本篇文章將以「monitoring」、「logging」為分類,逐步教學如何在 Windows 及 Linux 上安裝 Stackdriver agent,以及如何在 Stackdriver 上新增快訊政策 (Alert Policy)。
在 Windows 上安裝 Stackdriver agent
Stackdriver monitoring on Windows:
- RDP 連進 Windows server
- 若有使用 HTTP proxy,須先以 administrator 身份執行以下指令以設定 http_proxy 環境變數:(假設 HTTP proxy 位址為 YOUR-PROXY)
- setx http_proxy http://YOUR-PROXY /m
- 至 https://repo.stackdriver.com/windows/StackdriverMonitoring-GCM-46.exe 下載並安裝 agent installer
註:參考文件
Stackdriver logging on Windows:
- RDP 連進 Windows server
- 若有使用 HTTP proxy,須先以 administrator 身份執行以下指令以設定 http_proxy 環境變數:(假設 HTTP proxy 位址為 YOUR-PROXY)
- setx http_proxy http://YOUR-PROXY /m
- 至 https://dl.google.com/cloudagents/windows/StackdriverLogging-v1-8.exe 下載安裝檔,並將檔案搬移到 C:\Users[USERNAME] (假設登入使用者名稱為 USERNAME),搬移後執行安裝檔
註:參考文件
在 Linux 上安裝 Stackdriver agent
Stackdriver monitoring on Linux server:
- 執行下列指令:
