本文是多教程系列的第二部分,將展示如何透過 TensorFlow 和 Cloud ML Engine 部署機器學習 (ML) 推薦系統。在這個單元中,您將學習到:如何使用 GCP 中的 Cloud ML Engine 來訓練推薦系統,並調整其中的超參數。
這系列包括以下部分:
- 總覽
- 建立模型 (一)
- 如何在 TensorFlow 部署推薦系統:訓練和調校 Cloud ML Engine (二) (本教程)
- 運用 Google Analytics 數據 (三)
- 部署推薦系統 (四)
請先您閱讀系列教程的前一篇文章。
目標﹕
- 了解如何在雲端 Cloud ML Engine 執行訓練步驟,以執行 MovieLens 資料集的建議。
- 調校 Cloud ML Engine 的超參數,為 MovieLens 資料集提供最佳化 TensorFlow WALS 加權交替最小平方法的推薦模型。
成本
本文將使用 Google Cloud Storage (GCS) 和 Cloud ML Engine 兩項計費服務。您可以使用 GCP 價格計算機來預估專案的使用成本,本教程預計使用 0.20 美元的專案成本,如果您是 GCP 的新用戶則有機會獲得免費試用。
開始之前
按照第 1 部分中的指示來設定您的GCP專案。
訓練模型﹕
第一個教程帶您回顧如何實踐 TensorFlow 的 WALS 算法。 本文將讓您了解如何使用 Cloud ML Engine 訓練模型。 「訓練模型」意味著將評分 R 的稀疏評分矩陣,拆解成為用戶因子矩陣 X 和項目因子矩陣 Y,其中所得到的用戶因子,被當成推薦系統的基本模型。
您將會在此教程的第 4 部分學會如何在 GCP 上部署推薦系統。
在 Cloud ML Engine 上訓練
使用 Cloud ML Engine 訓練模型需要指定作業目錄,即 Cloud Storage bucket 資料夾; 而 mltrain.sh script 包含一個名為 BUCKET 的變量,用於雲端儲存 GCS Bucket。要執行訓練程序,請執行以下步驟:
1. 在你的專案中建立新的 bucket,或使用現有 bucket。
若要建立新的 bucket,請在 GCP 主控台中選擇「Cloud Storage」>「Browser」,然後點擊「Create Bucket」。請記好 bucket 的名字,若能把 bucket 放在與 Compute Engine 執行個體相同的地區 (region) 中會更好。
2. 使用文字編輯器打開 mltrain.sh 的 script,然後將 bucket 變數設定為你要使用的 bucket 名稱。
BUCKET=[YOUR_BUCKET_NAME]
3. 使用 gsutil 工具將 MovieLens 資料集複製到 bucket:
gsutil cp -r data/u.data gs://$BUCKET/data/u.data
gsutil cp -r data/ratings.dat gs://$BUCKET/data/ratings.dat
gsutil cp -r data/ratings.csv gs://$BUCKET/data/ratings.csv
4. 透過執行訓練 script 工作來設定訓練 train 項目,並將雲端儲存體 URL 指定給資料檔。您使用的資料集取決於您在第 1 部分所用到的,可以設定適用於資料檔案的其他選項,像是分隔符號或標頭:
- 對於 MovieLens 100k 資料集,請指定 100k 資料檔案的路徑:
./mltrain.sh train gs://$BUCKET/data/u.data - 對於 1m 資料集,請包含 –delimiter 選項並指定 1m 資料檔案的路徑:
./mltrain.sh train –delimiter :: gs://$BUCKET/data/ratings.dat - 對於 20m 資料集,請使用 –delimiter 和 –header 選項:
