本文的內容是由數個教程所組成的概述,此系列教程將向您展示如何在 Google Cloud Platform (GCP) 中使用 TensorFlow 和 Cloud ML Engine 實作推薦系統 (recommendation system)。
本文內容將涵蓋:
- 概述以矩陣分解為基礎的推薦系統理論。
- 描述如何使用加權交替最小平方法 (weighted alternating least squares – WALS) 來進行矩陣分解。
- 提供系列教程概述,並提供在 GCP 上實作推薦系統的逐步指南。
本教程中的推薦系統使用加權交替最小平方法 (WALS)。WALS 包含在 TensorFlow 程式碼基底的 contrib.factorization 套件當中,用來分解使用者與物品評等的大型矩陣。
本系列教程
本篇文章包含以下教程:
- [第1部分] 創建模型:展示如何使用 TensorFlow 中的 WALS 演算法對熱門的 MovieLens 資料集進行評分預測。
- [第2部分] 在 Cloud ML Engine 上訓練和調整:展示了如何使用 Cloud ML Engine 來訓練模型,並使用超參數調整功能將模型最佳化。
- [第3部分] 從 Google Analytics 資料應用分析:展示如何直接從 Google Analytics 360 匯入資料並套用到推薦系統,讓 Google Analytics 網站執行推薦功能。
- [第4部分] 部署推薦系統:展示如何在 GCP 上部署正式環境,以便為網站提供即時推薦功能。
推薦作業的背景理論