curl -sSO https://dl.google.com/cloudagents/install-monitoring-agent.sh sudo bash install-monitoring-agent.sh - 如果有使用 HTTP proxy,則需額外將 Stackdriver 的設定檔中的 PROXY_URL 修改為您的 HTTP proxy URL
(1) Debian / Ubuntu 設定檔位置在 /etc/default/stackdriver-agent
(2) Amazon Linux / Red Hat / CentOS 設定檔位置在 /etc/sysconfig/stackdriver
(3) 修改設定檔後需以以下指令重啟 agent:
sudo service stackdriver-agent restart
註:參考文件
Stackdriver logging on Linux server:
執行下列指令即可:
curl -sSO "https://dl.google.com/cloudagents/install-logging-agent.sh"
sudo bash install-logging-agent.sh
新增快訊政策 (Alert Policy)
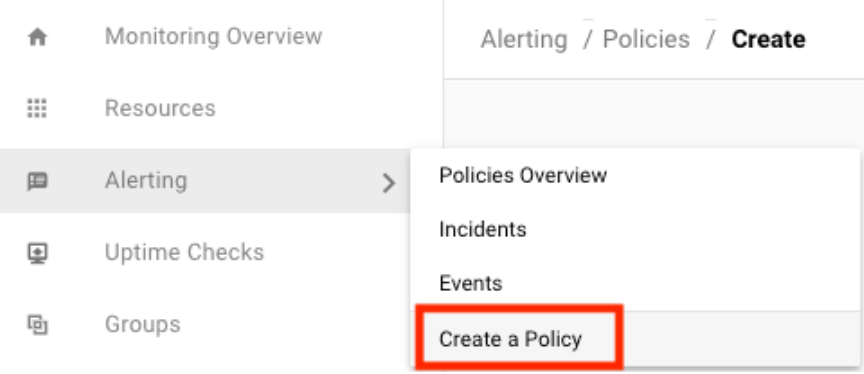
點選左邊導覽列的 Alerting → Create a Policy,選取新增判斷方式。
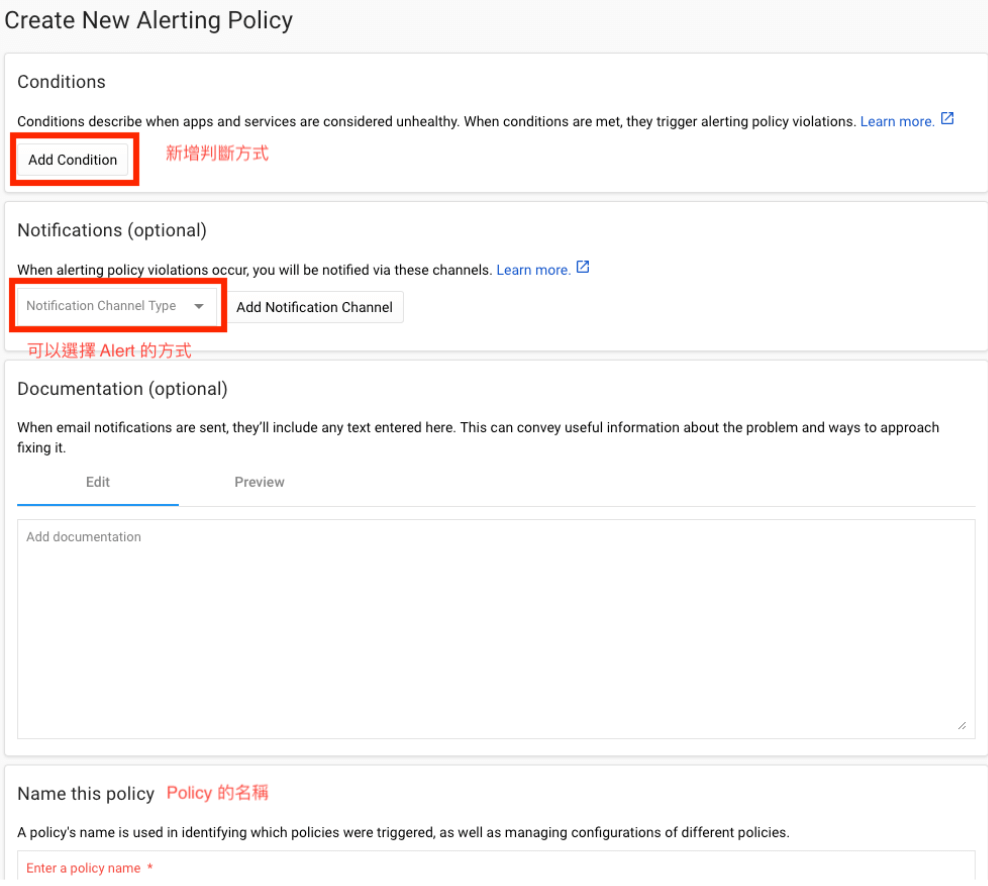
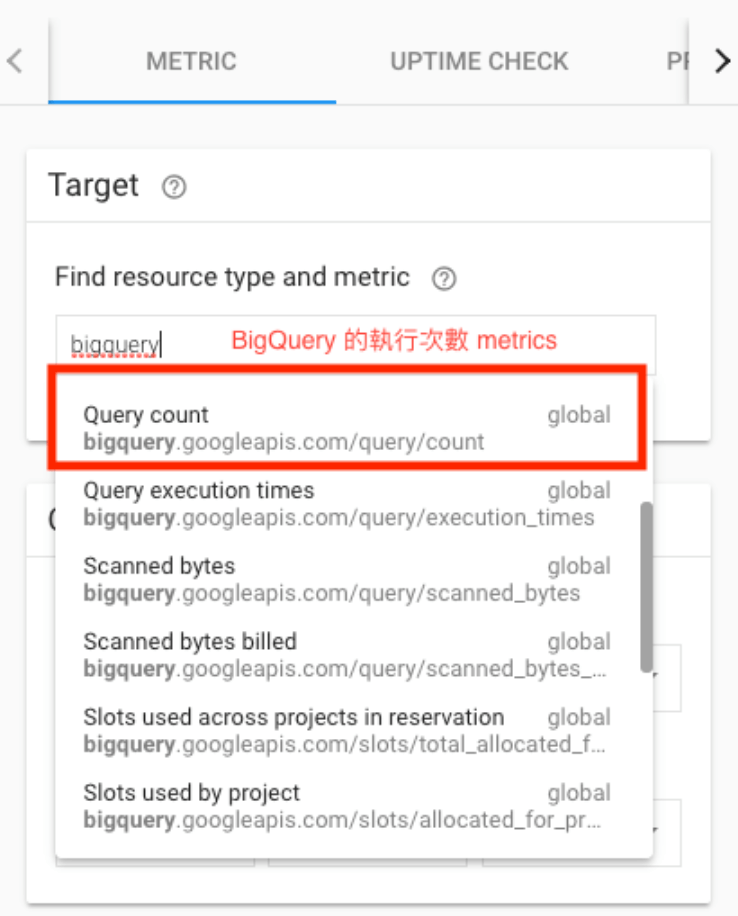
選取要監控 resource type 以及 metric。
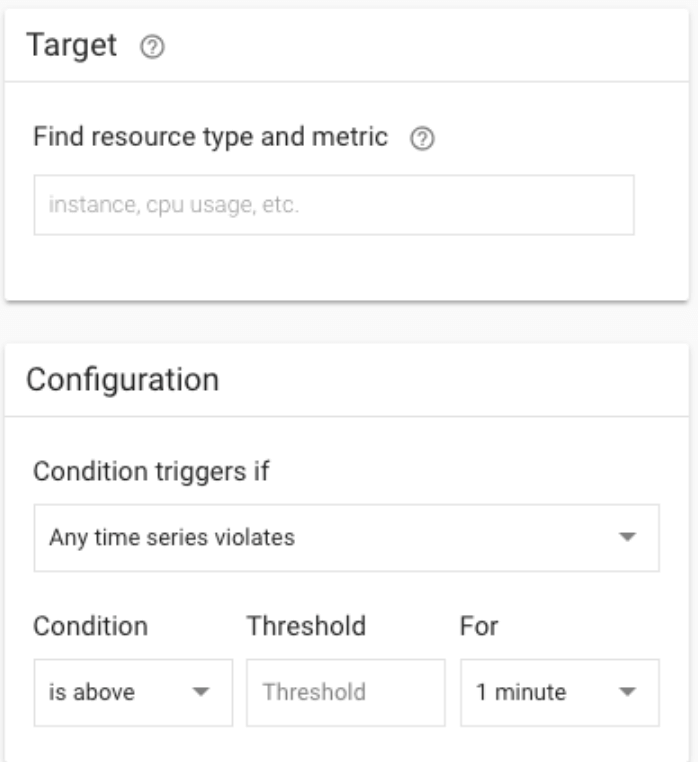
這邊以 BigQuery 的 Query 次數為例。
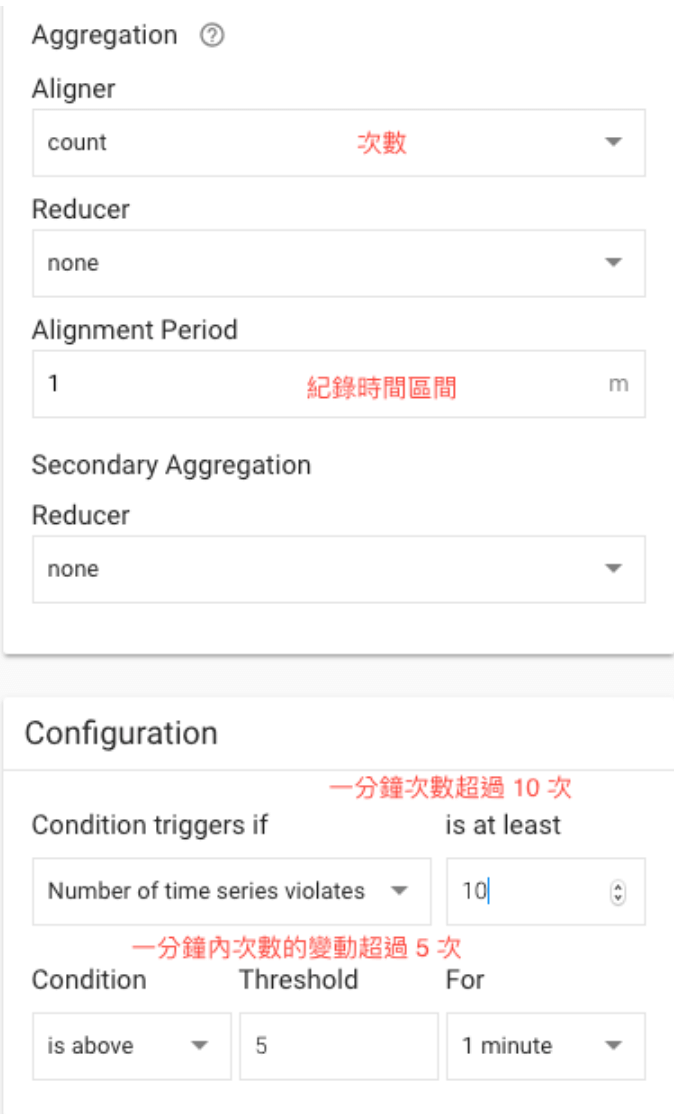
設定完參數後,點選儲存。
新增 Monitoring Chart
Chart 可以顯示任何使用者 project 收集到的 metrics,包括 custom metrics。在新增 Chart 之前需要先確認使用者有 roles/monitoring.editor 的 IAM 權限。
