機器學習技術快速演進,現在資料科學家已經能用更加精準的模型來處理各種難解的問題。然而,模型的複雜度與精準度直接相關,而這樣的複雜度又會使得調整模型更具挑戰性。為了解決這項挑戰,Google Cloud 於 2019 年 11 月推出 Explainable AI;此工具旨在幫助資料科學家除錯、改善模型效果並提供 insights,讓資料科學家使用上更方便。
了解模型如何運作,對有效且適當地導入 AI 來說相當重要。本篇文章將詳細介紹如何在 AutoML Tables 及 Cloud AI 平台 (Cloud AI Platform) 上將 Explainable AI 與表格式資料 (tabular data) 一起使用。
什麼是 Explainable AI?
Explainable AI 是為您的模型預測提供 insights 的一整套技術。Explainable AI 不僅能夠幫助建模的人除錯、調整模型,還能提供更透明化的資訊,方便相關單位理解模型預測結果背後的原因。
用戶可將測試範例傳送至模型,AI Explanations 則會藉由返回該範例的特徵歸因值 (feature attribution values) 來運作。這些歸因值說明相對於模型基準 (model’s baseline) 預測而言,某特徵對於預測的影響程度有多少。傳統的模型基準是訓練集之中,所有特徵的平均值;而這邊的特徵歸因值,則能說明「相對於平均個體,特定特徵對預測的影響程度」。
AI Explanations 提供兩項近似方法:Integrated Gradients(整合梯度)以及 Sampled Shapley,兩者皆可以在 AI 平台上使用。AutoML Tables 使用 Sampled Shapley,而整合梯度,顧名思義,使用梯度(顯示預測各點如何變化)的漸變,它需要在 TensorFlow 中實作可微分模型,這種作法是對於神經網路類的模型是再自然不過的選擇。Sampled Shapley 透過抽樣離散的 Shapley 值 獲得近似值。儘管特徵數量無法輕易增減,不過 Sampled Shapely 確實適用於不可微分模型,例如樹狀整體模型 (tree ensembles)。兩種方法皆可以透過將特徵與基準比較,來評估模型的每個特徵影響模型預測的程度。您可以在 Google 的這份白皮書了解更多資訊。
