這篇文章中,您將使用 TensorFlow 的 high-level Estimator API 創建一個寬且深的機器學習預測模型。您可以透過上一篇文章:數據分析和準備中所創建的 CSV 文件在 Cloud ML Engine 上訓練模型。
架構
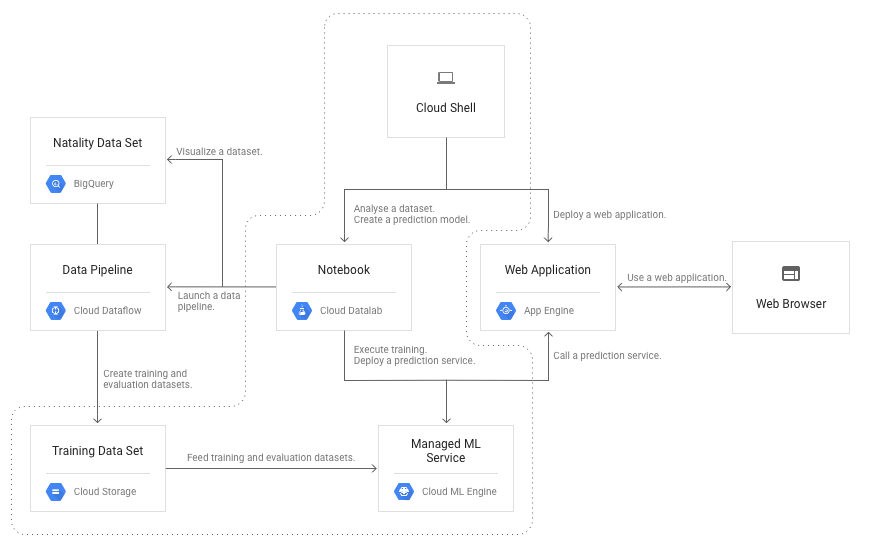
這篇文章將使用下圖中虛線內的元件:
- Compute Engine
- Persistent Disk
- Cloud Storage
- Cloud ML Engine
根據這個定價計算器,假設您花一天使用這些元件來實作這篇文章,預計會花 1.57 美元。
開始之前
在開始之前,您必須完成本系列的第一部分 “資料分析和準備“。
透過 notebook
您可以按照前一篇文章中所下載的 Cloud Datalab notebook 說明,來了解建立機器學習模型的 end-to-end 流程。這篇文章是 notebook 的第二部分,將提供一些概要和補充的內容。
使用 Estimator API 創建 TensorFlow 模型
在第一篇文章中,您探索了原始數據集並選擇了與嬰兒體重相關的特徵。您還使用 Cloud Dataflow 將數據集轉換為 CSV 文件,將它們分成 training set 和 evaluation set。
選擇一個合適的模型
TensorFlow 在建構模型時提供了幾個抽象級別 (levels of abstraction)。較底層的 API提供了強大功能以及很高的靈活性,如果您是開發新機器學習技術的研究人員,較底層的 API 對你而言將非常實用。然而,估算嬰兒體重是一個直接、具明確定義的問題,high-level 的 Estimator API 則會是實作機器學習解決方案的最佳選擇。
Estimator API:
- 附帶內建估算器 (estimator) 或類別 (class),您可以透過實例化來解決常見的機器學習問題。
- 與其將您限制在一台機器上,它允許您在一組機器上訓練模型。 Estimator API 提供了一個很方便的方式去實作分佈式訓練。
對於 Natality 數據集,notebook 使用 tf.estimator.DNNLinearCombinedRegressor 回歸器。此回歸器允許您使用具有嵌入圖層和多個隱藏圖層的前饋神經網絡創建一個一般化的模型,該模型具有深度及稀疏特徵的邏輯回歸。
下面的圖片概述了三種主要的模型類型:寬、深、寬且深:

寬模型通常對基於分類特徵的訓練很有用。在 Natality 數據集中,以下特徵適用於寬模型:
- is_male, plurality
若要將數值特徵應用於寬模型,則必須將連續值拆分為 buckets of value ranges (就是對其進行分段),將其轉換為分類特徵。在這種情況下,您可以將此技術應用於以下特徵:
- mother_age, gestation_weeks
特徵組合透過連接 (concatenate) 一對特徵 (is_male, plurality) 來產生新特徵,並將該連接作為 input,以便讓模型學習。例如:雙胞胎男孩往往比雙胞胎女孩具有更高的體重。您可以將特徵組合直接應用在分類特徵,並且可以在將數值特徵首先離散為數據特徵時,將其應用於數值特徵。
深層模型最適合數字特徵。嬰兒體重預測問題中特徵符合以下標準:
- mother_age, gestation_weeks
您也可以在深層模型中使用嵌入層。嵌入層將大量分類特徵轉換成較低維的數字特徵。缺點是特徵組合會大大增加特徵的總數,如果提供給深度網絡,則會增加過度擬合的風險。您可以通過使用嵌入層來緩解這種風險。
在 Natality 數據集中,您可以獲取數值資料,將它們切割成幾個區塊,透過特徵組合產生其他分類特徵,然後使用嵌入圖層。該嵌入層是深層模型的附加輸入。
總而言之,某些數據特徵適用於寬模型,其他特徵可以通過深模型更好地工作:
| 寬模型 | 分類特徵和分段數值特徵 | is_male, plurality, mother_age (bucketized),gestation_weeks (bucketized) |
| 深模型 | 數值特徵 | mother_age, gestation_weeks |
