使用者在使用 GCP 的 Compute Engine 時,多少會遇到幾次 VM 重開機的狀況。查看 Stackdriver 日誌後會發現 Host Error 的相關訊息,此篇文章將帶您了解什麼是 Host Error。
Q: 什麼是 Host Error ?
A: Host Error 表示 VM 的 host machine(實體機器)發生了硬體或軟體問題導致 VM 崩潰,為不可避免的事件。 當Compute Engine 檢測到此類事件時,GCP 會在 console 的操作日誌(Compute Engine -> Operation,如下圖)中寫入 compute.instances.hostError 這個 log。如果您的 VM 設定為自動重啟(default 設定),Google 將在其他 physical mahcine(實體機器)上重新啟動 VM。
Q: Host Error 會不會很常發生?
A: Host Error 的情況非常罕見,受影響的 instance 將會重開機(default 行為)。
Q: 如何避免 Host Error 的發生?
A: 不管是地端或是雲端,硬體或軟體問題導致 physical machine(實體機器) 崩潰的問題都是會發生的。總而言之,Host Error 為不可避免的事件,無法防止它發生。
Q: 如果無法避免 Host Error 的發生,我該怎麼降低機器重啟所帶來的影響?
A: 為了降低 Host Error 所帶來的影響,確保您遵循官方建議的最佳實踐系統,以及打造可擴展的應用程式。
Q: 有沒有辦法能夠讓系統送出 Host Error 的告警?
A: GCP 並不會主動發送告警,只會把 Host Error 的紀錄寫進日誌當中。不過,使用者可以自行設定讓 Stackdriver 送出機器重啟的告警。以下提供詳細的告警設定步驟:
Step 1 前往 Stackdriver Logging > Logs Viewer
Step 2 點選右上角的箭頭並選取 Convert to advanced filter

Step 3 輸入以下 filter 內容至欄位當中,這邊加入 migrateOnHostMaintenance 事件是因為需要測試 Alert 的功能

resource.type=”gce_instance”
jsonPayload.event_subtype=(“compute.instances.automaticRestart” OR
“compute.instances.hostError” OR “compute.instances.migrateOnHostMaintenance”)
Step 4 點選 Create Metric

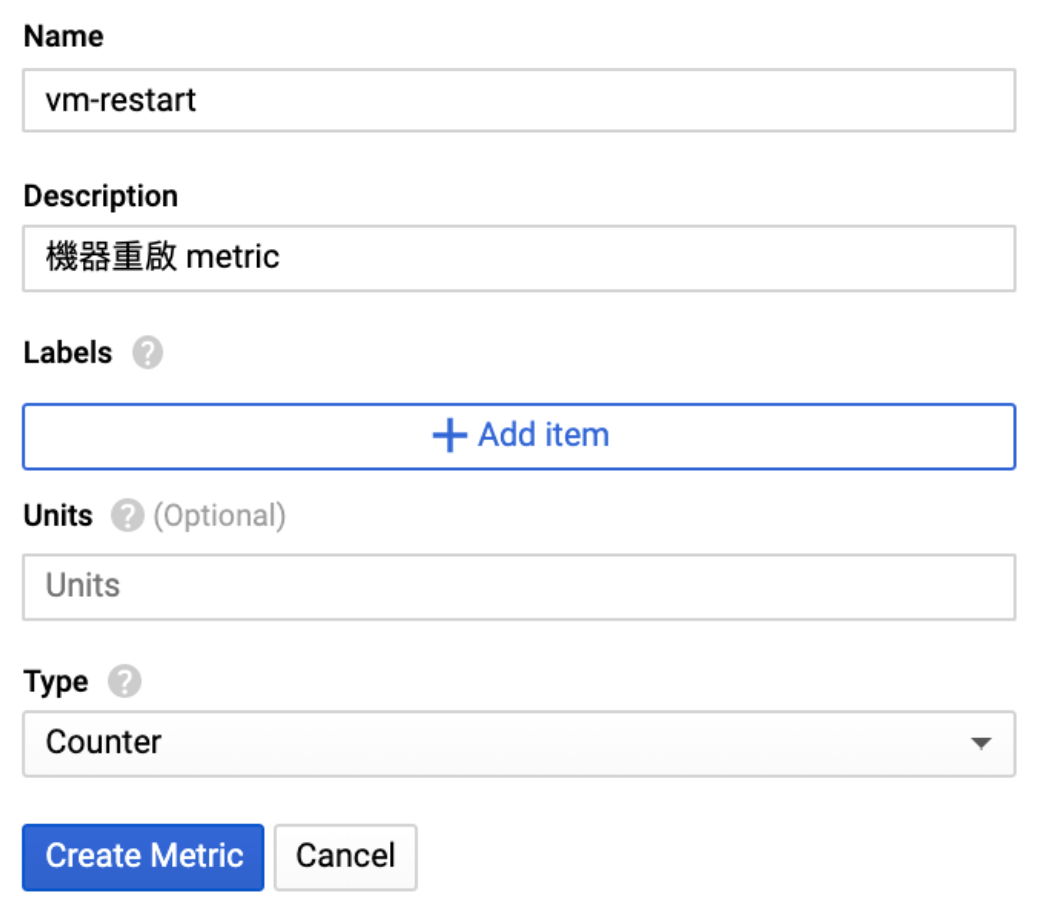
Step 5 填寫右方表單,填寫完畢後點選 create metric
Step 6 在 Stackdriver Logging > Logs-based metrics 下方區塊可以看到剛剛設定的 metric

