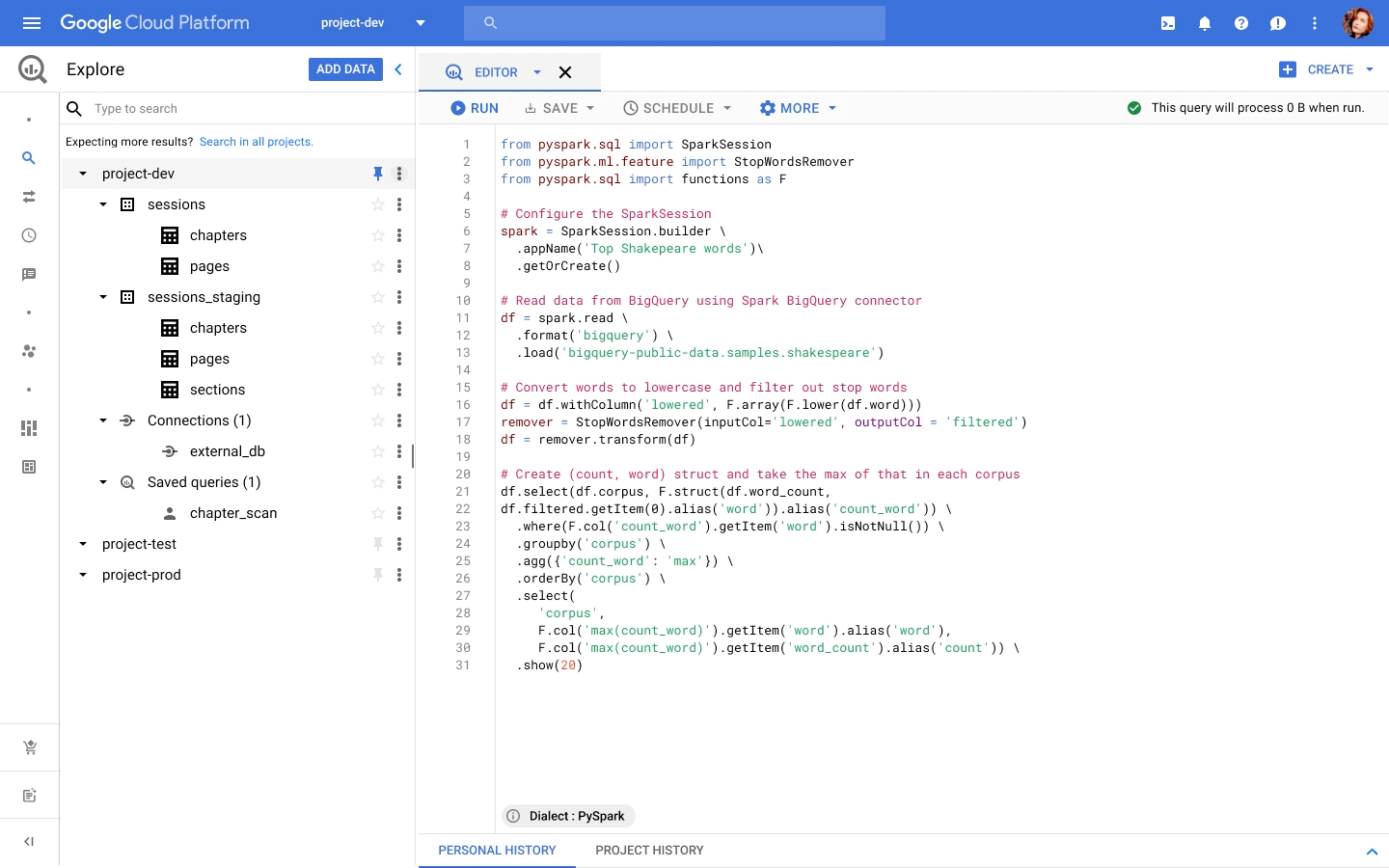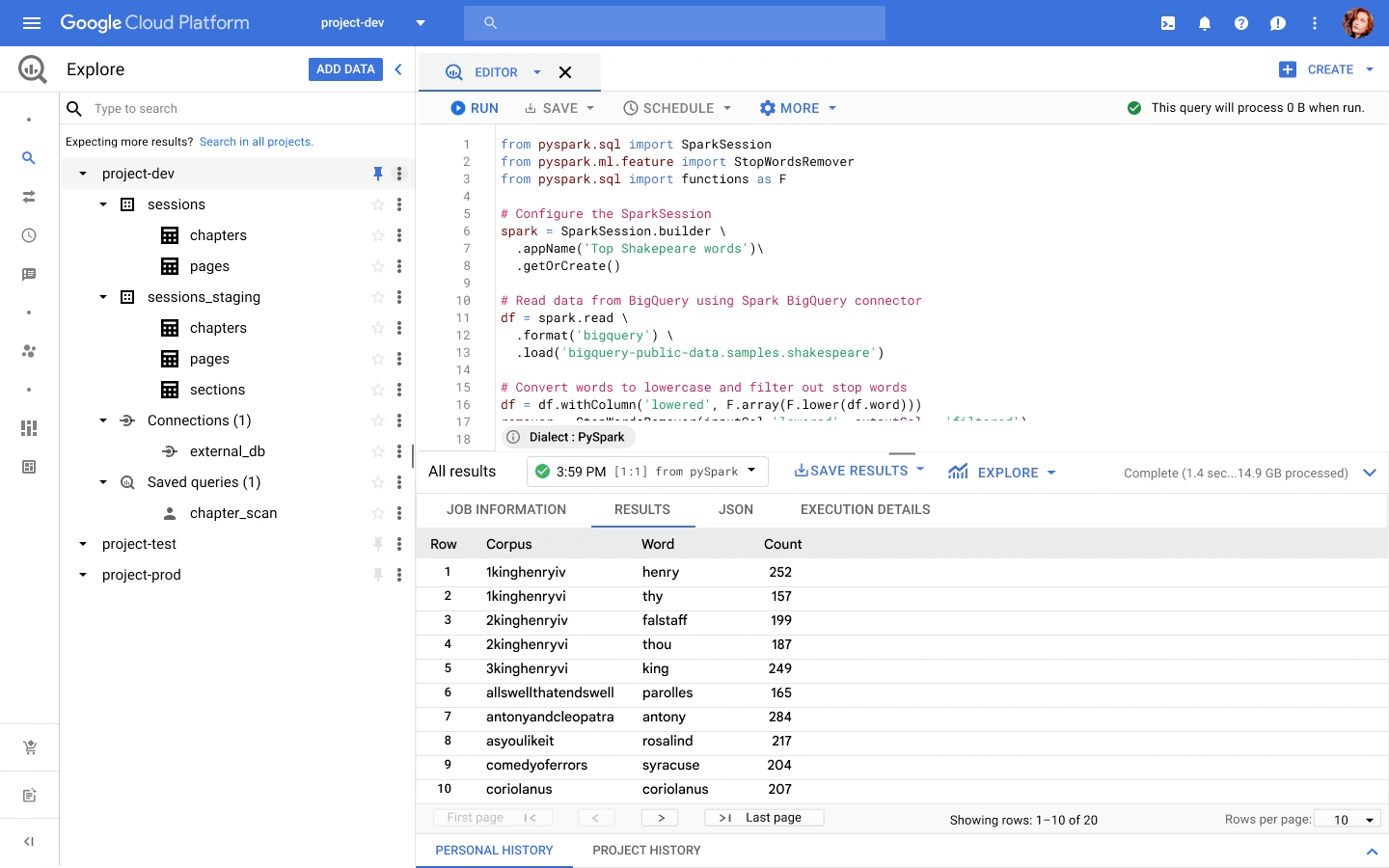
我們在 NEXT 上宣佈 BigQuery 新增一個統一的接口以編寫SQL 或 PySpark。目前預覽版本已經上線,您可以透過註冊表單做申請。
您可以在 BigQuery 編輯器中撰寫 PySpark 程式,並使用無伺服器 Spark 服務即時執行代碼,而無需配置資源架構。 BigQuery 一直是無服務器數據倉庫的先驅,現在支援無伺服器 Spark 服務針對 Spark 做分析。
下一步是什麼?
我們正在將無伺服器 Spark 服務與不同用戶使用的界面進行整合,以便在沒有任何前期資源架構的情況下啟用 Spark。在未來的幾個月中,透過 Vertex AI workbench 平台替資料科學家提供無伺服器 Spark 服務,並為數據分析師提供 Dataplex 平台。您可以使用相同的註冊表單註冊表達關注。
立即透過 BigQuery 開始使用 Serverless Spark 和 Spark
您可以使用此教學學習無伺服器Spark服務,或使用其中一個模板執行常見的 ETL 任務。 要通過 BigQuery 預覽版註冊 Spark,請使用此表單。