Cloud SQL 為 GCP 全代管的關聯式資料庫服務,可以協助用戶輕鬆在雲端建立、維護和管理 PostgreSQL、MySQL 和 SQL Server 資料庫。以下是許多用戶在使用上常遇到的問題。
常見問題
Q:Cloud SQL 一年維護幾次?
A:依照 iKala 我們自己使用的經驗,目前是一季 (三個月) 會有一至兩次的例行性維護,但是官方並沒有表明是幾次。
Q:是否可以設定不要維護?
A:例行維護是強制的,不可以不啟用,但可以自訂維護時段。定期維護是因為 GCP 需要確保 Cloud SQL 執行個體更新最新的 security patch。
前往 GCP console > SQL,並選取欲設定維護時段的執行個體並點選「編輯」。

![]()
自訂維護時段是透過以下方式指定,如下圖:
- 指定 星期一~星期日 某一天
- 指定 當天的某一個小時
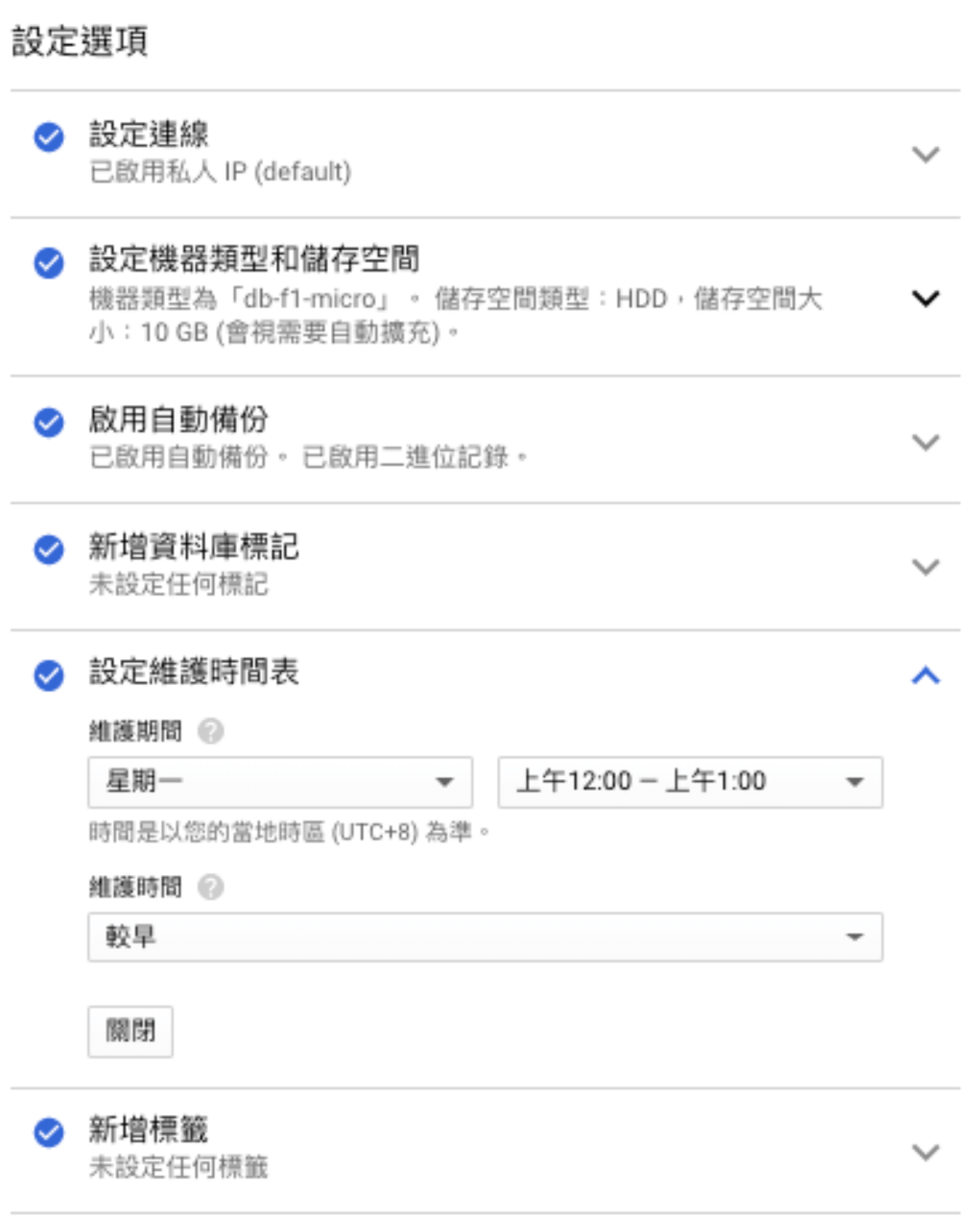
注意,不能指定「特定日期」進行例行維護,所以事先不會知道確切哪一天會進行例行維護。
Q:維護會事先通知嗎? 若無法,我們是否有方法可以事先知道?