本文將應用於推薦系統,以矩陣分解為基礎的協同過濾的背景理論。以下主題將會深入探討,並提供相關連結做為延伸閱讀:
- 協同過濾:什麼是協同過濾?如何使用從中獲得的深入分析?
- 矩陣分解:什麼是評分矩陣,什麼是潛在因素,你如何用數學方法轉換為評分矩陣來進行估算?
- 將 WALS 方法用於矩陣分解:如何使用 WALS 方法進行矩陣分解?
推薦系統的協同過濾
協同過濾技術是產生使用者建議很有用的方法。協同過濾只要依據觀察到的使用者行為做出建議,不需要存取個人資料或內容。
這項技術以下列觀察為基礎:
- 以類似項目進行互動的使用者 (例如:購買相同的產品或查看相同的文章) 會使用一個或多個隱藏的共同偏好。
- 具有共同偏好的使用者較可能對同一個項目做出同樣的反應。
結合這些基本觀察就可以讓推薦引擎發揮正常的功能,無需精準地判斷出使用者的共同偏好,只要確認這些偏好存在具有意義。基本假設是,相似的使用者行為會反映出類似的基本偏好,依此方式讓推薦引擎提出建議。
例如,假設使用者 1 看了項目 A、B、C、D、E,使用者 2 看了項目 A、B、D、E、F,並沒有查看 C,因為兩個使用者都查看了 6 個項目當中同樣的 5 個項目,表示他們可能有一些基本的共同偏好。使用者 1 喜歡項目 C,如果使用者 2 注意到項目 C 的存在,可能也會喜歡這個項目。這就是推薦引擎的著力點:將項目 C 的資訊通知使用者 2,引起該使用者的興趣。
使用矩陣分解進行協同過濾