./mltrain.sh train –delimiter , –header gs://$BUCKET/data/ratings.csv
您可以在 GCP 主控台內 ML Engine 區塊 Job 頁面來監控工作的狀態和輸出。點擊 Logs 可以查看工作的輸出,結果記錄是測試集上的均方根誤差 (RMSE)。 RMSE 代表整個測試級距中預測用戶等級模型的平均誤差。
儲存模型
在因式分解之後,因子矩陣會以 numpy 格式分別保存在五個獨立的檔案中,因此它們可以做出機器學習推薦。 本教程集的第 3 部分將介紹模型文件,並向您展示如何使用它們來輸出機器學習化的推薦。 第 4 部分將介紹如何部署生產系統以執行機器學習推薦。 如果在本地端訓練模型時,檔案將保存在程式碼套件內的 jobs 資料夾中。如果在雲端Cloud ML Engine訓練模型時,如同上一節所描述,檔案將保存在雲端儲存GCS Bucket中,由Cloud ML Engine工作的 job-dir 參數來提供目錄。
MovieLens 資料集結果
矩陣因式分解近似值的結果,是基於測試集的預測評分,在預處理期間從評分矩陣中提取測試集。 要計算預測評分與實際用戶提供的測試集評分之間的差異,請使用第 1 部分中概述的損失公式:
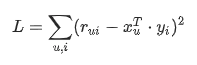
在這裡,rui 是測試集評分,xu 和 yi 是計算的行和列因子,將WALS 因子分解應用於 訓練集。
矩陣因式分解的性能與多個超參數高度相關,這些參數將在下一部分中詳細討論。使用表 1 中的 1m MovieLens 資料集和預設的超參數列,在測試集上 RMSE 達到了 1.06。RMSE 相當於預測評分中的平均誤差用來與測試集相比。平均而言,在 1m 資料測試集中,由演算法產生的每個評分落在實際用戶評分 ±1.06 的範圍之內。用戶定義的等級 3 可能會產生 2 到 4 之間的預測等級,但不太可能產生 1 或 5。雖然這結果並不差,但是該資料集的公佈結果實現了小於 1.0 的 RMSE。
如果要改善結果,必須調整表 1 中列出的超參數。
| 超參數名稱和描述 | 預設值 | 量測值 |
| latent_factors
Number of latent factors K |
5 | UNIT_REVERSE_LOG_SCALE |
| regularization
L2 Regularization constant |
0.07 | UNIT_REVERSE_LOG_SCALE |
| unobs_weight
Weight on unobserved ratings matrix entries |
0.01 | UNIT_REVERSE_LOG_SCALE |
| feature_wt_factor
Weight on observed entries |
130 | UNIT_LINEAR_SCALE |
| feature_wt_exp
Feature weight exponent |
1 | UNIT_LOG_SCALE |
| num_iters
Number of alternating least squares iterations |
20 | UNIT_LINEAR_SCALE |
表1. 模型中使用的超參數名稱和預設值
調整超參數
找到最佳的超參數集對於機器學習模型的性能非常重要,可惜在這部分能夠引導的理論很少。資料科學家不得不在合理的範圍內測試各種數值進行優化、測試模型的效能與結果,最後再選出具有最佳性能的參數組合。就人力工時及計算資源而言,這是非常耗時且成本昂貴。 可能的超參數組合空間基於模型中的不同參數的數量呈指數增長,所以要搜索整個空間是不可行的,這會迫使您根據先前經驗以及每個參數的數學屬性而啟發,對影響模型的因素做出假設。
Cloud ML Engine 包含一個超參數的調整功能,可自動搜索一組最佳超參數。要使用調整功能,您需要提供待調整的超參數列表,以及這些參數的預期範圍或值。Cloud ML Engine 在超參數空間上執行搜索,根據您的喜好執行多個不同的試驗,在所有試驗中找到的性能最佳的超參數的排序結果列表然後回傳。您可以提供假設的量測值,像是參數、對數或線性,作為搜尋過程中額外的提示。