A:事先不會知道確切哪一天會進行例行維護。不過,的確有方法可以知道 Cloud SQL 快要進行例行維護了。以下提供設定通知的方法:
有一個 workaround 可以事先知道「快要」進行例行維護了,做法是透過以下方式
- 將生產環境 (production) Cloud SQL 實例的例行維護設定中的「維護時間」選取 later (較晚)
- 額外新增一個 Cloud SQL 實例 (此實例需要與生產環境中的實例位於同一個 project)
- 將例行維護設定中的「維護期間」跟生產環境的 Cloud SQL 實例的例行維護設定同一期間,也就是同一天同一時段。
- 將例行維護設定中的「維護時間」為 earlier(較早)。
- 透過 Stackdriver 設定對這個實例做監控,一發現實例下線就會發出告警。
注意,透過上述方法只能預知生產環境的 Cloud SQL「下一週」發生例行維護,不過用戶事先不會知道是下一週的確切的時機點會進行例行維護,只能知道是下一週所指定的「維護時間」會發生例行維護。


Q:維護時是否會斷線?服務是否會受影響?
A:自動例行維護會造成大約 3~5 分鐘的 downtime ,且例行維護造成的 downtime 在一小時內都是不計入 SLA[1] 的。
[1] https://cloud.google.com/sql/sla
Q:Cloud SQL 有 cluster 嗎?
A:Cloud SQL 有一寫 (master) 多讀 (slave) 的 cluster,多讀是透過新增多份 read replica。Cloud SQL 支援 master 節點的 HA[1],作法是透過新增一份 (不能多份,至多一份) failover replica。
[1] https://cloud.google.com/sql/docs/mysql/high-availability
Q:Cloud SQL 的自動備份可以匯出嗎?
A:不可以。 但可以手動透過 mysqldump 指令做備份,然後把備份匯出到 GCS[1]。
[1] https://cloud.google.com/sql/docs/mysql/import-export/exporting
Q:應用程式連接到 Cloud SQL 的方式有很多,建議使用哪一種?
A:一般來說建議使用 Cloud SQL Proxy 或 private IP 直連[1]。
[1] https://cloud.google.com/sql/docs/mysql/sql-proxy
Q:應用程式連接到 Cloud SQL 要透過 private IP 還是 public IP?
A:都可以。但需要注意的是如果 Cloud SQL 已經是 public IP 連線的話, 啟用 private IP 連線會有 downtime。另外 private IP 連線一經啟用後則無法停用[1]。
[1] https://cloud.google.com/sql/docs/mysql/private-ip#administration_considerations
Q:例行維護 downtime 無法避免的情況下,我的應用程式要怎麼設計?
A:應用程式必須設計成「可容許短暫性連不上資料庫」的狀況,要測試這個狀況可以手動重啟 Cloud SQL[1]。除此之外,建議應用程式使用「short-lived connections 搭配 exponential back-off for retrying rejected connections」連接 Cloud SQL[1]。
[1] https://cloud.google.com/sql/faq#maintenancerestart
Q:Replication lag 持續太高怎麼辦?
A:解決方法為限制流進 master instance 的流量或是 shard 資料庫[1] 但是因為 Cloud SQL 只支援 InnoDB 不支援 NDB 所以也就不支援 native sharding[2],所以如果需要做 shard 的話得自己在 client 端實現。[3]
可以監控 Cloud SQL 的 replication lag,並設置警報,當 replication lag 過高時發出警報[4]。
[1] https://cloud.google.com/sql/docs/mysql/operational-guidelines#replication-lag
[2] https://cloud.google.com/sql/docs/mysql/high-availability#replication-lag
[3] https://enterprise.google.com/supportcenter/managecases#Case/00160000012QNmP/U-17737875
[4] https://cloud.google.com/sql/docs/mysql/configure-ha#creating_an_alert_for_replication_lag
Q:Cloud SQL 出問題的時候多久會 failover?