可以使用矩陣分解來解決協同過濾的問題。假設您的矩陣包含了使用者 ID 及他們與產品互動的資訊。每一列對應到唯一的使用者,且每一欄對應到一個項目。項目可以是目錄中的一個產品、一篇文章或一段影片。矩陣中的每個元素都會擷取使用者的評分或偏好做為單一項目。評分可以是顯性的,直接從使用者意見回饋來產生;也可以是隱性的,根據使用者的購買記錄或是與文章/影片所互動的時間來推敲。
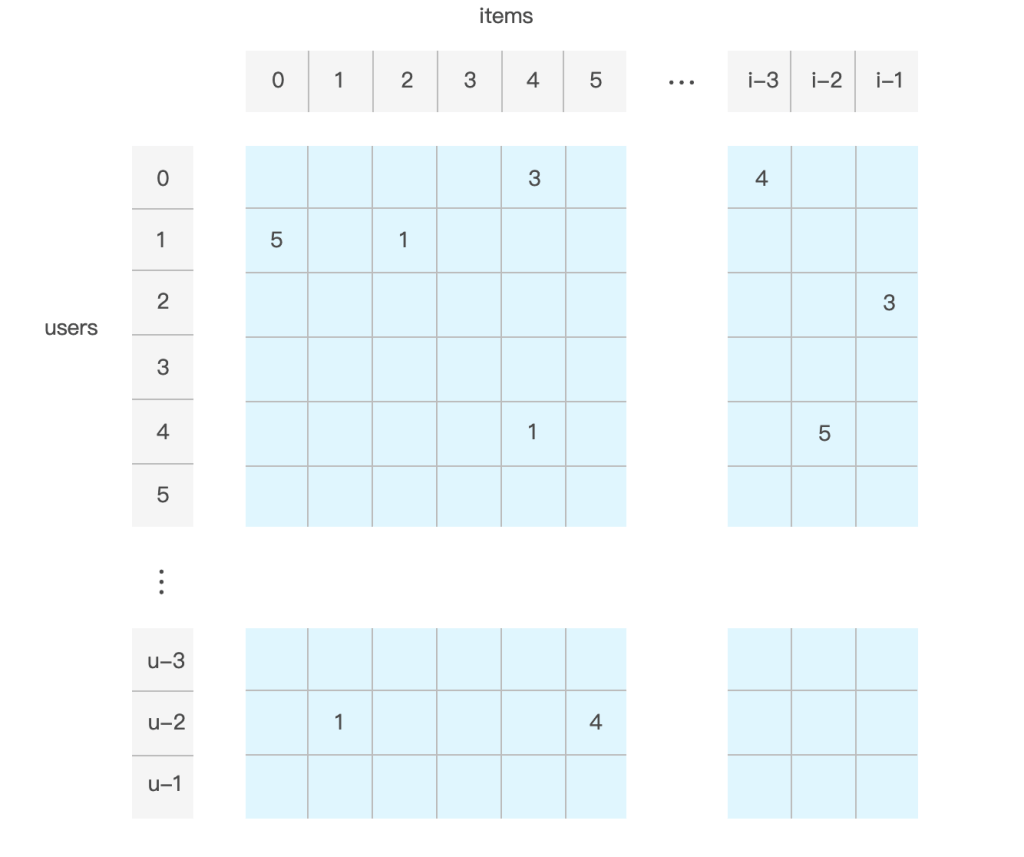
如果使用者從未對某項目進行評分,或是表示任何隱藏的興趣,則矩陣的元素為零。圖1為 MovieLens 評分矩陣的表示方式。
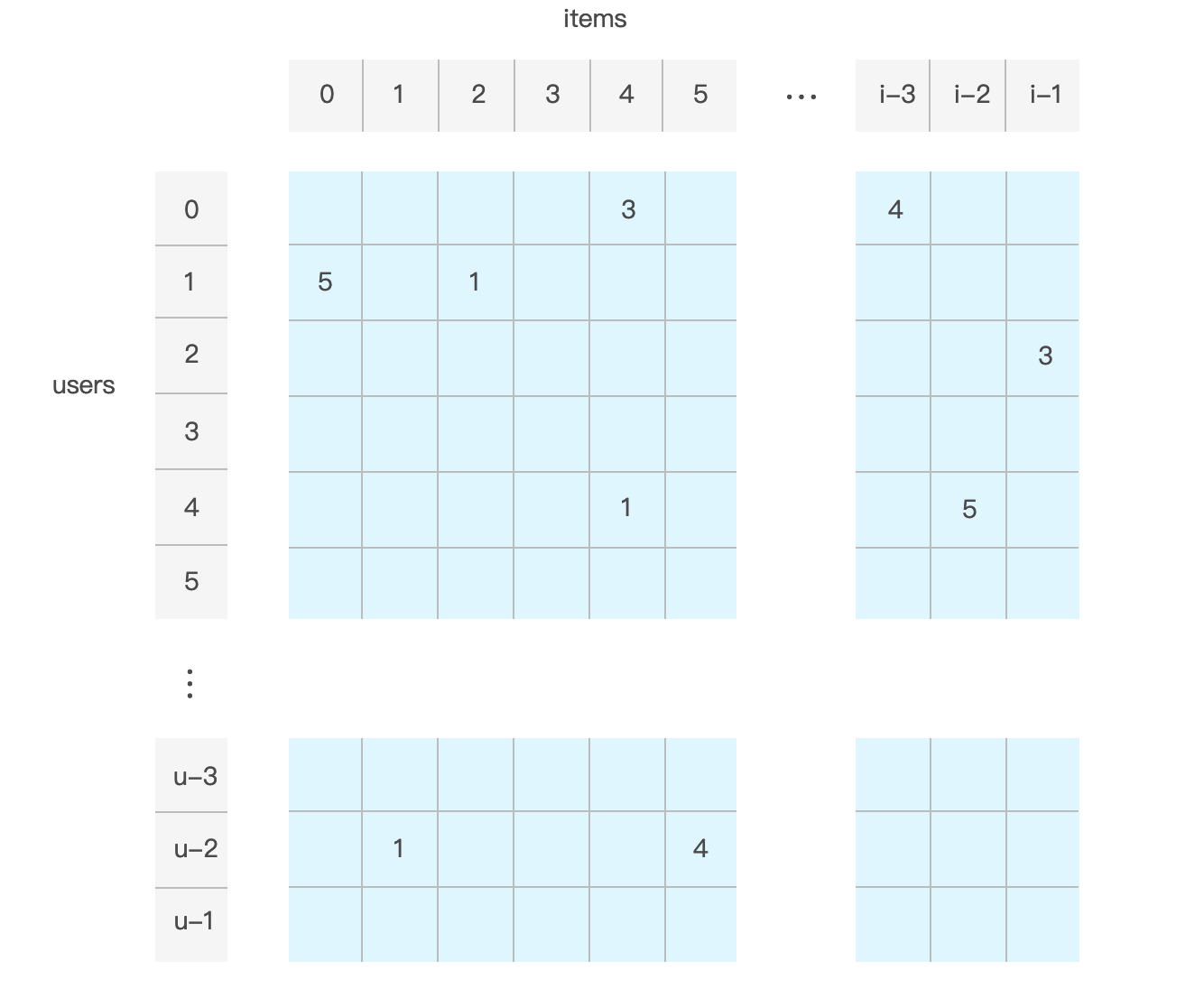
MovieLens資料集中的評分範圍為 1 到 5。空白評分元素的值為 0,表示指定的使用者沒有給項目評分。
定義矩陣分解方法
一個評分矩陣由一個矩陣 R 所組成,其中元素 rij 是使用者i 對項目 j 的評分。對於許多網際網路應用程式來說,這些矩陣都很龐大,包含數百萬名使用者和數百萬個不同的項目。這些元素也是稀疏的,代表每位使用者通常進行評分、檢視或僅購買整個集合其中一小部分的項目。絕大多數的矩陣元素 (通常大於99%) 都是零。
矩陣分解方法假設所有項目有一個共同屬性的組合,對於各屬性表達的程度上有所不同。此外,矩陣分解方法假設每一位使用者對每個屬性都有自己的表達程度,與這些項目無關。這樣一來,就能透過每個使用者屬性的強度進行加總,強度以該項目表達的程度而決定屬性的權重,用來取得使用者項目評分的近似值。這些屬性有時被稱為隱藏或潛在因素。