有關超參數調整的更多信息,您可以請參考 Cloud ML Engine 文件。更多關於超參數調整的深層的演算法,請參考部落格文章﹕使用貝葉斯優化在 Cloud ML Engine 中的超參數調整。
超參數設定文件
可以在 JSON 或 YAML 設定檔案內提供 Cloud ML Engine 的超參數列表。在本文的範例程式碼中,超參數調整設定由 config / config_tune.json 所定義。本文所調整每個超參數都列在此檔案中,包含最小/最大範圍和量測值。關於有效的參數量測值,請參考超參數調整概述。
standard_gpu 機器類型會在 scaleTier 參數中指定,因此在 GPU 配置的機器上進行調整,以下是設定檔案的範例:
{
"trainingInput": {
"scaleTier": "CUSTOM",
"masterType": "standard_gpu",
"hyperparameters": {
"goal": "MINIMIZE",
"params": [
{
"parameterName": "regularization",
"type": "DOUBLE",
"minValue": "0.001",
"maxValue": "10.0",
"scaleType": "UNIT_REVERSE_LOG_SCALE"
},
{
"parameterName": "latent_factors",
"type": "INTEGER",
"minValue": "5",
"maxValue": "50",
"scaleType": "UNIT_REVERSE_LOG_SCALE"
},
{
"parameterName": "unobs_weight",
"type": "DOUBLE",
"minValue": "0.001",
"maxValue": "5.0",
"scaleType": "UNIT_REVERSE_LOG_SCALE"
},
{
"parameterName": "feature_wt_factor",
"type": "DOUBLE",
"minValue": "1",
"maxValue": "200",
"scaleType": "UNIT_LOG_SCALE"
}
],
"maxTrials": 500
}
}
}
超參數調整程式碼
訓練模型的程式碼包括下列功能,允許超參數進行調整:
- 每個超參數都傳遞參數給Cloud ML Engine的超參數調整作業。在這種情況下,task.py 檔案作為整個調整作業的入口點,處理超參數傳遞作業。 您必須確保參數的名稱與設定檔案內超參數名稱列表相互匹配。
- 該模型使用特殊標記 training/hptuning/metric 來編寫 TensorFlow 摘要,該度量設定作為評估訓練模型品質的標準。在這種情況下,RMSE 是測試集度量。 此 summary 度量啟用 Cloud ML Engine 的搜尋作業,讓超參數調整服務能夠對試驗結果進行排名。在 util.py 中的應用函數中寫出 summary 度量值如下:
summary = Summary(value=[Summary.Value(tag='training/hptuning/metric',
simple_value=metric)])
eval_path = os.path.join(args['output_dir'], 'eval')
summary_writer = tf.summary.FileWriter(eval_path)
# Note: adding the summary to the writer is enough for hyperparam tuning.
# The ml engine system is looking for any summary added with the
# hyperparam metric tag.
summary_writer.add_summary(summary)