Step 7 前往 Stackdriver > Monitoring
Step 8 點選 Alert > Create a Policy

Step 9 點選 Add Condition 的按鈕
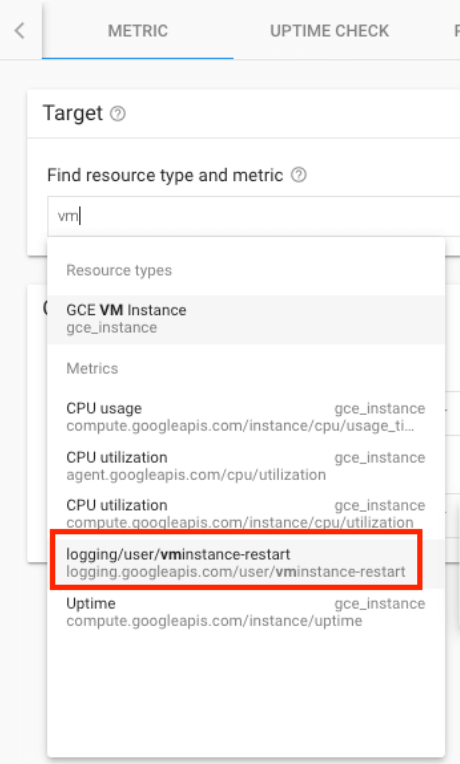
Step 10 找到 [Target] Find resource type and metric 並選取剛剛建立的 metric
這邊需要注意不能選 Resource Type,直接輸入您 metric 的名稱。
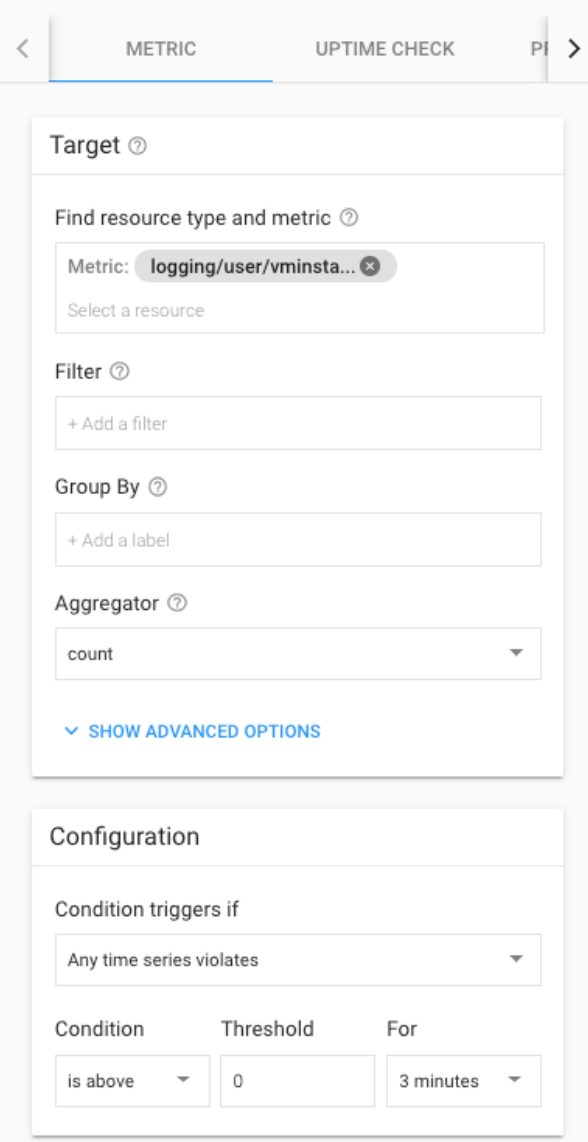
Step 11 最終設定請參考下圖,設定完成之後點選 save
[ Target ]
Resource Type = 不要選
Metric = vminstance-restart
Aggregator = none
[ Configuration ]
Condition triggers if = Any time series violates
Condition = is above
Threshold = 0
For = 3 minutes
Step 12 設立 Email notification 的 email account,並輸入 Alert Policy 的名稱。填寫完畢之後即點選 save 的按鈕,建立 Alert Policy

Step 13 針對測試 VM 進行維護事件模擬[1],在指令列輸入以下指令。
此指令為觸發模擬實際的 VM 維護事件,執行完畢後可以在 Compute Engine > Operation 看到模擬事件。
gcloud compute instances simulate-maintenance-event [instance_name] --zone [zone] --project [project_id]
[1] https://cloud.google.com/compute/docs/instances/setting-instance-scheduling-options#testingpolicies

Step 14 模擬事件執行完畢後就會收到 Stackdriver 寄出的 Alert

Step 15 (Optional)
目前的 Metric 是根據 “自動重重啟”、”Host Error”、”維護事件 migration” 去做告警,使用者可以根據需求去增減。不過需要提醒一點,如果刪除”compute.instances.migrateOnHostMaintenance”,Step 13 的模擬維護事件就不會觸發告警。
resource.type="gce_instance"
jsonPayload.event_subtype=("compute.instances.automaticRestart" OR
"compute.instances.hostError" OR "compute.instances.migrateOnHostMaintenance")