直覺上可以容易地看出這些假設潛在因數是真的存在。以電影為例,很明顯許多使用者都有偏好的類型、演員或導演。這些類別代表了一些潛在的因素,這些因素雖然顯而易見,但仍然非常有用。例如,類型偏好顯示使用者喜歡看的電影,具有相似類型偏好的觀眾可能會喜歡類似的電影。協同過濾的矩陣分解方法大部分功能源自於這樣的事實:不必知道某位使用者完整偏好可能的組成,包括流派數量、演員或其他的類別,只會簡單地假設其為任意數量。
轉換矩陣來展現潛在因素
若要將現有的潛在因數轉換為評分矩陣,你可以這樣做:對於一組大小為 u 的使用者 U 和大小為 i 的項目 I,你選擇任意數量 k 的潛在因數,並將大矩陣 R 分解為兩個較小的矩陣 X (列因數) 與 Y (欄因數)。矩陣 X 的維度是 u × k,而 Y 的維度是 k × i。如圖 2 所示。
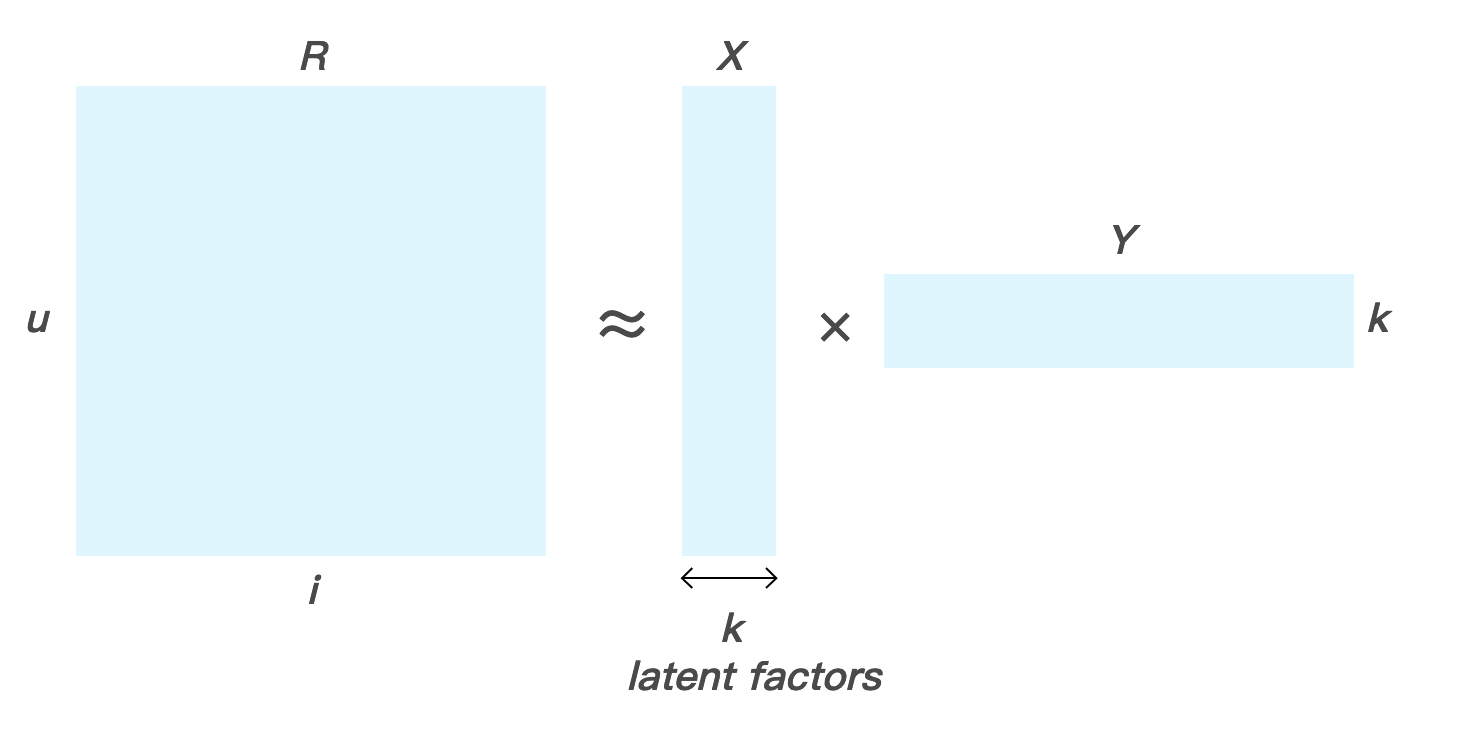
圖 2. 使用列因數和欄因數來預估評分矩陣
在線性代數中,這被稱為低秩近似。您可以將此過程視為將R中的稀疏資訊壓縮到更低的維度空間 u×k 和 k×i。當低秩矩陣X和Y相乘可獲得矩陣 R’,代表 R 的近似值。
在這個 k 維度空間中,每位使用者皆以向量表示,而 X 中的每一列 xu 都對應到使用者對這些 k 因數的偏好強度。同樣地,k 維度空間中的每個項目都以向量表示,在 Y 中有一個欄位 yi 對應到相同 k 因數的項目運算式。
如要計算使用者 u 對於項目 i 的評分,請利用兩個向量的內積:
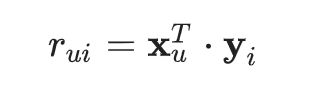
內積是一個代表近似值的實數 ;用機器學習 ML的術語,代表使用者 u 對於項目 i 的評分預測。如下方圖 3 所示。