- 每個試驗都有一個單獨的輸出目錄很重要。 輸出目錄用於編寫 TensorFlow 摘要和保存的模型。如果不為每個試驗產生不同的輸出目錄,則每個試驗的結果將覆蓋先前試驗的結果。以下提供 task.py 程式碼透過 parse_arguments 方法,為每個試驗產生唯一的目錄:
if args.hypertune:
# if tuning, join the trial number to the output path
trial = json.loads(os.environ.get('TF_CONFIG', '{}')).get('task', {}).get('trial', '')
output_dir = os.path.join(job_dir, trial)
else:
output_dir = os.path.join(job_dir, args.job_name)
其中的 parse_arguments 函數用來區隔調校和標準輸出,搭配 output_dir 改變相對應的目錄。
執行超參數調整作業
使用以下命令在 100k 資料集執行調整作業:
./mltrain.sh tune gs://$BUCKET/data/u.data
請記得將 BUCKET 變數設定為您先前所產生的GCS Bucket。
調整後的結果
超參數調整的結果存儲在 Cloud ML Engine 的工作資料中,您可以從 GCP 主控台的 ML Engine 區域的「Job」頁面中進行存取資料。 如圖 1 所示,工作結果包括最佳的 RMSE 分數,依據所有試驗的 summary 度量標準。您可以從 100k MovieLens 資料集查看 500 次試驗超參數調整的結果,最佳的調整結果發生在第 384 次試驗中。
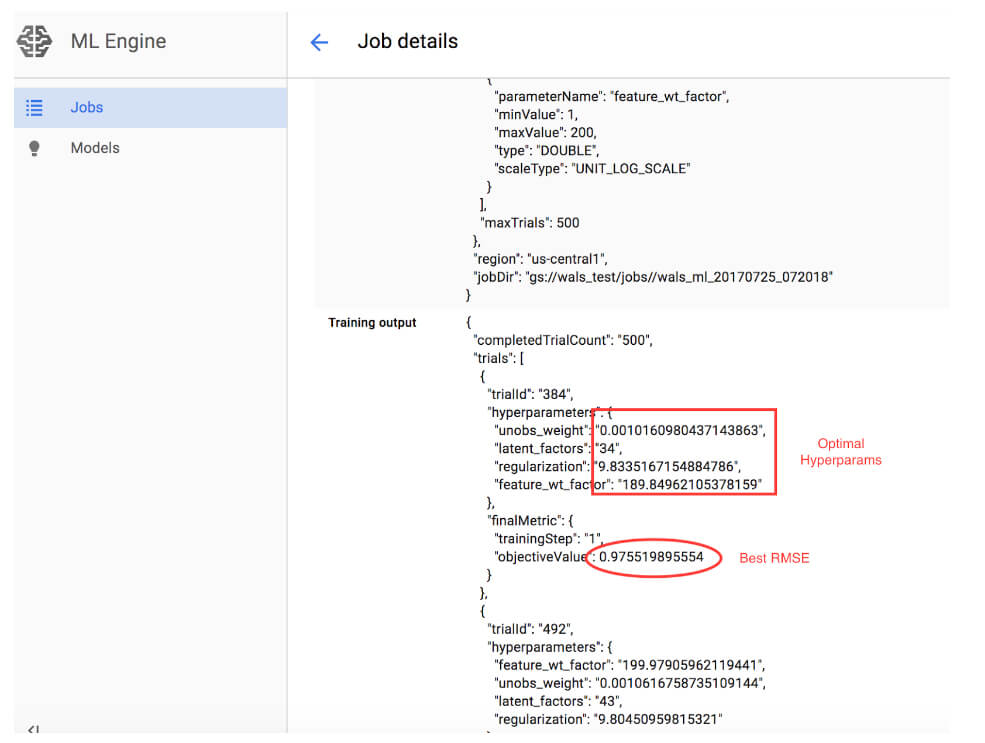
(圖1) 超參數調整工作的結果
超參數調整可以在最終結果中產生很大的差異。在這個案例中,100ktest 集合的超參數調整達到 0.98 的 RMSE。將這些參數套用於 1m 和 20m 資料集,所產生的 RMSE 值分別為 0.90 和 0.88。最佳化的參數列於表 2 ,調整前後的 RMSE 值彙整於表 3 之中。
| 超參數名稱 | 描述 | 調整後的值 |
| latent_factors | Latent factors K | 34 |
| regularization | L2 Regularization constant | 9.83 |
| unobs_weight | Unobserved weight | 0.001 |
| feature_wt_factor | Observed weight | 189.8 |
| feature_wt_exp | Feature weight exponent | N/A |
| num_iters | Number of iterations | N/A |
(表2) Cloud ML Engine 超參數調整後發現的值
特徵加權指數不是調整參數的一部分,因為線性觀察加權用於 MovieLens 資料集,預設值使用迭代次數參數 num_iters。
| 資料集 | RMSE 與預設的超參數 | 經超參數調整後的 RMSE |
| 100k | 1.06 | 0.98 |
| 1m | 1.11 | 0.90 |
| 20m | 1.30 | 0.88 |
(表3) 在超參數調整前後,針對不同 MovieLens 資料集測試 RMSE 值的摘要。
下一步
下一個教程:如何在 TensorFlow 部署推薦系統:運用 Google Analytics 資料 (三),將介紹推薦系統模型如何應用於 Google Analytics 的即時
(原文翻譯自 Google Cloud。)