在這篇文章中,我們將重點介紹 DevOps 團隊如何使用 Cloud Monitoring 和 Cloud Logging 來快速釐清問題。
比起耗費心力維運一個安全、可擴展且高可用 (HA) 的 Kubernetes 叢集,使用 Google Kubernetes Engine(以下簡稱 GKE)運行容器化應用程式更能讓 DevOps 團隊專心在應用程式開發上。Cloud Logging 以及 Cloud Monitoring 為兩項整合進 GKE 的監控服務,DevOps 團隊透過這兩項服務,可以更好地觀察應用程式和系統,以便在出現問題時更容易進行故障排除。
使用 Cloud Logging
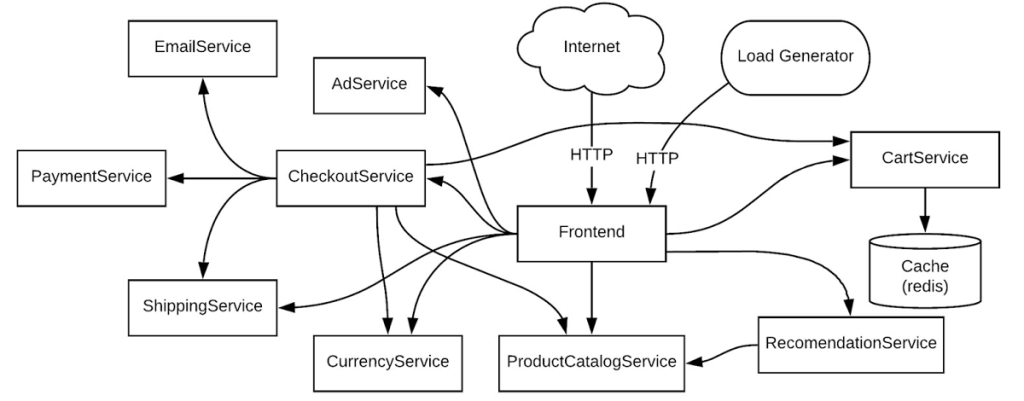
讓我們來看一個簡單而又常見的範例。作為 DevOps 團隊的一員,您從 Cloud Monitoring 收到了正式環境 Kubernetes 叢集的應用程式錯誤告警。您需要排查這個錯誤。以下,我們將使用一個微服務應用程式當作範例,來進行我們實際的問題排查。在這個範例中,有許多微服務及其彼此之間的依賴關係。
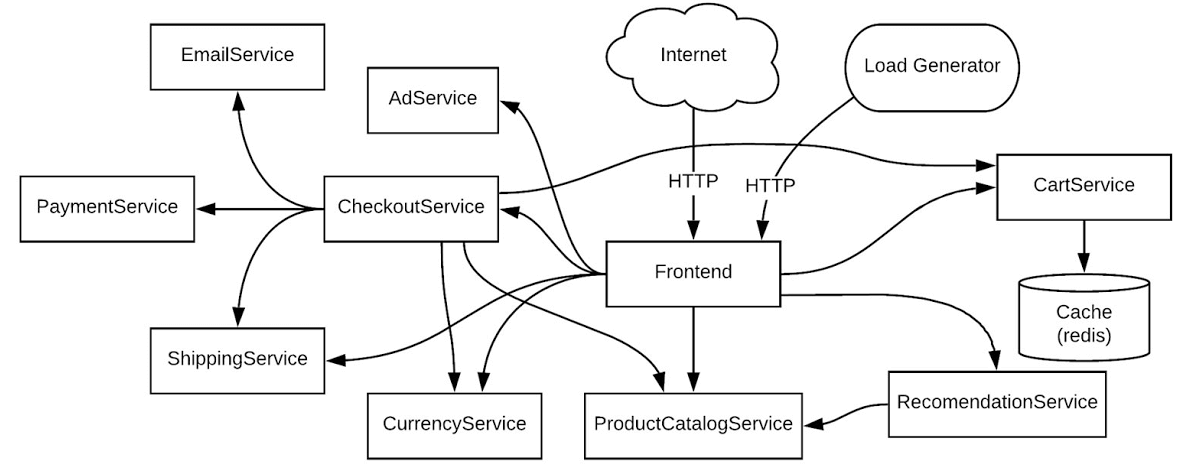
在這個例子中,你可以想像此應用程式是在 staging 環境中、共享於多個團隊,或你也可以想像是在 production 環境中、運行多個工作負載。我們將逐步排除一個簡單的錯誤。