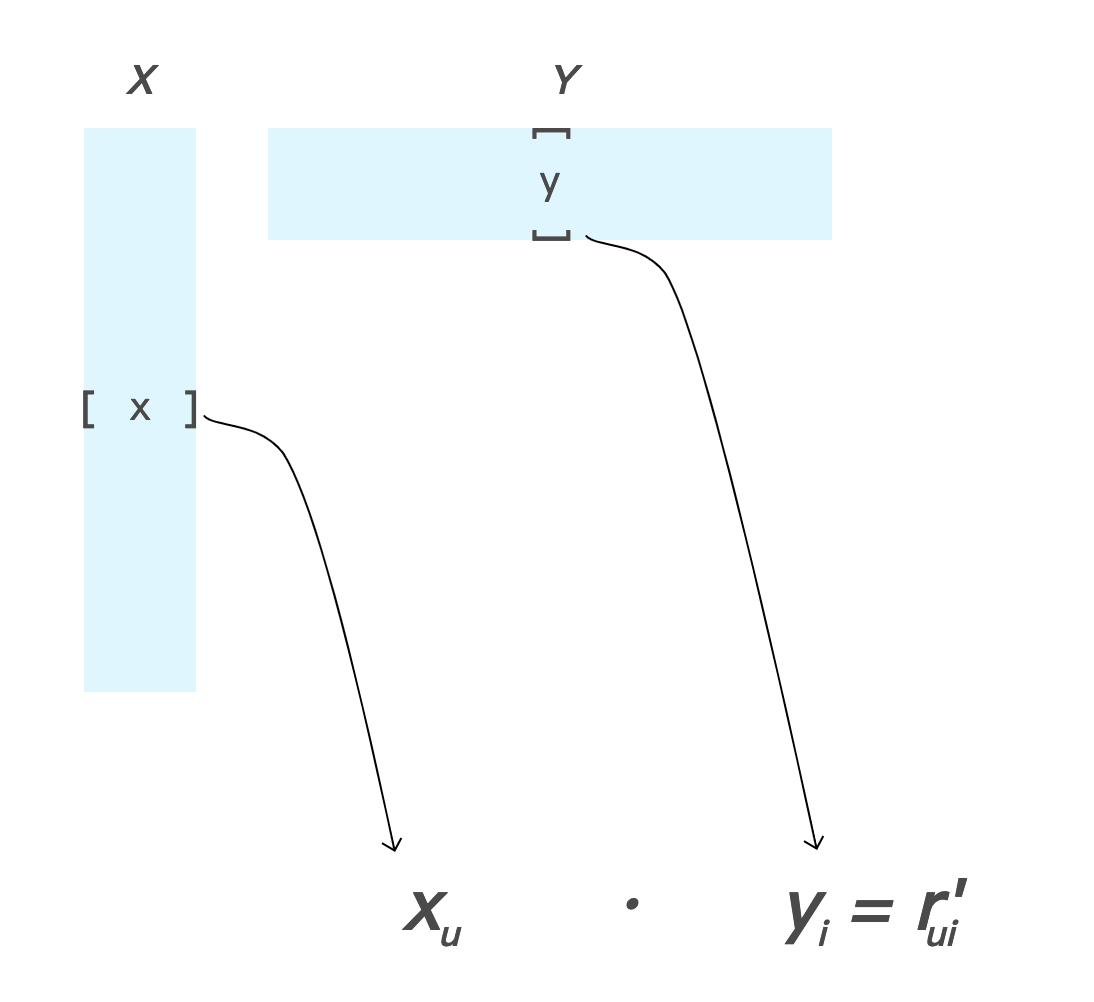
圖 3. 根據列因數和欄因數計算預測評分
您可以定義損失函式,以下列方式測量近似值的準確性:
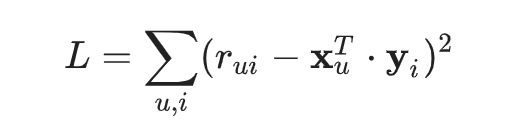
此公式進行以下計算:針對所有使用者和項目,計算近似值評分 xuT⋅yi 與訓練集 rui 的實際評分之間的平方差總和。
常見的做法是將正規化條件加入損失函式,以避免過度配置 overfitting。為列因數和欄因數加入 L2 正規化條件,得到以下的結果:
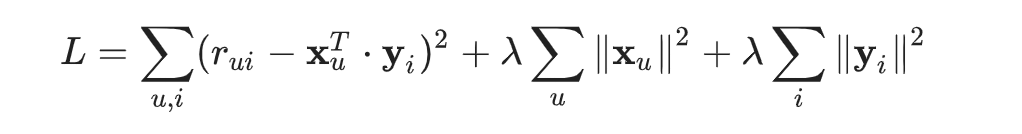
在這裡,λ 是一個正規化常數,這是模型的超參數之一,我們會在教程系列的第 2 部分進行探討。
矩陣分解的 WALS 方法
本節討論矩陣分解的兩種方法。
交替最小二乘法(ALS)
矩陣分解的交替最小平方法是一種疊代方法,可用於判斷最接近 R 的最佳 X 和 Y 因數。在每次疊代中,其中一個列因數或欄因數保持固定,其餘則透過最小化損失函式來對其他的因數求解。
首先,從列因數開始操作:
- 將欄因數設為常數。
- 根據列因數計算出損失函式的導數。
- 將方程式設為等於零。
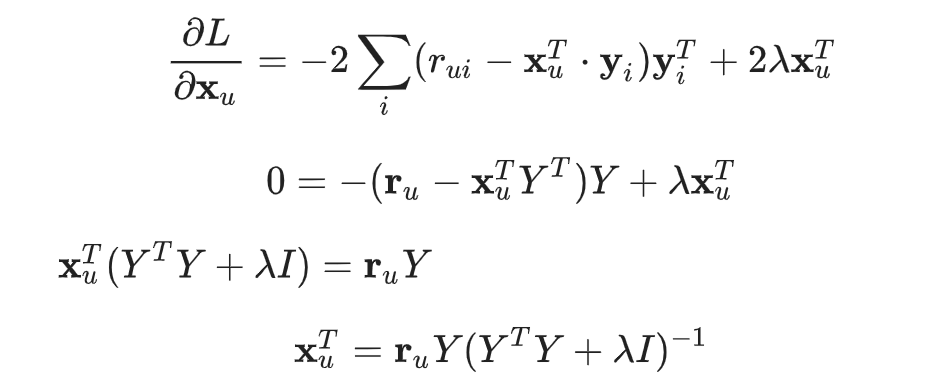
將求解的列因數維持不變,解出欄因數的類比方程式,繼續進行疊代程序。交替計算列因數和欄因數,重複疊代程序直到收斂為止。這通常發生在疊代次數較少 (< 20) 的情況,即使是包含數千萬資料列或資料欄的超大矩陣也是如此。
加權交替最小平方 (WALS) 法
