
資料量持續增長,並且越來越多地分佈在湖泊、倉庫、雲和文件中。隨著越來越多的用戶需求的案例來說,事實證明,構建資料轉基礎設施的傳統方法難以擴展。釋放資料的全部潛力需要打破這些資料孤島,且越來越被企業視為首要的任務。
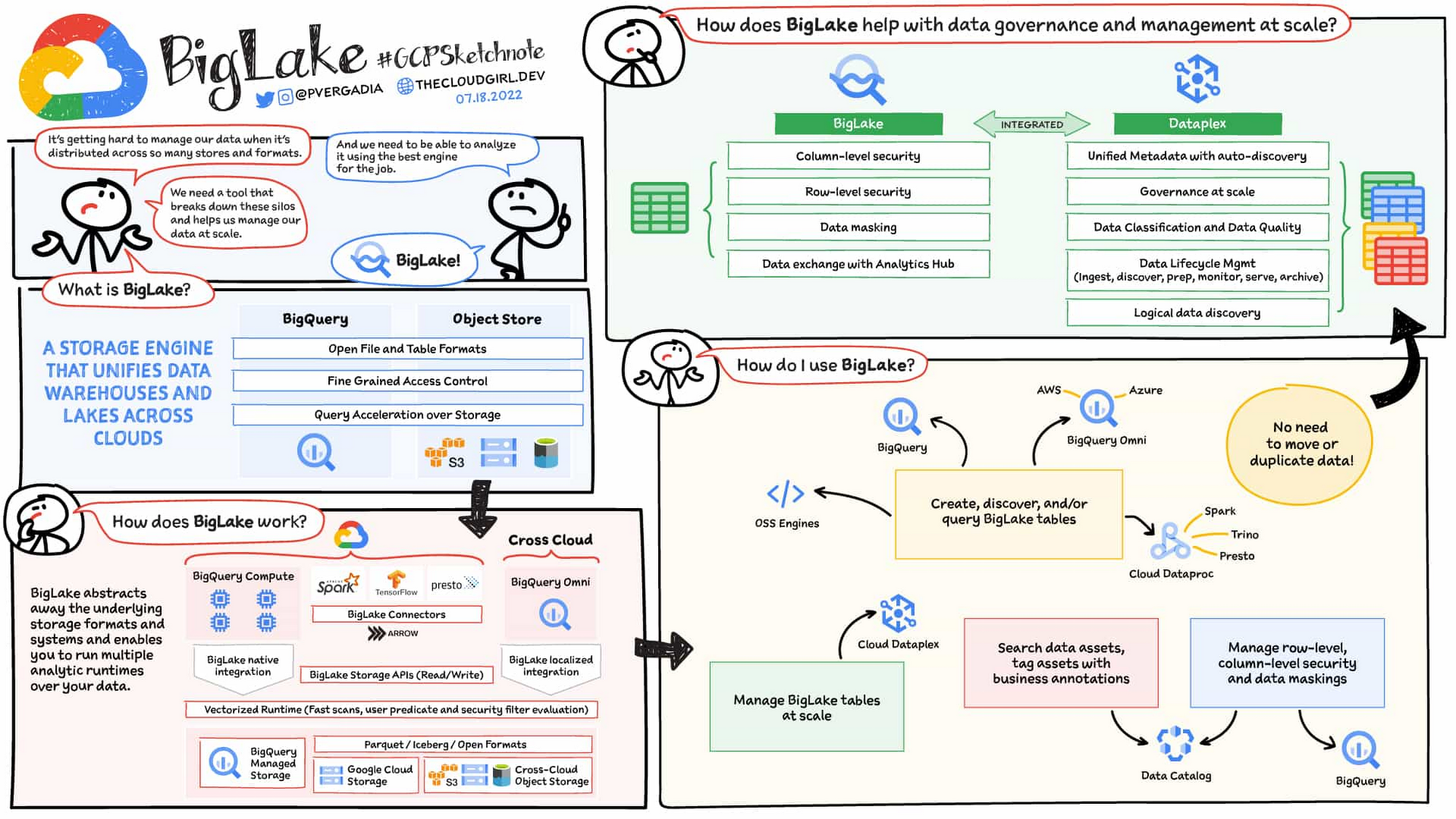
今年初,我們預告了 BigLake,這是一種儲存引擎,它的創新擴展了 BigQuery 儲存庫以及公有雲物件儲存中的開放文件格式。這允許客戶在開放文件格式上構建安全的多雲資料湖泊。BigLake 為 Google Cloud 和開源查詢引擎與資料交互提供一致、細粒度的安全控制。今天,我們很高興地宣布 BigLake 全面上市,以及一組新功能,可幫助您構建差異化的資料平台。
“我們正在使用 GCP 構建和擴展街道上最大的風險系統之一。在多次測試中,我們看到了 BigLake 的巨大潛力和規模。它是可以支援我們的雲之旅並推動應用程式未來效率的產品之一” – Scott Condit,德意志銀行董事首席風險技術官。
使用 BigLake 構建跨倉庫、物件儲存和雲的分佈式資料湖泊
客戶可以在Google Cloud Storage (GCS)、Amazon S3 和 ADLS Gen 2 上通過支援的開放文件格式(例如 Parquet、ORC 和 Avro)創建 BigLake tables。BigLake tables是一種新型的external table,可以像資料倉儲中的 table一樣進行管理。管理員不需要授予用戶對物件儲存中文件的訪問權限,而是在 table、colume或row級別管理訪問。可以從您選擇的查詢引擎(例如 BigQuery 或使用 BigLake 連接器的開源引擎)創建這些 table。創建這些表後,可以在資料目錄中集中發現 BigLake 和 BigQuery tables,並使用 Dataplex 進行管理。
BigLake 將 BigQuery 儲存 API 擴展到物件儲存,以幫助您構建多計算架構。BigLake 連接器基於 BigQuery 儲存 API 構建,支援 Google Cloud DataFlow 和開源查詢引擎(例如 Spark、Trino、Presto、Hive)通過強制執行安全性來查詢 BigLake table。這消除了將資料移動到特定於查詢引擎的需要,並且只需在一個地方設定安全性並在任何地方強制執行。
“我們正在使用 GCP 為我們的客戶設計資料湖泊解決方案,並轉變他們的數位戰略,以創建一個資料驅動的企業。Biglake 對於我們的客戶是至關重要的,能快速了解分析藉由減少構建 ETL 管道的需求來以及縮短上市時間的結果。BigLake 的性能和治理功能為我們的客戶提供了各種資料湖泊案例。” – Sureet Bhurat,創始董事會成員 – Synapse LLC
BigLake 解鎖新用法 – 使用 Google Cloud 和 OSS 查詢引擎
在預先體驗期間,我們看到大量客戶以各種方式使用 BigLake。一些優秀的案例包括:
為開源工作負載構建安全且受管控的資料湖泊- 從 Hadoop、Spark 客戶或使用 Presto/Trino 的客戶遷移的工作負載現在可以使用 BigLake 在 GCS 上構建安全、受管控和高性能的資料湖泊。GCS 上的 BigLake tables提供細粒度的安全性、管理(相對於提供文件訪問權限)、更好的查詢性能以及與 Dataplex 的集中管理。使用 BigLake 連接器時,可以跨多個 OSS 查詢引擎訪問這些特徵。
