
我們很高興地宣布 Pub/Sub 到 Splunk Dataflow 模板的幾個新的可觀察性功能,以幫助運營商密切關注他們的 streaming pipeline 性能。 Splunk Enterprise 和 Splunk Cloud 客戶使用 Splunk Dataflow 模板可靠地導出 Google Cloud 日誌,以便針對安全、IT 或業務用案例進行深入分析。 借由替 Splunk IO sink 新添加指標和改進日誌記錄,現在可以更輕鬆地回答操作問題,例如:
- Dataflow pipeline 是否跟上產生的日誌量?
- 寫入 Splunk 時的延遲和吞吐量(每秒事件數或 EPS)是多少?
- 下游 Splunk HTTP 事件收集器 (HEC) 的響應狀態細分和潛在錯誤消息是什麼?
這種關鍵的可見性可幫助您取得日誌導出服務級別指標 (SLI) 並監控任何管道性能回歸。 您還可以更輕鬆地找出導致 Dataflow 和 Splunk 之間潛在下游故障的根本原因,例如 Splunk HEC 網絡連接或服務器錯誤,並在問題出現之前解決問題。
客戶可以花更少的時間管理基礎設施,並專注於他們的業務運營。Verily Life Sciences 的 SecOps 負責人 Gomez 說: “Splunk 的Dataflow模板簡化了流程,因為我們收集了大量日誌作為自主安全操作(ASO)工作的一部分。我們在不到一個小時的時間內部署了一個測試環境,幾天後我們的生產日誌支援超過 100k EPS。而且新的自定義指標還透過使我們持續監控系統的性能和健康狀況來加速我們包括高峰時段的運營。