演算法的加權版本,針對零或未觀察的元素,以及矩陣內不是零的元素,提供不同的加權方式:

在這個公式中:
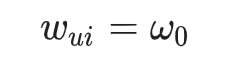 針對評分矩陣中的零 (未觀察) 元素,以及
針對評分矩陣中的零 (未觀察) 元素,以及
![]() 針對已觀察的元素,其中
針對已觀察的元素,其中
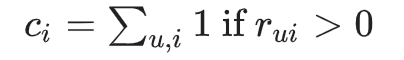 欄位 i 的非零元素數量的總和
欄位 i 的非零元素數量的總和
加權按照資料列內的非零元素的總和進行調整,藉由正規化評定不同項目數量的使用者的加權。此加權類型提供了更彈性的使用者偏好模型,並產生比未加權版本更好的實驗結果 (詳情請參閱論文 Collaborative Filtering for Implicit Feedback Datasets)。函式f 會根據資料集,以及評分是顯性或隱性的不同而有所變化。
MovieLens 資料集包含顯性評分。在本案例中f 有更好的做法,就是針對觀察到的元素做線性加權:
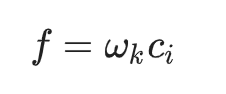 其中 wk 是觀察到的加權
其中 wk 是觀察到的加權
與動態事件相關的隱性評分,由於每個評分都對應到觀看影片、閱讀文章或瀏覽網頁的次數,評分本身可能會因為使用者行為而呈現指數分佈。如果使用者點入頁面或影片後很快就離開,將會造成許多低價值的評分。如果使用者閱讀整篇文章、觀看整部影片,或觀看排定節目很多次時,就會減少大量的隱性評分。在這種情況下,針對觀察到的評分來進行加權,考量f 適當的做法如下:
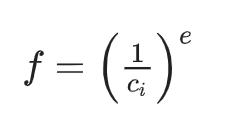 其中 e 是特徵加權指數。
其中 e 是特徵加權指數。
WALS 與其他技術相比
有多款矩陣分解技術可用於協同過濾,包括奇異值分解 SVD 和隨機梯度下降 SGD。在某些情況下,這些技術給出了比WALS更好的約降秩近似。比較不同協同過濾方法的優缺點已經超出了本文的範圍,但是建議您看看下列 WALS 優點:
- WALS 採用的加權適合用於隱性評分,但是 WALS 也能應用在顯性評分資料集,例如 MovieLens。
- WALS 內含演算法最佳化,可以輕鬆整合加權,並有效計算列因數和欄因數的更新。詳情請參閱論文 Collaborative Filtering for Implicit Feedback Datasets。這些最佳化內建於 WALS TensorFlow 程式碼基底中。
- 建立演算法的發行版本相對直觀。發行版本能夠處理非常大型的矩陣,可能內含數億個資料列。WALS 發行版本並不在本文的討論範圍內。
其他相關的資源
開始進行本系列的教程:
- 如何在 TensorFlow 部署推薦系統:建立系統 (一)
- 如何在 TensorFlow 部署推薦系統:訓練和調整 Cloud Machine Learning Engine (二)
- 如何在 TensorFlow 部署推薦系統:在 Google Analytics (分析) 的資料上應用 (三)
- 如何在 TensorFlow 內建立推薦系統:部署推薦系統 (四)
(原文取材於 Google Cloud。)