先創立一個新的 Dashboard。
點選位於右上角的 Add Chart。
輸入 chart 的名稱並選取監控的 metrics,這邊以 GCE VM instance 的 CPU usage 為例。
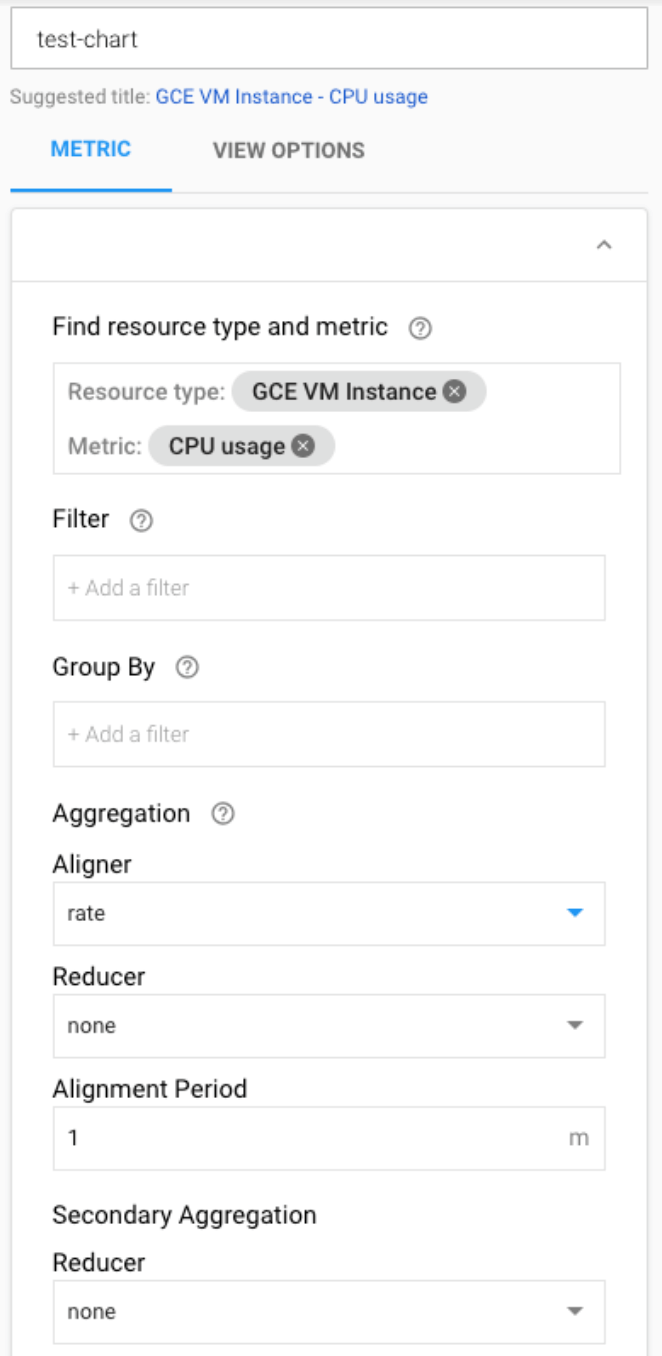
點選 Save 即創建完畢。
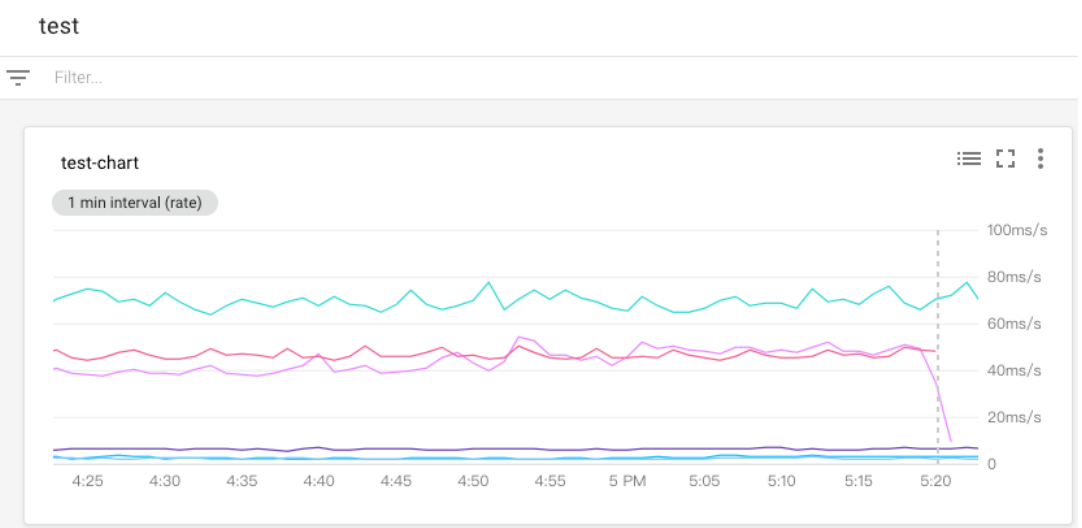
新增 Uptime Checks
左邊導覽列選取 Uptime Checks → Uptime Checks Overview。
選取右上角的 Add Uptime Check。
填入 Uptime Check 的格式。
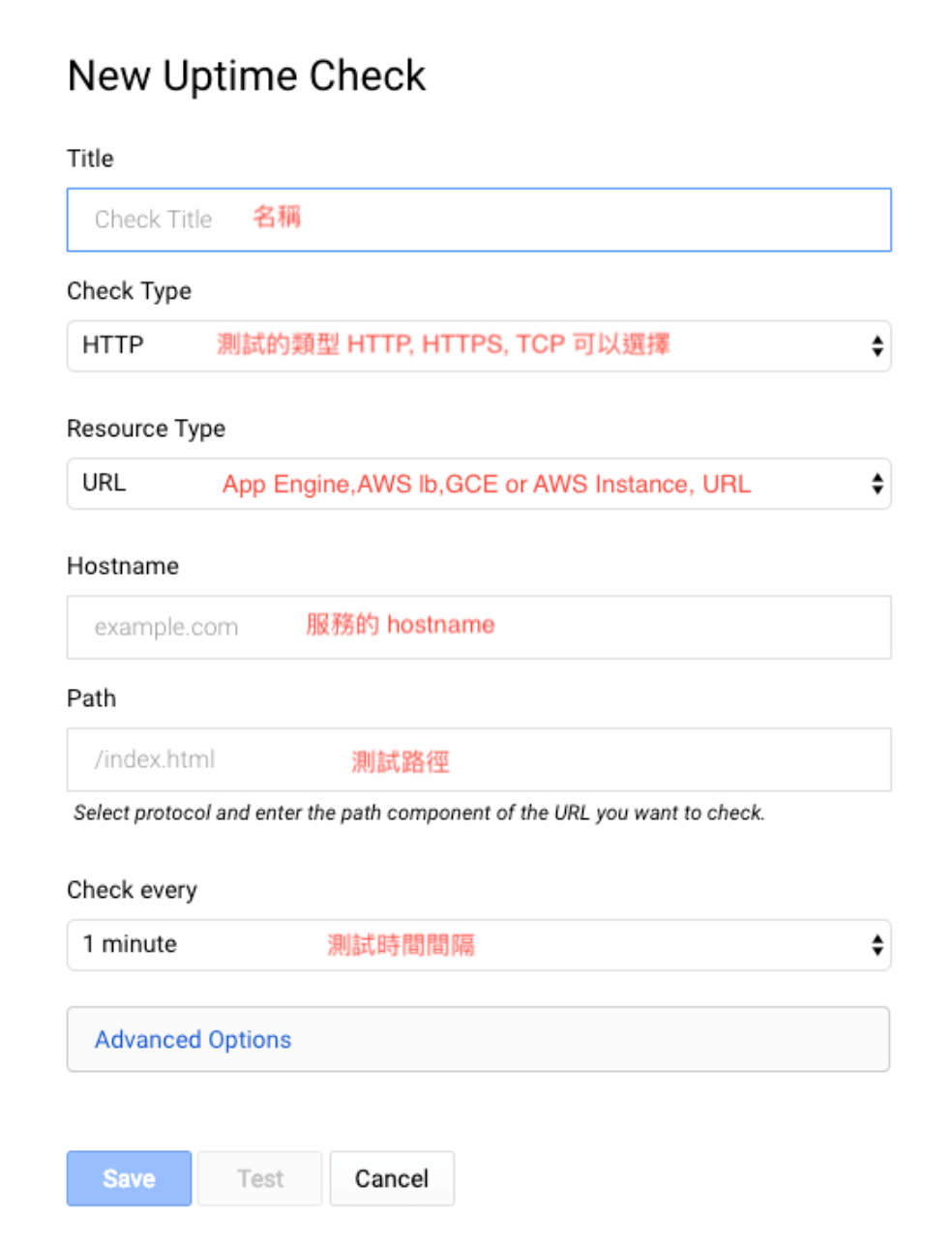
填寫完畢後按 Save 即新建完畢,創建完畢後需要等待一段時間才會開始有數據。並且可以針對該 Uptime Check 設定 Alert Policy,只需要點選右邊的鈴鐺即可。
