繼機器學習與結構化數據系列第一篇介紹了如何準備數據及分析之後,此篇文章將接續上一篇,介紹如何訓練模型。
您必須為 Estimator API 定義 serving_input_fn 函數。此方法定義列以用作預測服務的 API 請求的輸入。輸入列通常與 CSV 文件中的輸入列相同,但在某些情況下,您希望接受與您在模型訓練過程中使用的格式不同的輸入數據。
通過使用此方法,您可以將輸入數據轉換為與訓練期間使用的表單相同的表單。預測的預處理步驟必須與您在訓練中使用的預處理步驟相同,否則您的模型將無法做出準確的預測。
創建和訓練模型
下一步是創建一個模型並使用數據集對其進行訓練。
定義模型
使用 Estimator API 定義模型是一個簡單的過程。以下單行代碼分別使用 wide 和 deep 的輸入來構建廣且深模型。它返回一個包含已定義模型的 Estimator 物件。
estimator = tf.estimator.DNNLinearCombinedRegressor(
model_dir=output_dir,
linear_feature_columns=wide,
dnn_feature_columns=deep,
dnn_hidden_units=[64, 32])
您可以使用 model_dir 選項指定各種訓練輸出的存儲位置。 dnn_hidden_units 選項定義了模型深部的前饋神經網絡結構。在這種情況下,使用兩個隱藏層,由 64 和 32 個節點組成。
每層中的層數和節點數是可調參數,為了將模型複雜度調整到數據複雜度,需要進行一些實驗。如果模型太複雜,通常會出現過度擬合,即模型學習了特定於訓練集的特徵,但未能對新數據做出好的預測。對於少量的輸入特徵(在這種情況下為 3),具有 64 和 32 個節點的兩層是一個很好的經驗起點。
在 Cloud Datalab 上運行訓練作業
您通過調用 tf.estimator.train_and_evaluate 函數並指定 Estimator 物件來執行訓練作業。如果此作業在分佈式訓練環境(例如Cloud ML Engine)上運行,則此特徵會將訓練任務分配給多個工作節點,並定期將檢查點保存在 Estimator 物件的 model_diroption 指定的存儲位置。該函數還會按照定義的時間間隔調用評估循環來計算度量以評估模型的性能。最後, tf.estimator.train_and_evaluate 函數以 SavedModel 格式導出訓練過的模型。
tf.estimator.train_and_evaluate 函數可以從最新的檢查點恢復訓練。例如,如果您執行指定 train_steps=10000 的訓練,則在使用 10,000 批次訓練後,模型的參數值將存儲在檢查點文件中。當您再次使用 train_steps=20000 執行訓練時,它會從檢查點恢復模型並從步數 10,001 開始訓練。
如果您想從頭開始重新開始訓練,則必須在開始訓練之前移除檢查點文件。在筆記本中,這是通過提前刪除 babyweight_trained 目錄來完成的。
因為在筆記本的這部分中,訓練是在託管 Cloud Datalab 的虛擬機實例上執行的,而不是在分佈式訓練環境中執行,所以應該使用少量數據。筆記本通過將文件模式指定為 pattern = “00001-of-“並將 train_steps 值設置為 1,000 來使用單個 CSV 文件進行訓練和評估。
利用 Cloud ML Engine 進行訓練
如果您確信自己的模型沒有任何明顯問題,並且已經準備好接受完整數據集的訓練,則可以製作一個 Python包,其中包含您在筆記本上開發的代碼並在 Cloud ML Engine 上執行它。
您使用從 GitHub clone 的預包裝代碼並將其傳輸到您的 Cloud Datalab 環境中以實現此目的。您可以瀏覽 GitHub 上的目錄結構。