關於資料集與情境
這份 BigQuery 公開資料集提供了素材,這些資料集對於用機器學習來實驗相當好用。以下範例,我們將使用儲存在 BigQuery 中的倫敦自行車租賃以及 NOAA 天氣數據,這兩個公開資料集的結合,並進行一些額外的處理,來清除離群值 (outliers) 並額外取出 GIS 及星期幾 (day of week) 的欄位。
我們將利用起點與終點站、星期幾、當日天氣及其他相關數據,建立一個回歸模型,來預測「自行車租賃的騎乘時間」。假設我們經營一間自行車租賃公司,就能使用預測結果及其解釋來幫助我們預測客戶需求,甚至還能計畫如何在每個據點調整自行車庫存。
當我們使用自行車與天氣數據時,您可以將 AI Explanations 用於各種表格式的模型,如:承擔資產評估、詐欺偵測、信用風險分析、客戶保留預測、分析商店中商品的擺放位置等等。
AutoML Tables 的 AI Explanations
AutoML Tables 讓您可以用自己的結構化數據自動建立、分析和部署最新的機器學習模型。一旦您的客製化模型訓練完後,您便可以查看評價指標、檢查其結構、將其部署到雲端上或是輸出模型,這樣您就可以在任何有容器運行的地方使用它。
除此之外,AutoML Tables 還可以解釋您客製化模型的預測結果。我們會在下面的範例展示此功能。我們將使用上述的「自行車與天氣」資料集,我們將直接從 BigQuery 的資料表擷取這些資料。此篇文章會逐步介紹資料擷取(使用 AutoML 就能輕鬆擷取),以及使用 Cloud Console UI 中的資料集進行訓練的過程。
全域特徵重要性
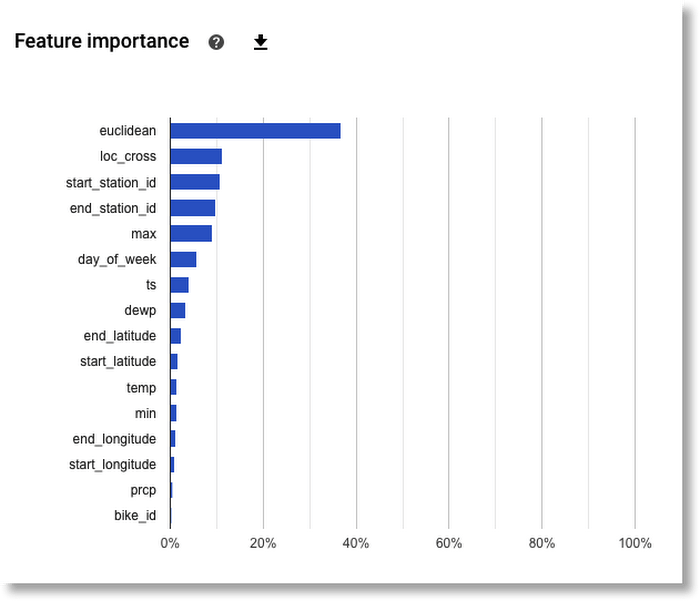
AutoML Tables 會自動替訓練後的模型計算「全域特徵重要性」 (global feature importance)。它代表的是,在整個評估集 (evaluation set) 中,每個特徵獲得的平均絕對歸因值。歸因值較高,代表該特徵通常對模型預測結果有較大的影響。此資訊有助於除錯與改善模型。如果某特徵的貢獻很小(歸因值很低),在後續訓練模型時可排除特徵,以簡化模型。根據下圖,以我們的範例來看,我們可以試著在之後訓練模型時排除 bike_id。
局部特徵重要性