“為了支援我們的資料驅動型組織,Wizard 需要一個資料湖泊解決方案,該解決方案可以利用開放文件格式並且可以增長以滿足我們的需求。BigLake 允許我們在開放文件格式上構建和查詢,擴展以滿足我們的需求,並加速我們的發現 insights. 我們期待通過未來的 BigLake 功能擴展我們的專案”- Rich Archer,高級數據工程師 – Wizard
消除或減少跨資料倉庫和湖泊的重複資料- 使用 GCS 和 BigQuery 託管儲存的客戶之前必須創建兩個資料副本以支援使用 BigQuery 和 OSS 引擎的用戶。BigLake 使 GCS tables與 BigQuery tables更加一致,從而減少了重複資料的需求。相反地,客戶現在可以在 BigQuery 儲存和 GCS 之間保留一份資料副本,並且 BigQuery 或 OSS 引擎可以在任一位置以一致、安全的方式訪問資料。
多雲使用情境的細粒度安全性- BigQuery Omni 客戶現在可以使用 Amazon S3 上的 BigLake 表和 ADLS Gen 2 來設定細粒度安全訪問控制,並利用本地化資料處理和跨雲傳輸功能來做多雲分析。在其他雲上創建的tables可以在資料目錄中集中查閱,以便於管理。
分析和資料科學工作負載之間的協作- 使用 Spark 或 Vertex AI 筆記型電腦的資料科學工作負載現在可以通過 API 連接器直接訪問 BigQuery 或 GCS 中的資料,從而增強安全性並消除為訓練模型導入資料的需要。對於 BigQuery 客戶,可以將這些模型導回 BigQuery ML 以產生inferences。
使用新的 BigLake 功能構建差異化資料平台
我們也很高興地宣布新功能作為此次通用可用性發布的一部分。這些包括:
- 分析中心支援:客戶現在可以將 GCS 上的 BigLake tables作為鏈接資料集與合作夥伴、供應商或供應商共享。消費者可以通過他們選擇的查詢引擎(BigQuery、Spark、Presto、Trino、Tensorflow)就地訪問這些資料。
- BigLake 表現在是BigQuery Omni 的default table類型,並且已從以前的default table : external table升級。
- BigQuery 的使用者現在已可以直接在 GCS BigLake tables 中使用 BigQuery ML 訓練模型,且不需要搬遷資料。
- 性能加速(預覽版): 現在可以使用底層 BigQuery 基礎架構加速對 GCS BigLake 表的查詢。如果您想使用此功能,請與您的客戶團隊聯繫或填寫此表格。
- Cloud Data Loss Prevention (DLP) 分析支援:Cloud DLP 可以掃描BigLake 表以大規模識別和保護敏感資料。如果您想使用此功能,請與您的客戶團隊聯繫。
- 資料屏蔽和稽核日誌(即將推出):BigLake tables現在支援動態資料屏蔽,使您能夠屏蔽敏感資料元素以滿足合規性需求。終端使用者對 BigLake tables的 GCS 查詢請求現已記錄在稽核日誌中,並可通過日誌進行查詢
下一步
請參閱 BigLake文件以了解更多資訊,或開始使用此快速入門教程。如果您現在已經在使用外部表,請考慮將它們升級到 BigLake 表以利用上述新功能。如需更多資訊,請聯繫 Google 雲客戶團隊,了解 BigLake 如何為您的資料平台增值。