本地運行
在向 Cloud ML Engine 提交訓練作業之前,在您的 Cloud Datalab 實例上本地測試程式碼是一種很好的做法。您可以使用筆記本上 Cloud on ML 訓練教程部分的第二個單元來完成此操作。由於預包裝代碼是一個 Python 包,因此您可以像運行筆記本時使用標準 Python代碼一樣運行它。但是,必須通過指定選項 –pattern=”00001-of-“and –train_steps=1000. 來限制用於訓練的數據量。
在 Cloud ML Engine 上運行
要使用 Cloud ML Engine 訓練模型,您必須使用 gcloud 工具提交訓練作業。
檢查點文件和導出的模型存儲在由 –output_diroption 指定的雲存儲存儲區中。如果要從頭開始重新開始訓練,則必須刪除舊的檢查點文件。為此,請取消單元格中的 “#gsutil -m rm -rf $OUTDIR” 行的註釋。
在您提交訓練作業 Cloud ML Engine 後,打開 Google Cloud Platform 控制台中的 ML 引擎頁面以查找正在運行的作業。
在這裡,您可以從訓練工作中找到日誌。要查看各種指標的圖形,可以通過在筆記本中同一部分的第四個單元格中執行命令來啟動 TensorBoard。下圖顯示了與訓練期間評估集合生成的 RMSE 值相對應的 average_loss 值。您可以在 TensorBoard 上將滑動條設置為平滑,以查看實際更改。
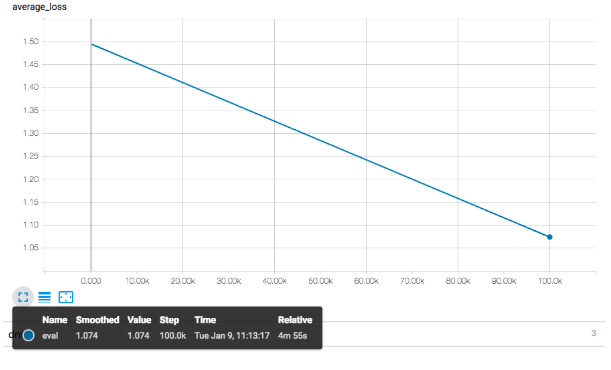
注意:圖中沒有顯示平滑的指數曲線,因為在這個例子中訓練非常短暫,所以RMSE值只在兩點進行評估。
當您完成使用 TensorBoard 時,請按照筆記本中的說明停止它。
部署訓練好的模型
訓練作業成功完成後,將訓練的模型導出到雲存儲存儲桶。
包含模型輸出的目錄路徑看起來像 $OUTDIR/export/exporter/1492051542987/,其中 $OUTDIR 是上一步中由 –output_dir 選項指定的存儲路徑。最後一部分是時間戳,每個作業都不相同。您可以從位於工作結束附近的訓練日誌中找到實際路徑,如下例所示:
SavedModel written to: gs://cloud-training-demos-ml/babyweight/trained_model/export/exporter/1492051542987/saved_model.pb
或者,您可以使用 gsutil 命令在筆記本中檢查 $OUTDIR 下的目錄內容。通過將此目錄路徑指定為 gcloud 命令的選項,您可以在 Cloud ML Engine 上部署該模型以提供預測 API 服務。
按照筆記本中的說明,您可以為預測服務定義廣且深的模型,並部署與模型版本關聯的模型。版本名稱是任意的,您可以同時部署多個版本。您可以在 API 請求中指定版本進行預測,您將在下一節中進行這些預測。您也可以定義在請求中未指定版本時要使用的預設版本。
將模型部署到預測服務後,可以使用 GCP 控制台中的 ML 引擎頁面來查看已定義模型和關聯版本的列表:
使用模型生成預測
在筆記本中,您可以使用適用於 Google API Client Libraries for Python 將請求發送到您在前一部分中部署的預測 API 服務。
該請求包含與由訓練碼中的 serving_input_fn 函數定義的字典元素對應的 JSON 數據。如果 JSON 數據包含多個記錄,則 API 服務將返回每個記錄的預測。您可以按照筆記本中的示例了解有關如何使用客戶端庫的更多信息。
在項目之外使用客戶端函式庫時(例如在外部 Web 伺服器上),必須使用 API