A:60s + replication lag 所需的時間。
前面 60s 是指當 master node 或 master zone 失效導致 Cloud SQL 服務沒有反應長達 60s 就會觸發 failover 機制,觸發後還要等 failover replica 跟上原來 master node 的狀態才會完成切換。後面這段 replication lag 的時間不一定。[1]
[1] https://cloud.google.com/sql/docs/mysql/high-availability
Q:Cloud SQL 不預期停止後,要如何還原到半小時前的狀態?
A:Cloud SQL 無法運行後要回復到半個小時前的方式有兩個:
- 透過隨需備份[1],每半小時備份一次,之後可以透過備份還原到原來的執行個體[2]或其他的執行個體[3]。注意,備份時會影響資料庫效能。
- 透過「執行時間點」,之後必須找出「日誌檔案」和「紀錄位置」還原到新的 Cloud SQL 執行個體[4]。注意,必須能夠重新正常啟動原來的執行個體才適用這個方法。
以下是方法二的詳細說明:

透過「執行時間點」還原到特定時間點的方式依賴「二進位日誌檔」,所以必須先能夠重新帶起停止運行的 Cloud SQL 執行個體才有機會執行,而且不可以透過 read replica 或 failover replica,一定要是原來停止運行的 Cloud SQL 執行個體,因為 read replica 或 failover replica 都是「停用二進位日誌檔」的狀態。
還原到特定時間點的方式主要是透過「指定還原到二進位日誌檔的紀錄位置」建立新的 Cloud SQL 執行個體。只能指定「記錄位置」,不能指定「時間位置」,所以必須找出最接近半小時前的紀錄位置。
找出紀錄位置有兩步驟:
- 找出「二進位日誌檔」
- 找出「二進位日誌檔的紀錄位置」
步驟一 可以使用以下 SQL 指令查詢
mysql> SHOW BINARY LOGS;
步驟二 可以使用以下 SQL 指令查詢
mysql> SHOW BINLOG EVENTS IN ‘’ FROM LIMIT 100;
在步驟二中的查詢結果不包含紀錄時間,如果要得知每筆紀錄的時間可以使用 mysqlbinlog 來得知[5]
shell> mysqlbinlog -R -h [Cloud SQL IP] -u root -p [BINARY_LOG_FILE]
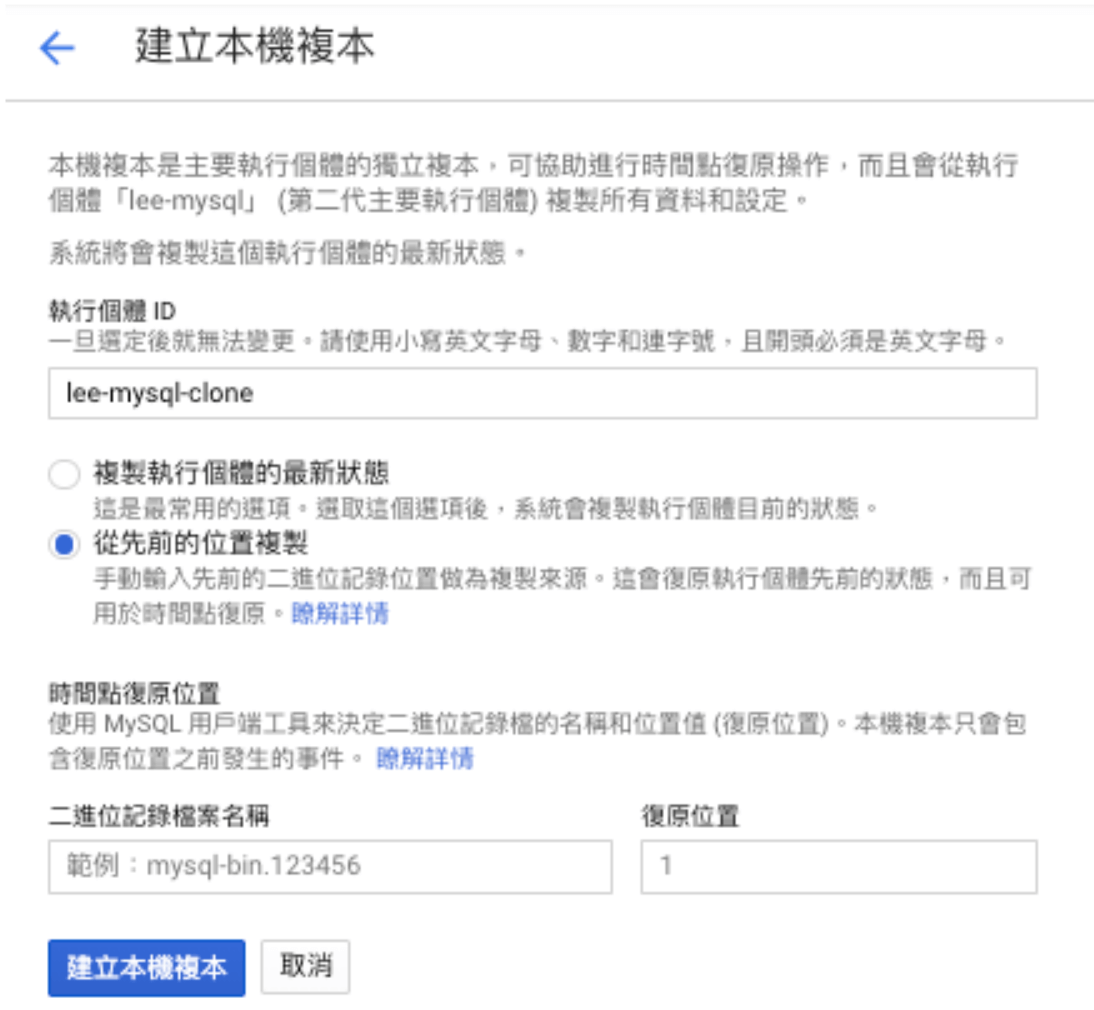
找到「記錄位置」後就可以依照以下步驟建立新的 Cloud SQL 執行個體。
前往 Google Cloud Platform 主控台的「Cloud SQL 執行個體」頁面。
前往 SQL 執行個體頁面。

開啟欲復原之執行個體的更多動作功能表並選取 [建立本機複本]。


如有必要,在「建立本機複本」視窗中,更新新執行個體的名稱。
