透過這篇文章,您可以透過運行在 App Engine 上的 Web 應用程式來使用 Prediction API,以進行線上預測。這將是機器學習與結構化數據系列文章的最後一篇,將接續系列二的訓練模型。
架構
這篇文章將用到下圖中虛線內的元件:
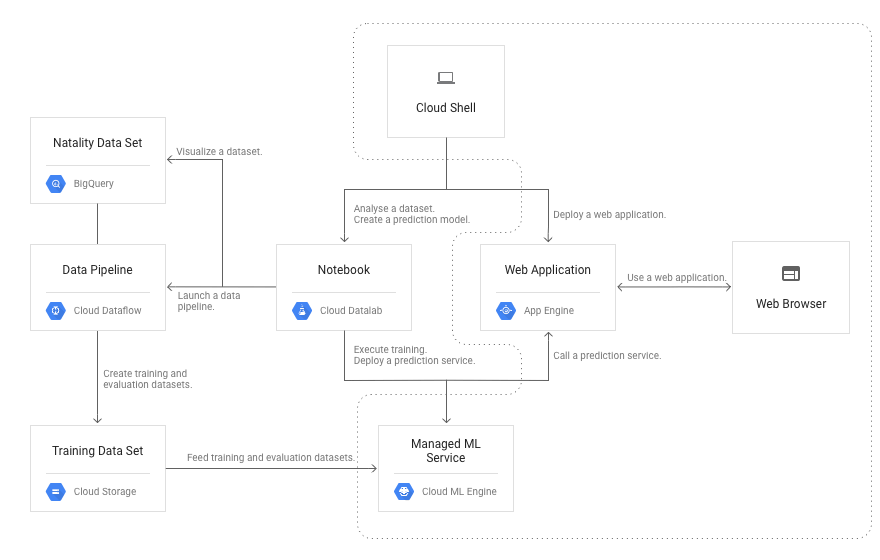 第二篇系列文的 Prediction API 作為其後端基礎。Managed ML Service 將負責託管 Prediction API,並將嬰兒體重預測值回傳到指定的 Web 應用程式的輸入數據。
第二篇系列文的 Prediction API 作為其後端基礎。Managed ML Service 將負責託管 Prediction API,並將嬰兒體重預測值回傳到指定的 Web 應用程式的輸入數據。
在開始之前
請先完成第二篇系列文的內容,再開始這一部分。
費用
這篇教學文章將使用以下計價元件:
- App Engine
- Cloud ML Engine
根據定價公式,假設你用上述每個元件一整天,那運行這教程將花費約 0.16 美元。
驗證 Prediction API 服務
- 開一個新的 Cloud Shell 視窗 [OPEN CLOUD SHELL]
- 以下指令會回傳已經部署完畢的模型名稱
gcloud ml-engine models list
確認 babyweight 模型名稱以及回傳的 DEFAULT_VERSION_NAME 等於 soln。NAME DEFAULT_VERSION_NAME babyweight soln
下載 babyweight 應用程式
- 在 Cloud Shell 裡面,下載 babyweight 應用程式的文件,並且設定你現在所處的資料夾。
git clone https://github.com/GoogleCloudPlatform/training-data-analyst cd training-data-analyst/blogs/babyweight/application資料夾中包含以 Python 跟 JavaScript 所編寫的程式碼。以下的文件完成了大部分的工作:
- main.py 這是一個運行在 App Engine 的 Python 程式。它提供一個可以回傳嬰兒體重預測值的 API 服務。從架構圖中可以看到,要取得這個預測值,它使用了部署在 Managed ML Service 上面的 Prediction API 服務。
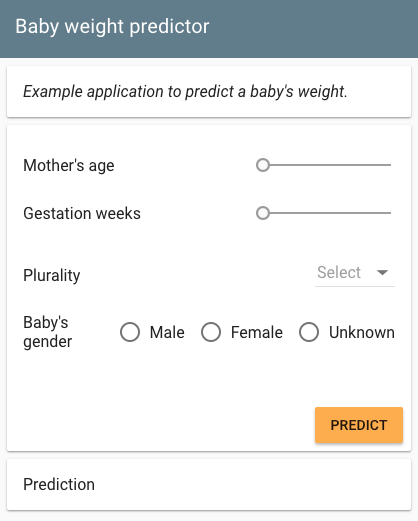
- templates/form.html 是一個包含 JavaScript 程式碼的 HTML 文件,呈現如下所示的輸入表單。它將 REST API 請求發送到在 App Engine 上運行的後端應用程式,然後顯示結果。
以下是 babyweight應用程式的輸入表單:
api = discovery.build('ml', 'v1', credentials=credentials)
…
prediction = api.projects().predict(body=input_data, name=parent).execute()
def get_prediction(features):34: project = app_identity.get_application_id()
43: parent = 'projects/%s/models/%s' % (project, model_name)
部署 babyweight 應用程式
- 在 Cloud Shell 中,下載應用程式所需要的程式碼庫
pip install -r requirements.txt -t lib - 部署程式碼
gcloud app create --region=us-central gcloud app deploy
當您在 Cloud Shell 中執行這些命令時,您的 project id 會自動對應到應用程式,應用程式 URL 會被定義為 https://[PROJECT_ID].appspot.com。現在你可以在瀏覽器中輸入 URL 來存取嬰兒體重預測的應用程式。
注意:這個應用程式是公開的,所以你不應該直接使用它,因為它可以在你不知情或未經你許可的情況下被使用。 您應該考慮添加身份驗證。 請參閱 User Authentication。
清理
完成本教程後,記得清除您在 GCP 上創建的資源,將來才不會因此被收費。以下部份將介紹如何刪除這些資源。
刪除 Project
避免被收費的最簡單方式是刪除你為此教程所創建的 Project。
如何刪除 Project:
警告:刪除項目可能會產生以下後果
*如果您刪除的是既有的 Project,那您也會將您在這個 Project 中曾經完成的工作一併刪除。
*您不能重複使用已刪除 Project 的 Project ID。 如果您新建了一個未來可能會用到的客製化 Project ID,則你應該刪除的是 Project 裡面的資源,而非 Project。這可以確保使用 Project ID 的網址(例如appspot.com網址)仍可使用。
*如果您會持續尋找更多的教程和 quickstart,建議您重複使用 Project 以避免超出 Project 的配額限制。
- 進入 Cloud Platform Console,去 Projects 的頁面。
(GO TO THE PROJECTS PAGE) - 在 Project 列表中,選擇要刪除的 project 並點擊 Delete project。