為了幫助您快速繪製這些新指標的圖表,我們已將它們包含在自定義儀表板中,作為 Splunk Dataflow 更新的 Terraform 模塊的一部分。 您可以使用這些 Terraform 模板來部署整個基礎架構,以將日誌導出到 Splunk,或者你也可以僅用來部署到監控儀表板中。
更多指標
在您的 Dataflow 控制台中,您可能已經注意到從模板版本 2022-03-21-00_RC01 開始的已啟動作業的幾個新自定義指標(如下所示),即 isgs://dataflow-templates/2022-03-21-00_RC01/Cloud_PubSub_to_Splunk 或以後:

Pipeline 儀表
在深入研究新指標之前,讓我們退後一步,回顧一下 Splunk Dataflow 作業步驟。 以下流程圖表示組成 Splunk Dataflow 作業的不同階段以及相應的自定義指標:
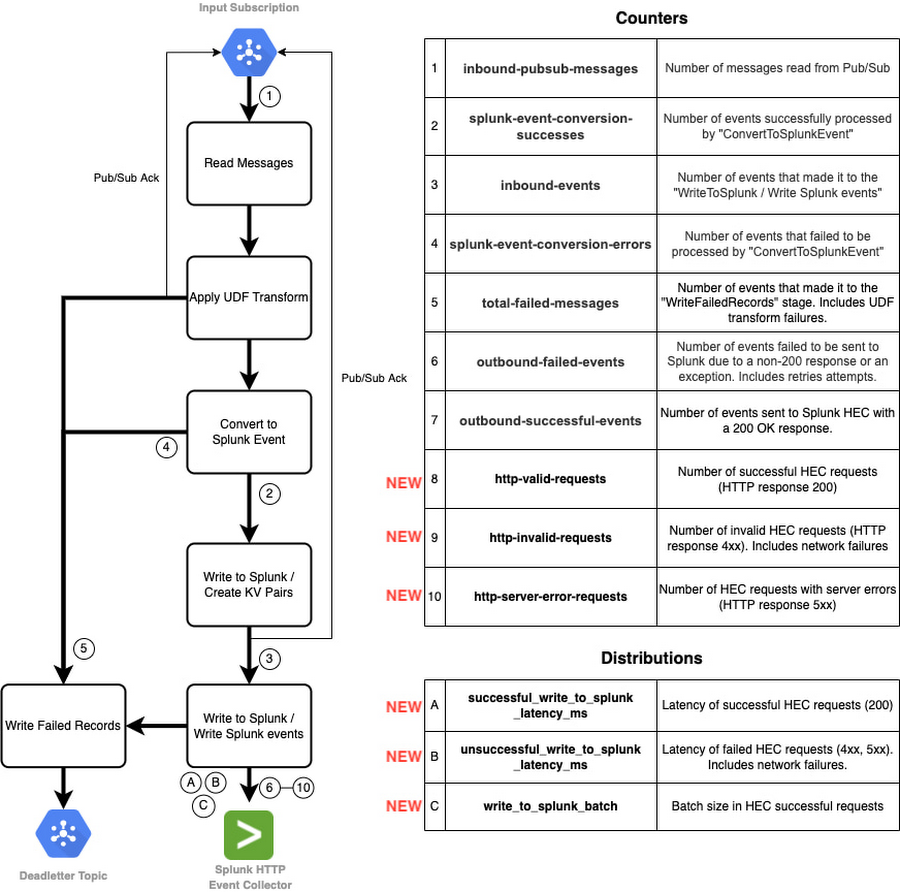
在此 pipeline 中,我們使用兩種類型的 Apache Beam 自定義指標:
- 上面標記為 1 到 10 的計數器指標用於計算消息和請求(成功和失敗)。
- 上面標記為 A 到 C 的分佈指標用於報告請求延遲(成功和失敗)和批量大小的分佈。
下游請求可見性
Splunk Dataflow 操作員依賴其中一些預先構建的自定義指標來監控在不同管道階段進度的日誌訊息,特別是在最後一個階段寫入 Splunk,指標為 outbound-successful-events(上面的計數器 #6)和 outbound- failed-events(上面的計數器 #7)跟踪成功導出(或未導出)到 Splunk 的消息數量。 