假設現在有一個事件是由大量的 HTTP 500 錯誤所觸發。您可以根據日誌 (log) 事件的數量或日誌的內容來建立一個用於告警的 logs-based metric。Cloud Monitoring 提供了告警機制,使用者可以透過此告警機制設定通知的 email、SMS 或是在第三方應用程式中產生通知。
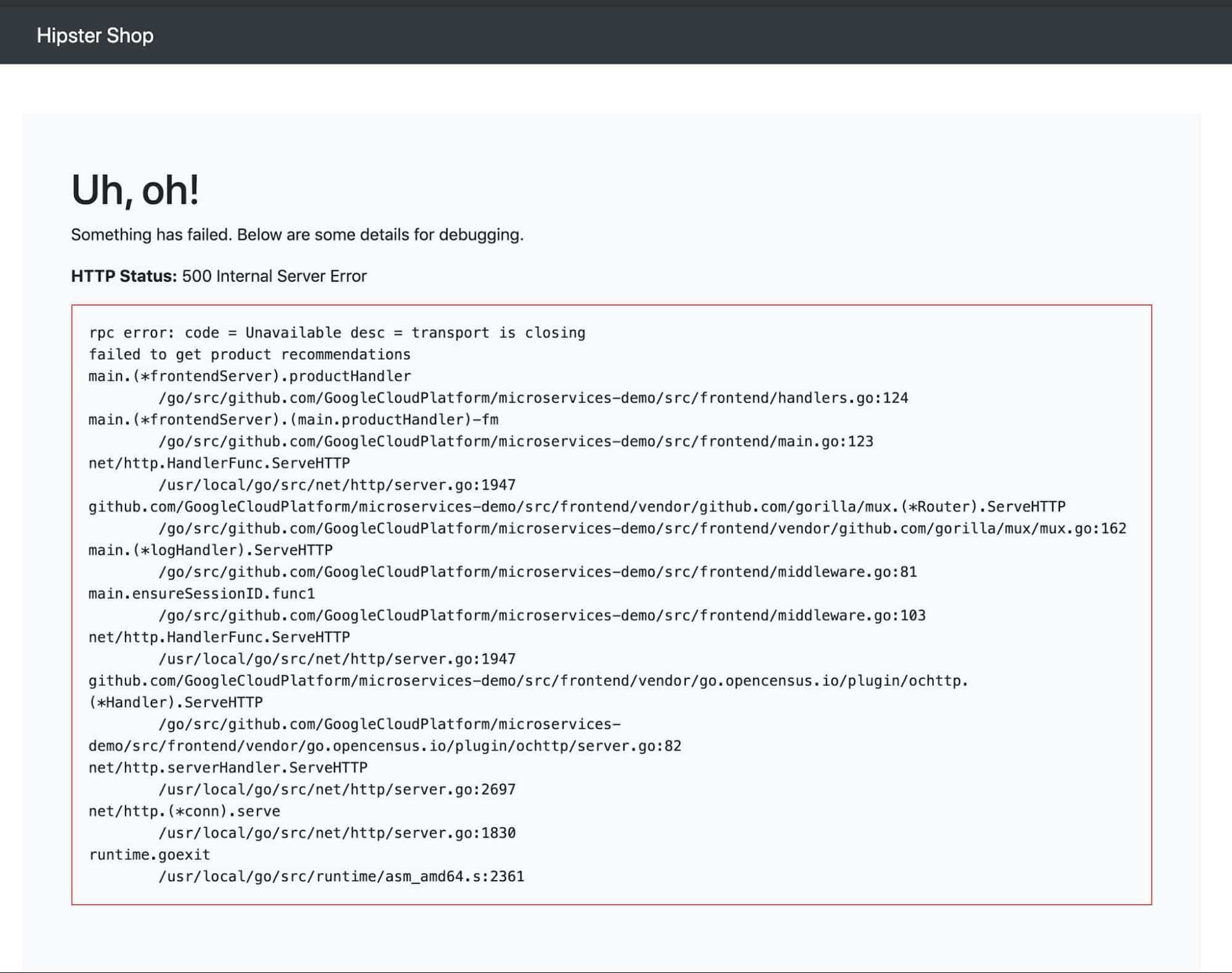
在範例中,假定 HTTP 500 的錯誤訊息如下:
如果您已經在 Cloud Monitoring 中建立了相關的告警機制,您將收到類似以下的通知:
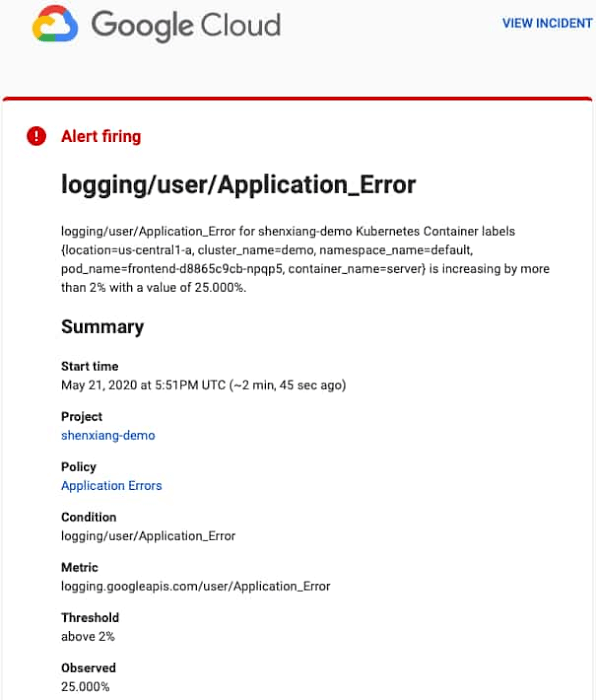
您可以透過過點擊 “VIEW INCIDENT” 連結去查看事件的詳情。透過告警通知中的連結,你就能開啟 Cloud Monitoring 的 UI 介面。
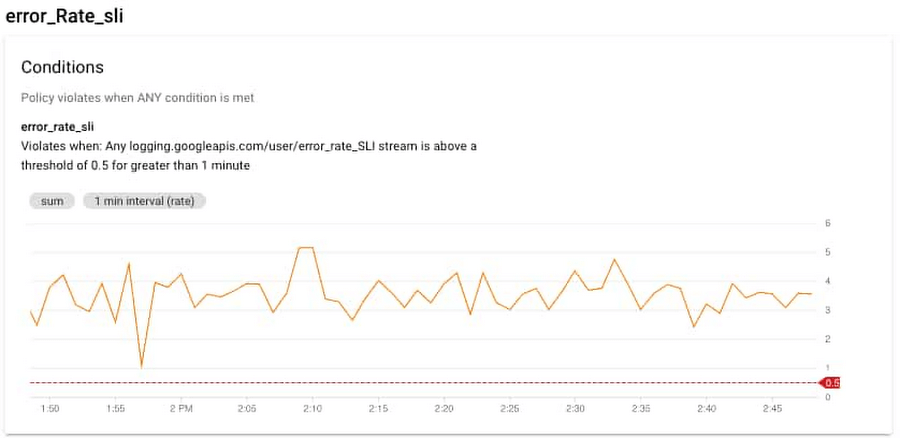
您可以先前往 Cloud Monitoring > GKE dashboard,來進行初步的錯誤排查。透過此介面,您可以選定特定 GKE 叢集並查看叢集中正在運行的 Pods 或是 Containers。