選取 [從先前的位置複製]
輸入之前在「二進位檔記錄檔案名稱」中識別的二進位檔記錄名稱。
輸入要從「復原位置」修復之事件的位置。
按一下 [建立本機複本]。
[1] https://cloud.google.com/sql/docs/mysql/backup-recovery/backing-up#on-demand
[2] https://cloud.google.com/sql/docs/mysql/backup-recovery/restoring#restorebackups-same-instance
[3] https://cloud.google.com/sql/docs/mysql/backup-recovery/restoring#restorebackups-another-instance
[4] https://cloud.google.com/sql/docs/mysql/backup-recovery/restoring#pitr
[5] https://dev.mysql.com/doc/refman/5.7/en/mysqlbinlog.html
Q:Cloud SQL 中的 stored procedures 如何紀錄執行失敗?
A:目前 Cloud SQL 並沒有特別對 MySQL stored procedure 收集或生成 log。另外,Google support 表示一般常見的做法是將 stored procedure 運行時的產生的訊息寫入另一個 table 以便後續檢查/除錯,做法可以參考[1][2][3]。
另外,在我們的經驗方面,我們自己產品的業務邏輯其實是非必要不使用 stored procedure 的,因為難以測試/除錯/監控。
[1] https://www.mssqltips.com/sqlservertip/2003/simple-process-to-track-and-log-sql-server-stored-procedure-use/
[2] https://www.otreva.com/blog/mysql-logging-calls-stored-procedures/
[3] https://stackoverflow.com/questions/273437/how-do-you-debug-mysql-stored-procedures
Q:Cloud SQL 在進行匯出時,可以匯出 stored procedures 嗎?
A:不行[1]。文件當中有說,匯出的資料不包括 triggers、stored procedures、or functions。
[1] https://cloud.google.com/sql/docs/mysql/import-export/exporting
Q:Cloud SQL 的複本抄寫方式,是同步完成後才算 commit 嗎?