雖然營運商可以了解出站消息的成功率,但他們在 HEC 請求級別缺乏可見性。 Splunk Dataflow 操作員現在不僅可以監控一段時間內成功和失敗的 HEC 請求的數量,還可以監控響應狀態細分,以確定請求是否客戶端的請求問題(例如無效的 Splunk 索引或 HEC 令牌)或臨時網路抑或是Splunk 問題而導致失敗。(例如服務器繁忙或停機)這些都來自 Dataflow 控制台,並添加了上面的計數器 #7-10,即:
- http-valid-requests
- http-invalid-requests
- http-server-error-requests
Splunk Dataflow 操作員現在還可以通過使用新的分佈指標#A-C 來跟踪對 Splunk HEC 的下游請求的平均延遲,以及平均請求批量大小,即:
- successful_write_to_splunk_latency_ms
- unsuccessful_write_to_splunk_latency_ms
- write_to_splunk_batch
請注意, Dataflow 將 Beam 中的分佈指標報告為四個子指標,後綴為 _MAX、_MIN、_MEAN 和 _COUNT。 這就是為什麼這 3 個新的分佈指標會在 Cloud Monitoring 中轉換為 12 個新指標,正如您在 Dataflow 控制台之前的作業訊息螢幕截圖中看到的那樣。 Dataflow 目前不支持建立直方圖來可視化這些指標值的細分。 因此,_MEAN 指標是唯一對我們有用的子指標。 作為一個歷史平均值,_MEAN 不能用於跟踪任意時間間隔(例如每小時)的變化,但它對於捕獲基線、跟踪趨勢或比較不同的管道很有用。