在這個案例中,您可以看到 recommendationservice 的 Pod 和 Container 的 CPU 使用率非常高,這可能意味著 recommendationservice 已經超載,無法回應來自前端的請求。在理想情況下,您還可以為容器的 CPU 和記憶體使用率設置一個告警條件,在這情況下也會發送告警。
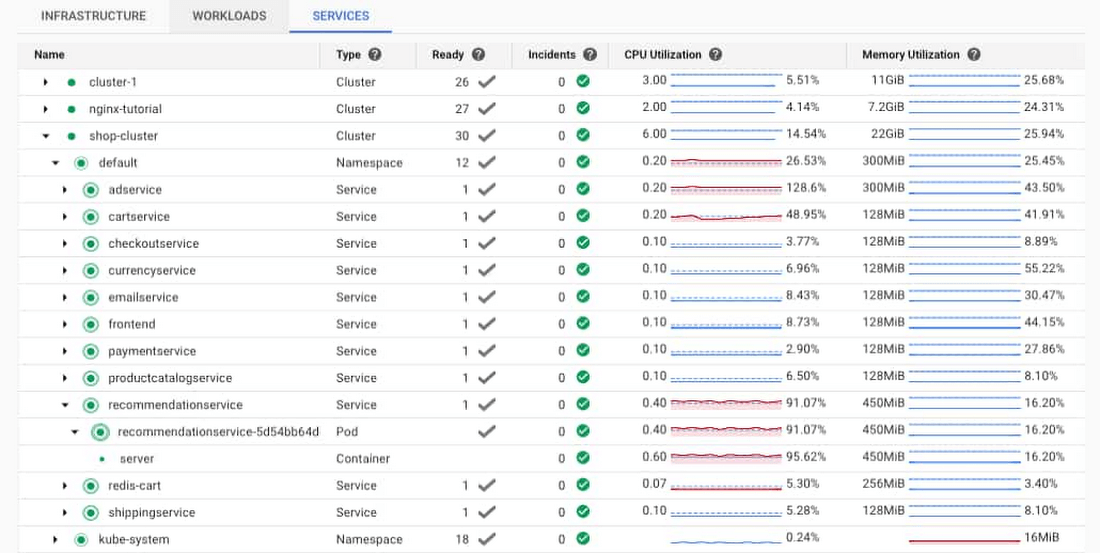
打開 recommendationservice GKE Service 或 pod 下的 server container 連結,會顯示 container 的詳細資訊,包括記憶體和 CPU 等指標,以及相關日誌。在右方區塊會顯示 Container 的詳細資訊。您可以點擊右上角的 “MANAGE” 按鈕連結至 GKE console 的 Pod 資訊。
由於 Cloud Monitoring 已經整合進 GKE console,所以您可以很輕易地查看 Pod 的各項監控數據。您可以看到左下角的那張圖,藍色的線為 Requested 的 CPU 量,而紫色的線則是實際使用情況。可以推斷出 CPU 時常超出 requested 的 CPU。您也可以從監控圖中看到,記憶體和硬碟的使用率並不高,因此可以排除這兩項指標。在這種情況下,CPU可能是問題所在。
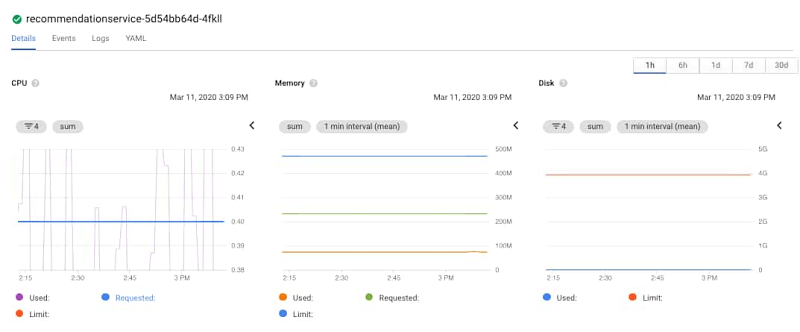