A:抄寫的話有分 failover replica 跟 read replica,嚴格來說兩種都不是同步完成,細節需要參考 MySQL 的官方文件。
- failover replica[1] 使用的是 Semisynchronous Replication [2],由文件 [3][4] 可以得知 master 在 slave 收到 event log 之後即會 commit transaction,此時 slave 雖然已經收到 event log,但有可能 slave 的資料庫內容還沒有依照 event log 做改動。
- read replica 則是傳統的 Asynchronous replication [5],抄寫的行為和 transaction commit 之間基本上沒有關係。
[1] https://cloud.google.com/sql/docs/mysql/high-availability
[2] https://dev.mysql.com/doc/refman/5.7/en/replication-semisync.html
[3] The slave acknowledges receipt of a transaction’s events only after the events have been written to its relay log and flushed to disk.
[4] At this point, the transaction has committed on the master side, and receipt of its events has been acknowledged by at least one slave.
[5] https://dev.mysql.com/doc/refman/5.7/en/replication-implementation-details.html
Q:Cloud SQL 的 slow query log 該如何查詢?
A:Cloud SQL Instance 加入旗標 –log_output=’FILE’ and –slow_query_log=on 就能紀錄 slow queries [1],搭配 Stackdriver 可以看到 mysql-slow.log。
目前旗標 long_query_time 的設定只要超過 3 秒都會寫入 slow query log file,可以調整並控制記錄檔的資料量。
使用 Advanced Filters 搭配”query_time: 1~9″ 字串比對方式,找出大於 1 秒的所有 slow query 查詢,請參考測試語法如下 [2]
resource.type=””cloudsql_database””
resource.labels.database_id=””[PROJECT]:[CLOUD SQL INSTANCE]””
logName=””projects/[PROJECT]/logs/cloudsql.googleapis.com%2Fmysql-slow.log””
(“”query_time: 1″” OR “”query_time: 2″” OR “”query_time: 3″” OR “”query_time: 4″” OR “”query_time: 5″” OR “”query_time: 6″” OR “”query_time: 7″” OR “”query_time: 8″” OR “”query_time: 9″”)
其他參考資料:MySQL Slow Query Log 查詢範例 [3],如何分析 MySQL slow query log 的說明 [4]
[1] https://cloud.google.com/sql/docs/mysql/diagnose-issues
[2] https://cloud.google.com/logging/docs/view/advanced-filters
[3] https://dev.mysql.com/doc/refman/5.7/en/slow-query-log.html
[4] https://blog.toadworld.com/2017/08/09/logging-and-analyzing-slow-queries-in-mysql
Q:Cloud SQL 的 CPU 使用率過高的可能原因是什麼?
A:MySQL cpu 使用率過高的問題定位方法可以參考文件[1]。
MySQL CPU 使用率過高的常見原因之一是使用者執行了一個會消耗大量 CPU 資源的 SQL Statement,這種情況下可以透過以下指令 (或 SHOW FULL PROCESSLIST; ) 觀察到某個 SQL Statement 的執行時間過長,當出現這個現象時,會導致其他連線的查詢反應時間變慢,進而導致連線數目急遽增加。一但觀察到這個現象,救急的方法是先把造成問題的 SQL Statement 終止,比較長遠的做法是優化 SQL Statement。
SELECT id,state,command,time,left(replace(info,'\n',''),120) as sqlstr
FROM information_schema.processlist
WHERE command <> 'Sleep'
[1] https://aws.amazon.com/premiumsupport/knowledge-center/rds-instance-high-cpu/
Q:Cloud SQL 的 binlog 是否只留存 7 天, 多餘的會刪除?
A:是的。二進位檔記錄會隨著自動備份一起刪除,這通常會在約 7 天後發生。用戶無法手動刪除二進位檔記錄,或變更 7 天的等候時間 [1]。
[1] https://cloud.google.com/sql/docs/mysql/replication/tips#bin-log-impact
Q:想確認如果 binlog 曾經擴增到很大, 那麼是否即使刪除 binlog, 硬碟依然不會縮小?
A:是的。在 [1] 中可以找到相應描述。
[1] https://cloud.google.com/sql/docs/mysql/instance-info#available_metrics
Q:是否可以協助縮小硬碟空間? 是否需要停機?
A:可以聯繫 iKala,我們將向 Google support 請求縮小用戶的 Cloud SQL 硬碟空間,整個流程需要消耗一定的時間。另外也有一定的停機時間,從 Failver replica 開始縮小硬碟空間可以縮短停機時間,但不可避免。
Q:想確認如果要縮小硬碟空間, 是否需要提供什麼額外資訊?
A:最主要的資訊需要提供專案 ID、Cloud SQL 的 instance ID、目標硬碟大小、允許停機的時間。