您還可以量測「局部特徵的重要性」 (local feature importance);它是一個顯示在單個範例中,每個特徵對預測結果的影響程度(和影響方向)的分數。
透過 Cloud Console 的表格 UI 可以輕鬆的探索局部特徵的重要性。當您部署模型之後,前往表格 (Tables) 面板上的測試及使用 (TEST & USE) 分頁,選擇線上預測 (ONLINE PREDICTION),輸入欲預測的欄位值,接著在頁面底下勾選產生特徵重要性 (Generate feature importance)。目前的結果會是預測值、基準預測值及特徵重要性。
讓我們來看幾個例子。範例中,我們使用測試資料集中的實例取代即時數據,而這些數據是模型在訓練過程中是無法看見的。AutoML tables 使您在訓練後,讓您將測試資料集,包含目標欄位,導出到 BigQuery,這使其更容易探索。
對自行車租賃業務來說,他們可能會想調查,為何「同樣的兩個租車站、不同的行程,有時會被預測出不同的騎乘時間」。讓我們看看預測解釋是否能夠給我們任何提示。實際騎乘時間(我們希望模型能預測的)在下圖以紅色標記。
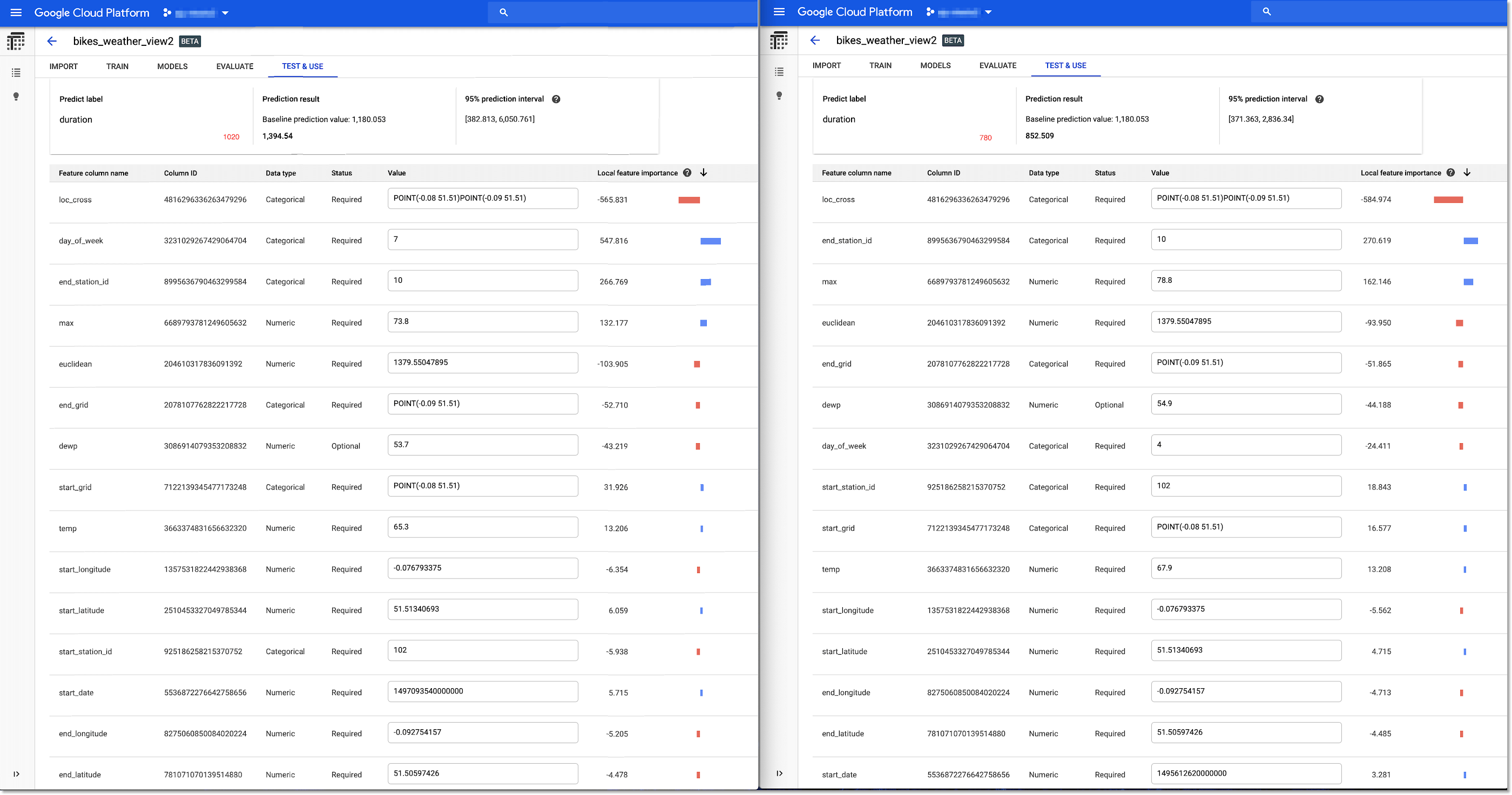
左右兩個行程的預測,預測的都是相同地點往返,但左側的行程有被正確預測出,其騎乘時間較長。以上圖看來,「星期幾」(day of week,7 是週末、4 是平日)是個重要的歸因。當我們在 BigQuery 中探索測試資料集時,我們也驗證發現,週末的平均騎乘時間確實是比平日來得長。
讓我們再來看兩個有相同特性的行程:相同地點往返,但其中一趟行程,成功地被預測出較長的騎乘時間。
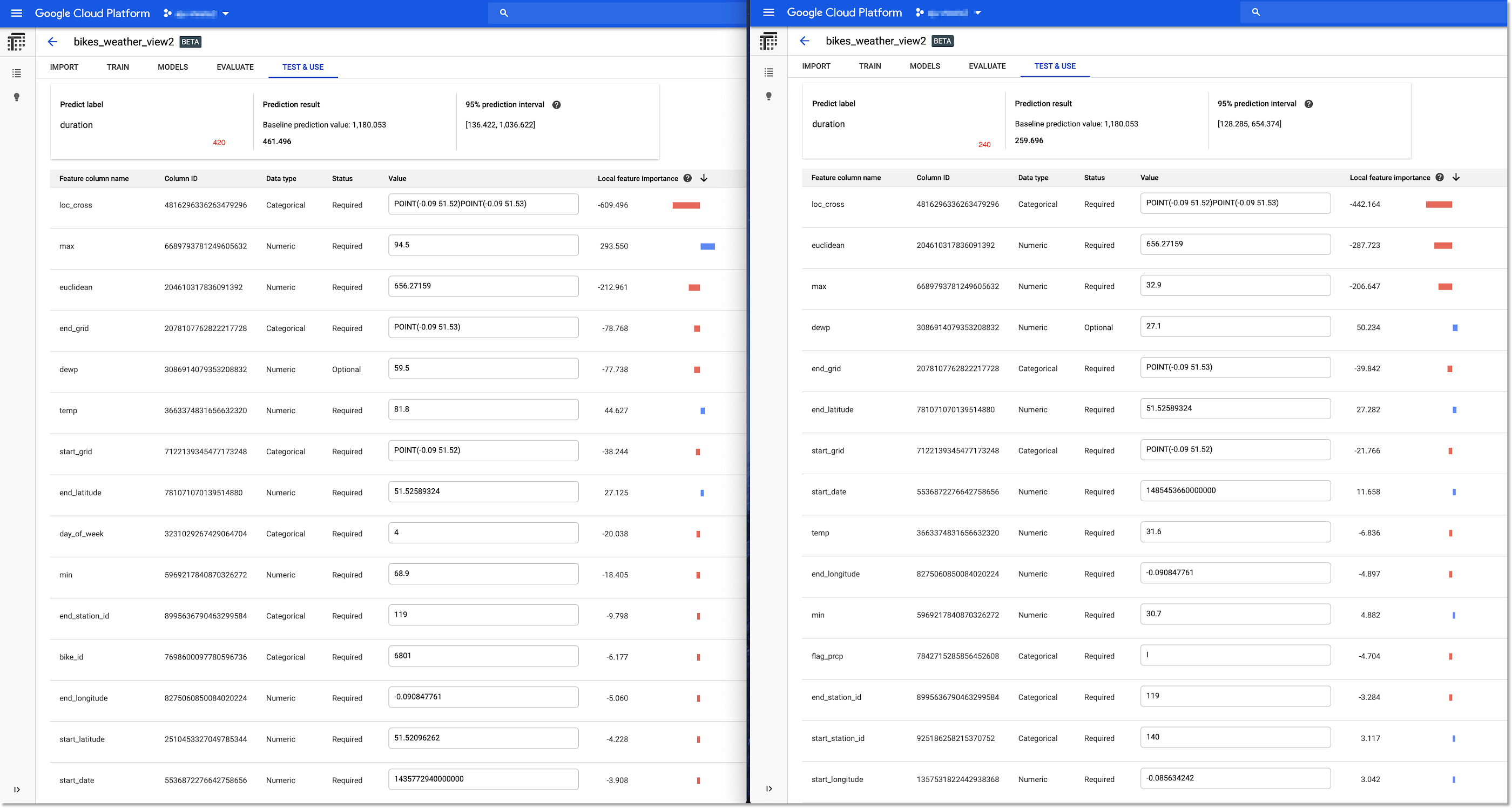
在這個案例中,天氣──尤其是最高溫度 (max),看似是一個重要變因。而前往 BigQuery 測試資料集查看最高及最低溫度的平均騎乘時間時,這個理論也得到驗證。
因此,這些預測解釋說明,在週末及炎熱的天氣,自行車程所花費的時間會比原本的時間來的更長。自行車租賃公司就能透過這些數據,調整自行車庫存或其他流程,以改善業務。
至於不準確的預測呢?了解預測錯誤的原因也極具價值,所以讓我們再看一個案例:預測結果比實際的騎乘時間來的更長,如下圖所示。

同樣地,我們將錯誤預測結果的範例上傳到 Cloud Console。這次,局部特徵重要性值顯示,起始站 (starting station) 可能在過高的預測結果中,對模型產生比平常更大的影響。或者,從該站出發也許會有更多變化性。