點擊 Container,您可以看到 requested 的 CPU、記憶體以及 deployment 的詳細資訊。

您還可以點擊「Revision History」連結來查看 Container 的編輯紀錄,您可以看到最近有一個新版本的 deployment。

根據初步排查的資訊,我們可以檢查看看為什麼會需要額外的 CPU 使用量。由於 HTTP 500 錯誤是來自於前端的 Pod,您可以查看該工作負載的相關日誌。要查看日誌,請點擊 Container 日誌連結,您將會開啟 Cloud Logging UI,系統將事先過濾選取的 Container 的相關日誌。
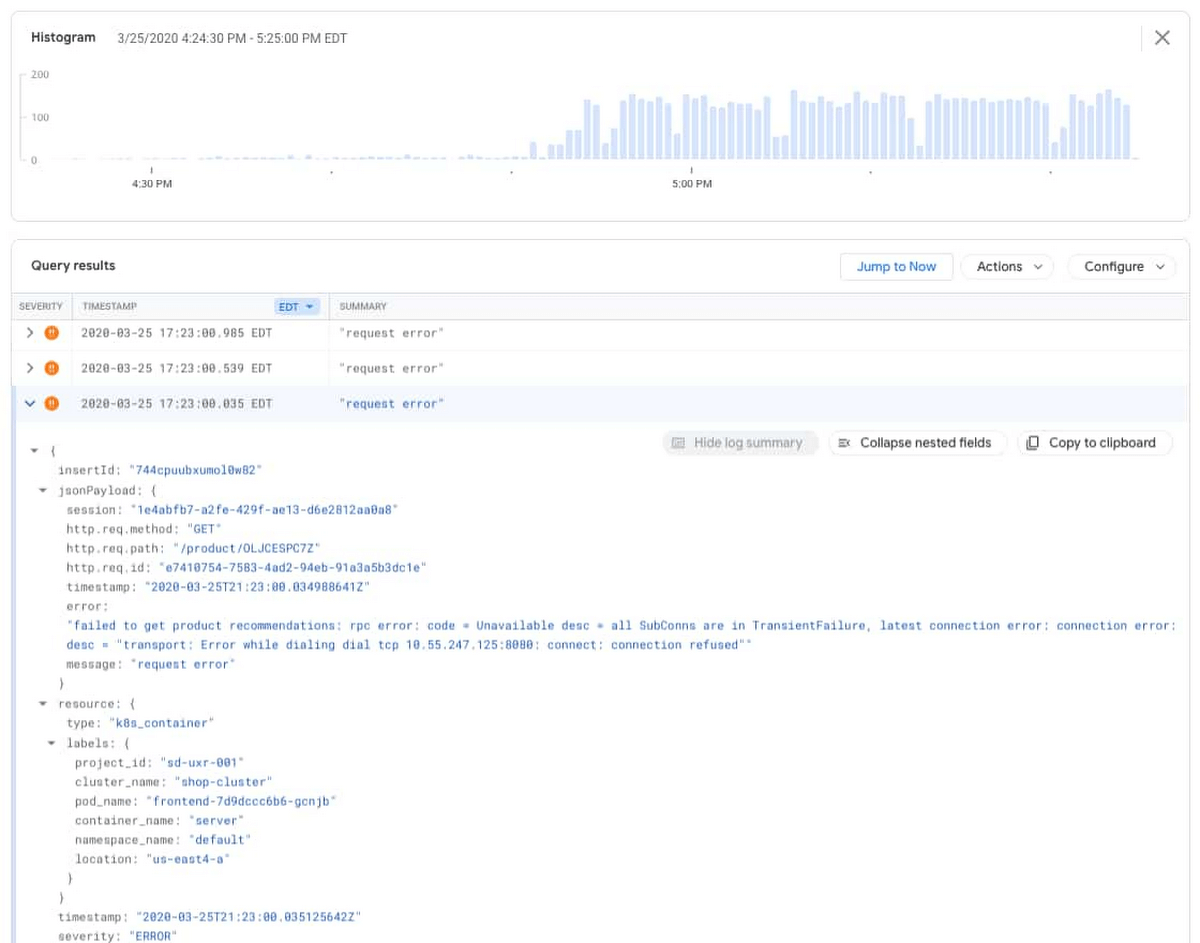
在 Logs Viewer 中,您可以看到詳細的查詢、日誌的直方圖和獨立的日誌條目。直方圖功能提供了特定時間內的日誌條目發生頻率及內容,是個可以幫您釐清應用程式問題的強大工具。您可以看到錯誤條目在下午 4:50 左右開始增加。
展開錯誤條目就會看到下面的日誌資訊。
“failed to get product recommendations: rpc error: code = Unavailable desc = all SubConns are in TransientFailure, latest connection error: connection error: desc = "transport: Error while dialing dial tcp 10.55.247.125:8080: connect: connection refused"
這與前端 pod 服務的 HTTP 500 錯誤相匹配。現在調整日誌過濾器來查看 recommendationservice pod 日誌,以顯示帶有 recommendations 名稱的錯誤條目。下面的過濾器將顯示資源類型為 Container 且 Pod 的前綴為 recommendations 的錯誤條目。
resource.type="k8s_container"
resource.labels.project_id="YOUR_PROJECT"
resource.labels.location="us-east4-a"
resource.labels.cluster_name="shop-cluster"
resource.labels.namespace_name="default"
resource.labels.pod_name:"recommendations"
severity=ERROR
調整過濾器以查看非錯誤日誌條目。
resource.type="k8s_container"
resource.labels.project_id="YOUR_PROJECT"
resource.labels.location="us-east4-a"
resource.labels.cluster_name="shop-cluster"
resource.labels.namespace_name="default"
resource.labels.pod_name:"recommendations"
severity=!ERROR
您可以在日誌直方圖中看到有日誌條目從服務中產生,這可能意味著服務仍在接收和回應一些請求。
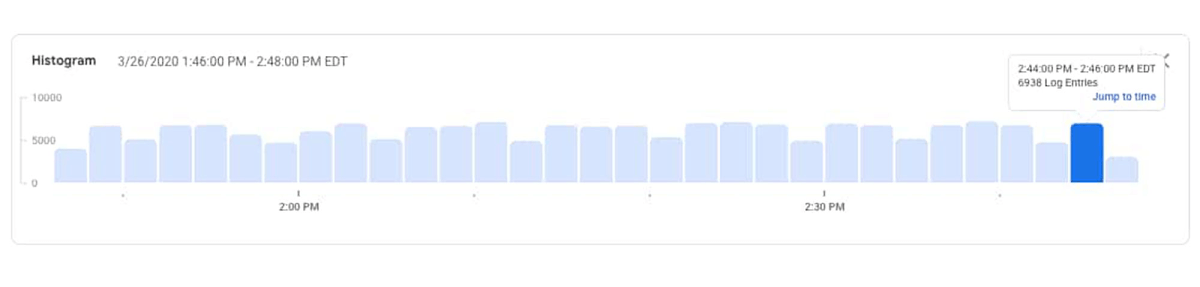
由於在日誌中,recommendationservice 沒有產生任何錯誤,這有助於確認並懷疑最新一次的程式部署存在問題,導致它比以前使用更多的 CPU。有了這些資訊,您就可以採取行動了。您可以增加 Container YAML中的 CPU request,或者 roll back 最近對 recommendationservice 的更新,並聯繫負責該服務的開發人員去審視 CPU 使用率增加的原因。具體的操作取決於您對程式、最近的部署、您的組織及政策的理解。無論您採取哪種方案,您都可以繼續使用 Cloud Logging 和 Monitoring 去監控叢集發生的錯誤事件。
(原文翻譯改編自 Google Cloud。)