Dataflow 自定義指標,包括 Splunk Dataflow 模板報告的上述指標,是 Cloud Monitoring 的一項收費功能。 如需詳細了解指標定價,請參閱 Cloud Monitoring 定價。
改進的紀錄
記錄 HEC 錯誤
為了進一步解決下游問題的根本原因,現在已充分記錄 HEC 請求錯誤,包括回應狀態碼和消息:您可以透過將日誌嚴重性設置為Error,便可以直接在 Dataflow 控制台的工作器日誌中檢索它們。
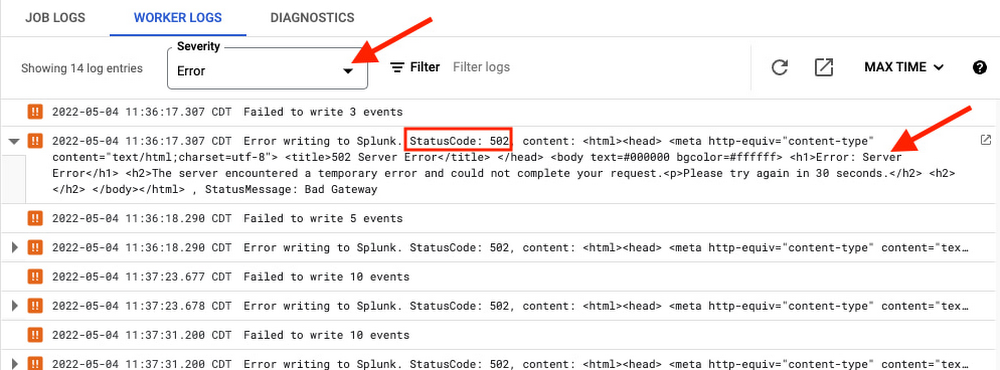
或者對於喜歡使用 Logs Explorer 的用戶,您可以使用以下查詢。
log_id("dataflow.googleapis.com/worker")
resource.type="dataflow_step"
resource.labels.step_id="WriteToSplunk/Write Splunk events"
severity=ERROR
禁用批處理日誌
默認情況下,Splunk Dataflow 工作人員按如下方式記錄每個 HEC 請求:
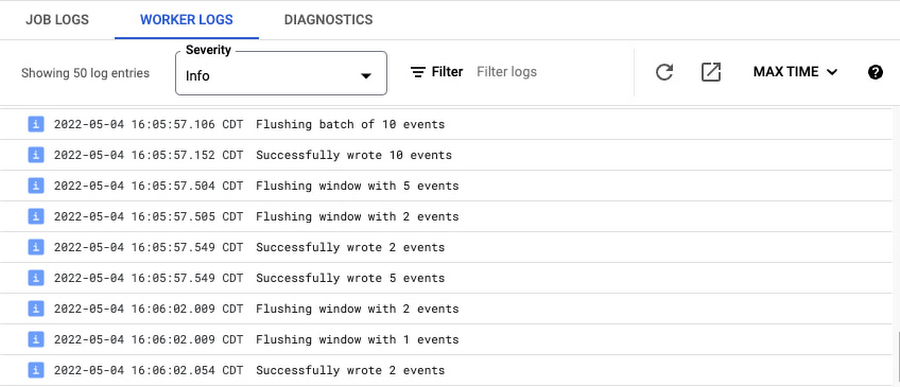
