
Kubernetes 是執行 AI 工作負載一種流行的方式,例如訓練和大型語言模型 (LLM),包括我們新開放的模型 Gemma。Google Kubernetes Engine (GKE) Autopilot 模式提供了一個完全託管的 Kubernetes 平台,該平台提供企業運用 Kubernetes 強大的功能和靈活性,但無需擔心運算節點,因此可以專注藉由 AI 創造企業的業務價值。
2024 年 3 月,Google Cloud 宣布 Autopilot 中 Accelerator compute 類型正式發布,這個新類型大幅提升了 GPU 支援,並加入了資源保留功能,讓您更有效地管理 GPU 資源。此外,對於大多數 GPU 工作負載,價格也有所降低。此外,全新 Performance compute 類型使高效能工作負載能夠在 Autopilot 模式下大規模運作。上述兩個運算類型還在啟動磁碟上提供了更多可用的臨時存儲,為您提供了更多空間來下載 AI 模型等,然後再需要透過通用臨時 volumes 配置額外存儲。透過這些增強功能,全托管的 Kubernetes 平台用於推理和其他計算密集型工作負載的效果更佳。
透過在 Autopilot 模式下執行 GKE,您無需預先指定和配置節點,而可以專注於建立工作負載並創造自己的業務價值。作為一個完全託管的平台,一旦建立了工作負載,您就可以以更少的營運開銷來運行它。
GKE Autopilot 提供價格更低的 GPU 方案
我們正在降低在 Autopilot 模式下運行 GKE 上大部分 GPU 工作負載的價格,並轉向新的計費模式,以提高與 Google Cloud 中其他產品和體驗的兼容性。現在,您可以在 GKE 的 Standard 模式和 Autopilot 模式之間以及 Compute Engine VM 之間移動工作負載,並保留現有的預定和承諾使用折扣。
當您啟用新的定價模型時(透過指定 Accelerate 計算類別,如下面的程式碼範例所示),資源將根據 Compute Engine VM 資源進行計費,並根據完全託管的體驗收取額外費用。如今,新的定價模式可供選擇;4 月 30 日之後,將發布 GKE 版本,自動將 GPU 工作負載遷移到這個新模型。這些變化帶來的大多數工作負載的價格都較低(每個 GPU 少於 2 個 vCPU 的 NVIDIA T4 GPU 上的工作負載價格略有上漲)。
以下是 us-central1 區域中幾種工作負載大小的 GPU、CPU 和記憶體資源(額外儲存)每小時的價格比較:
| GPU | Pod Resource Requests | VM resources | Old price (GPU Pod) | New price (Accelerator Compute Class Pod) |
| NVIDIA A100 80GB | 1 GPU
11 vCPU 148 GB memory |
1 GPU
12 vCPU 170 GB memory |
$6.09 | $5.59 |
| NVIDIA A100 40GB | 1 GPU
11 vCPU 74 GB memory |
1 GPU
12 vCPU 85 GB memory |
$4.46 | $4.09 |
| NVIDIA L4 | 1 GPU
11 vCPU 40 GB memory |
1 GPU
12 vCPU 48 GB memory |