在 BigQuery上查詢測試資料集後,可以發現該站在預測準確度的標準差中屬於前三名。基於預測結果的高度變化,自行車出租公司可能可以調查該站或其租賃設施是否有問題。
利用 AutoML Tables 的客戶端函式庫 (client libraries) 獲得局部性解釋
您還可以利用 AutoML Tables 客戶端函式庫 (client libraries) 以程式化方式與 Tables API 互動。也就是說,您可以從 script 或 notebook 創建資料集、訓練模型、獲得評估結果、部署模型以提供服務,以及請求所輸入資料的預測結果的局部性解釋 (local explanations)。
舉例來說,利用以下「自行車和天氣」模型輸入案例:
inputs = {
"bike_id": "5373",
"day_of_week": "3",
"end_latitude": 51.52059681,
"end_longitude": -0.116688468,
"end_station_id": "68",
...
}
您就能請求帶有局部特徵重要性註解的預測結果,如下:
from google.cloud import automl_v1beta1 as automl
client = automl.TablesClient(project=PROJECT_ID, region=REGION)
response = client.predict(
model_display_name=model_display_name,
inputs=inputs,
feature_importance=True,
)
此回覆不僅包含預測結果和 95% 的預測區間──代表預測的正確值落在此區間的可能性高達 95%,也包含每個輸入欄位的局部特徵重要值。預測回覆會類似這樣。
想了解更詳細地的步驟,並學習如何解析和繪製預測結果,可參閱這個 notebook。
在下一篇文章,我們會接著介紹如何將 Tensorflow 客製化模型部署至 Google Cloud AI 平台,獲取預測結果和特徵歸因值,並介紹如何透過 What-If 工具將模型結果視覺化呈現。
(原文改編翻譯自 Google Cloud。)