即使這些請求通常是批次處理事件,這些“批次處理日誌”也很健談,因為它們為每個 HEC 請求添加 2 條日誌消息。 加上上面提到的請求級計數器 (http-*-requests)、延遲和批量大小分佈以及 HEC 錯誤日誌記錄,這些批量日誌通常是多餘的。 為了控制工作器日誌量,您現在可以在部署 Splunk Dataflow 作業時通過將新的可選模板參數 enableBatchLogs 設置為 false 來禁用這些批次處理日誌。 有關最新模板參數的更多詳細信息,請參閱模板用戶文件。
啟用除錯級別日誌
INFO是 Google 所提供使用 Apache Beam Java SDK 編寫模板的默認日誌記錄級別 ,這意味著將記錄所有 INFO 及更高級別的消息,即 WARN 和 ERROR。 如果您想啟用 DEBUG 等較低的日誌級別,可以在使用 gcloud command-line工具啟動pipeline時將 –defaultWorkerLogLevel 標誌設置為 DEBUG 來實現。
您還可以使用 –workerLogLevelOverrides 標誌覆蓋特定packages或 classes的日誌級別。 例如,HttpEventPublisher 類在 DEBUG 級別記錄發送到 Splunk 的最終有效負載。 您可以將 –workerLogLevelOverrides 標誌設置為 {“com.google.cloud.teleport.splunk.HttpEventPublisher”:”DEBUG”} 以在將最終消息發送到 Splunk 之前查看日誌中的最終消息,並將其他 classes 的日誌級別保持在 INFO。 使用此選項時要小心,因為它會在控制台的 Worker Logs 選項卡下記錄發送到 Splunk 的所有消息,這可能會導致日誌節流或洩露敏感訊息。