$1.61 | $1.12 |
| NVIDIA T4 | 1 GPU
1 vCPU 1 GB memory |
1 GPU
2 vCPU 2 GB memory |
$0.46 | $0.47 |
| NVIDIA T4 | 1 GPU
20 vCPU 40 GB memory |
1 GPU
22 vCPU 48 GB memory |
$1.96 | $1.37 |
使用 Accelerator 計算類別時,工作負載按(並且可以利用)整個節點 VM 容量進行計費,包括突發為系統 Pod 分配的資源。
若要立即選擇接受這些更改,請升級至版本 1.28.6-gke.1095000 或更高版本,並將運算類別選擇器新增至現有 GPU 工作負載,如下所示:
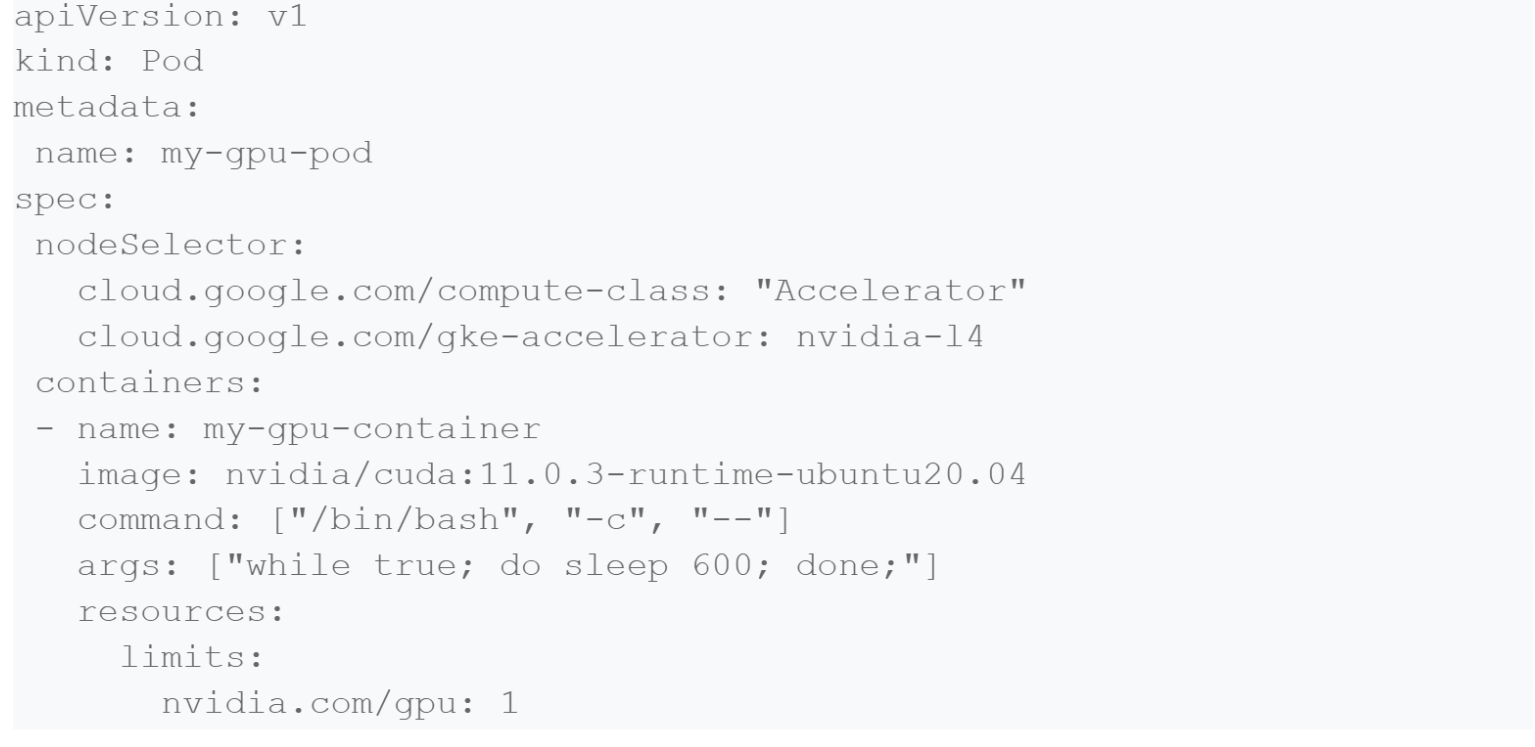
GKE Autopilot 也提供效能更高的 CPU 資源
如果您需要專用的 CPU 資源來處理工作負載,Autopilot 現在會採用與 GPU 類似的方法。現在您可以在 Compute Engine 的主要機器系列上運行 GKE Autopilot 工作負載,包括新的 C3、C3D 和 H3 機器,以及 C2、C2D 等!這些資源可以作為效能計算類別的一部分來請求。這是一個例子:

預先針對資源需求預約 GPU
過去,您無法在 Autopilot 模式下進行預約,以確保您的專案擁有滿足未來需求成長的資源。不過,目前已開放預約了!現在你可以使用非常簡單的方式,針對 GPU(當您選擇新型號時)和高效能 CPU 進行預約使用。
更大的啟動磁碟
雖然 GKE 允許您將多個 persistent volumes 掛載到容器中,每個持久 volumes 在容器中的任何路徑上最多可達64TB,但為 Pod 提供更大的啟動磁碟讓您可以使用臨時存儲,而無需掛載 separate volume。當使用上面的效能或加速器計算類別標籤時,您的工作負載現在可以消耗高達 122GiB 的暫存。需要更多?可以安裝永久磁碟以進一步擴展。
GKE Autopilot 減少作業複雜性,必要時提供專屬硬體
您可能想知道,常規 Autopilot Pod 與這款新型號如何搭配?如果您的工作負載需要專用的高效能 CPU 硬體(例如 C3 機器提供的硬體),您可以使用上述節點選擇器,根據這些要求來註解該工作負載。
但是,如何支援與主要工作負載一起運行但不需要相同運算能力的工作負載呢?這就是 Autopilot 模式真正擅長的地方:預設情況下,所有其他工作負載將繼續在標準 Pod 模型上運行,為沒有高效能 CPU 需求的工作負載提供極高的性價比。在 Autopilot 模式下,只需註解那些需要專用硬體(例如特定 GPU 或機器系列)的工作負載,我們將完成其餘的工作。將其他工作負載留空,並放心它們不會意外地在專用硬體上運行。這樣,您就可以從每個執行環境中獲得最佳價值:Autopilot 中廣泛適用的預設值,以及在需要時的專用硬體。
參考文章:Running AI on fully managed GKE, now with new compute options, pricing and resource reservations
延伸閱讀:Accelerate your generative AI journey with NVIDIA NeMo framework on GKE