| 深模型加上嵌入層 | 透過特徵組合產生分類特徵 | 在寬模型中組合特徵 |
為了解決不同類型特徵帶來的問題,開發了廣且深的模型。它是以前兩種模型的組合。您可以指定在配置 Estimator 對象時由哪個模型使用哪些特徵。
以下是一個廣且深的架構:

讀取資料的函數
Estimator API 要求您提供一個名為 input_fn 的函數,該函數會在每次調用時從訓練集中返回一批範例。您可以使用筆記本中的 read_dataset 函數透過指定 CSV 文件的檔案名稱模式來創建 input_fnfunction。
在內部,input_fn 函數使用存儲在變量 filename_queue 中的文件名隊列對像作為排隊機制。它會在索引範例之前,識別與檔名及模式相匹配的檔案並對其進行洗牌。從 CSV 文件讀取一行後, tf.decode_csv 將列值轉換為 TensorFlow 常量對象列表。 DEFAULTS 列表用於標識值類型。
例如,如果 DEFAULTS 的第一個元素是 [0.0],則第一列中的值將視為實數。 input_fn 函數還提供默認值以補充 CSV 文件中的空單元格;這些空單元被稱為缺失值。最後,使用 CSV_COLUMNS 值作為鍵將列表轉換為 Python 字典。input_fn 函數返回特徵字典和相應的標籤值。在這種情況下,標籤是嬰兒的體重。
值的轉換
從 CSV 文件讀取值後,您可以對其應用其他轉換。例如, is_malefield 包含字符串 True 和 False。然而,將這些字符串用作直接模型輸入是沒有意義的,因為數學模型並不像人類那樣解釋字面表達式的含義。通常的做法是對分類特徵使用單熱編碼。在這種情況下,True 和 False 分別映射到兩個二進制列 [1, 0] 和 [0, 1]。
如前一部分所述,您還必須將數值分段 (bucketization),特徵組合和嵌入技術應用於原始輸入。
TensorFlow 提供了一個名為”特徵列”的輔助方法來自動執行這些轉換,這些方法可以 Estimator 物件一起使用。例如,在以下代碼中,tf.feature_column.categorical_column_with_vocabulary_list 將 one-hot 編碼應用於 is_male。您可以使用返回值作為 Estimator 物件的輸入。
tf.feature_column.categorical_column_with_vocabulary_list('is_male',
['True', 'False', 'Unknown'])
在以下代碼中,您可以應用 tf.feature_column.bucketized_column 來對數值列 (例如 mother_age) 進行分段 (bucketize)。
age_buckets = tf.feature_column.bucketized_column(mother_age,
boundaries=np.arange(15,45,1).tolist())
boundaries 選項指定分段的大小。在前面的例子中,除了 “小於15” 和 “超過45” 之外,它還為 15 至 44 歲之間的每個年齡層建立分段。
以下代碼將特徵組合和嵌入圖層也應用於每一個寬列。
crossed = tf.feature_column.crossed_column(wide, hash_bucket_size=20000)
embed = tf.feature_column.embedding_column(crossed, 3)tf.feature_column.embedding_column 的第二個參數定義了嵌入層的維數,在這種情況下為 case 3。
定義寬且深的特徵
您必須區分用於寬部份和深部份的特徵。應用轉換後,您可以定義名為 wide 的特徵列表作為寬部分的輸入,以及名為 deep 的特徵列表作為深部份的輸入。以下代碼中的變量 (is_male, plurality 等) 是特徵列的返回值 (return values)。
wide = [is_male,
plurality,
age_buckets,
gestation_buckets]
deep = [mother_age,
gestation_weeks,
embed]
延伸閱讀:
(原文翻譯自 Google Cloud。)