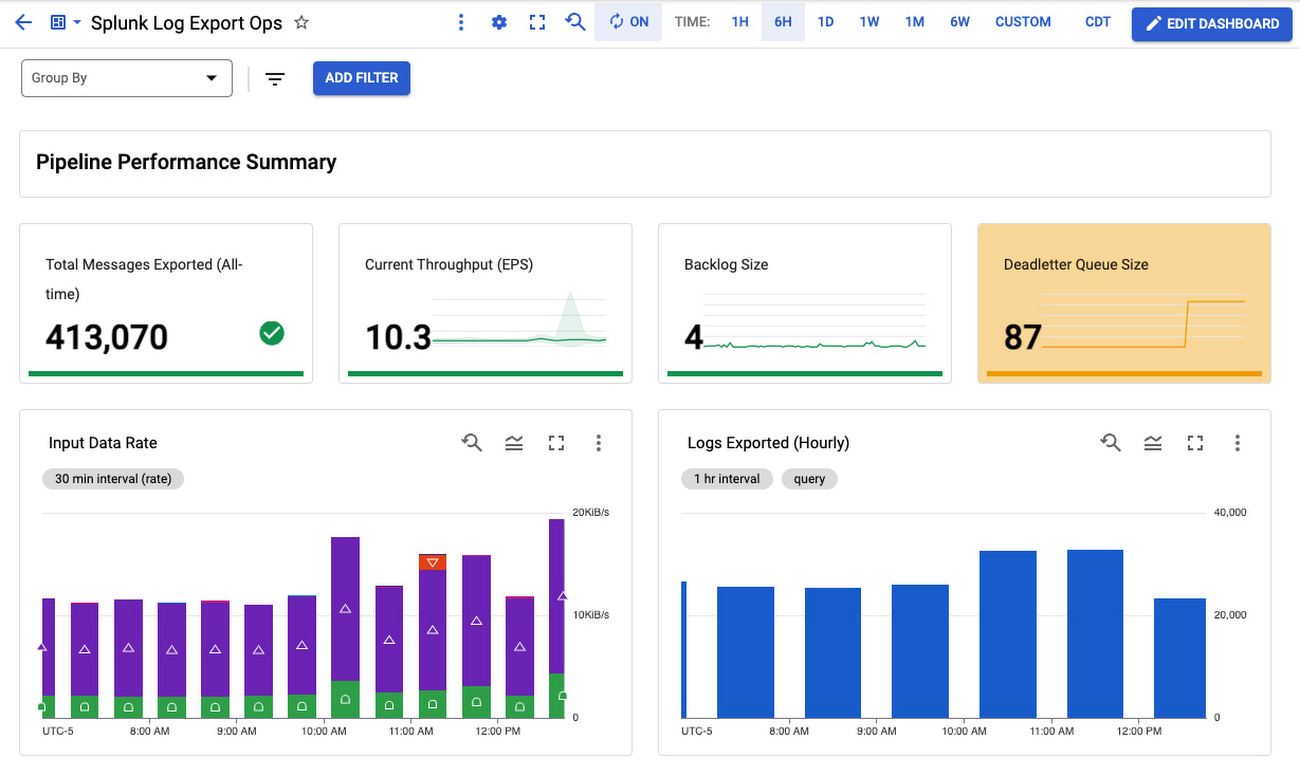
把它們放在一起
我們將所有這些放在一個監控儀表板中,您可以輕鬆地使用它來監控您的日誌導出操作:
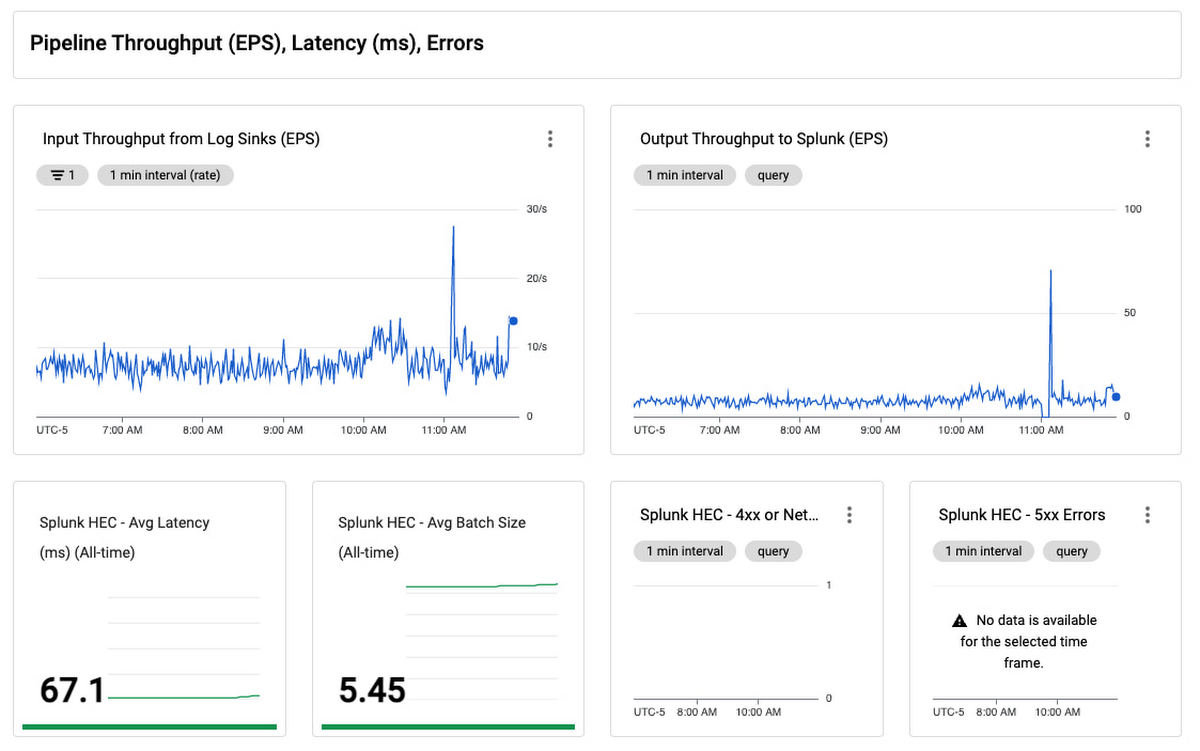
此儀表板是用於監控您的 Pub/Sub 到 Splunk Dataflow pipeline的單一管理平台。 使用它來確保您的日誌導出滿足您的動態日誌量要求,通過擴展至足夠的吞吐量 (EPS) 速率,同時將延遲和積壓降至最低。 還有一個面板可以跟踪管道資源的使用和利用率,以幫助您驗證 pipeline 在穩定狀態下是否具成本效益的運行。
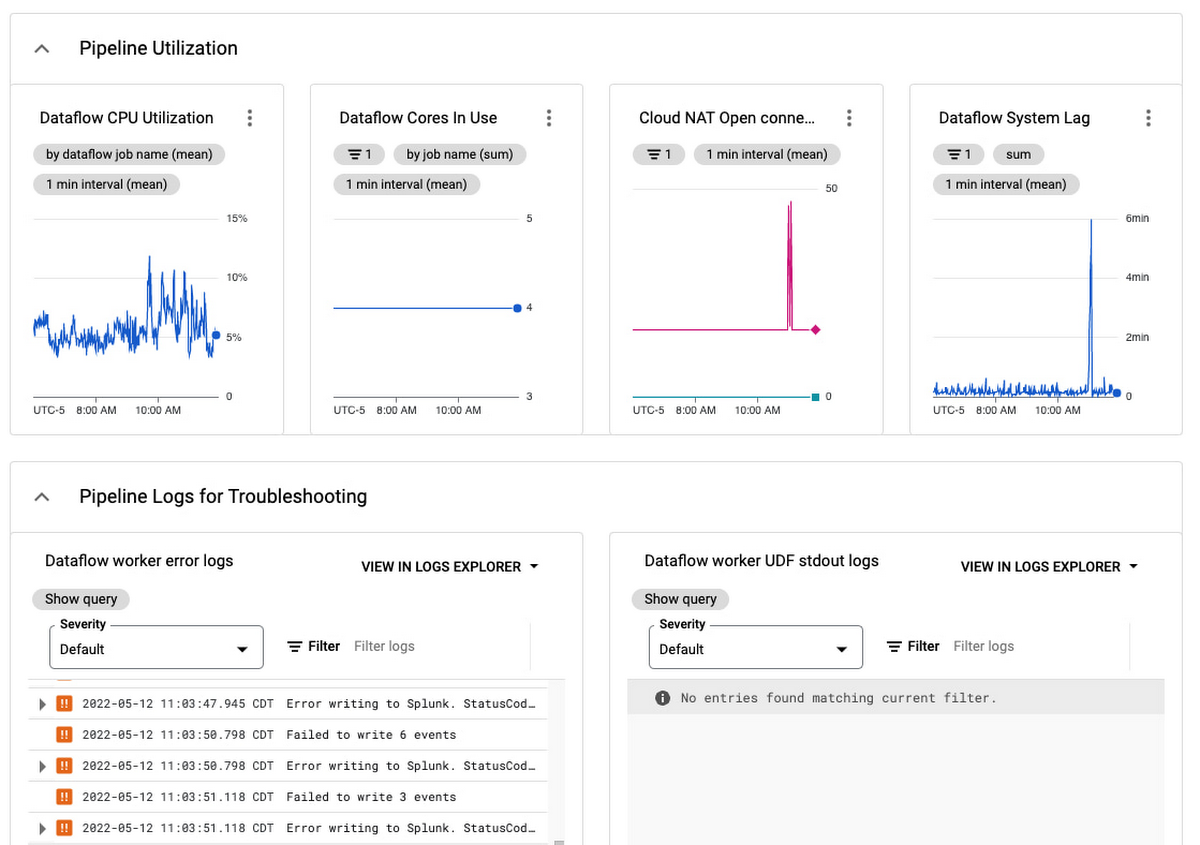
有關處理和重放失敗消息的具體指導,請參閱作為 Splunk 數據流參考指南一部分的失敗消息故障排除。 有關對任何 Dataflow pipeline進行故障排除的一般信息,請查看故障排除和除錯文檔;有關常見錯誤及其解決方法的列表,請查看常見錯誤指導文件。 如果您遇到任何問題,請在 Dataflow 模板 GitHub 儲存庫中打開問題,或直接在您的 Google Cloud Console 中開啟support case。
有關如何將 GCP 日誌導出到 Splunk 的步驟指南,請查看使用 Dataflow 將生產就緒日誌導出到 Splunk 教程,或使用隨附的 Terraform 腳本自動設置日誌導出基礎架構以及相關的操作儀表板。