在串流分析日益普及的世代,優化資料處理以降低成本,並確保數據品質及完整性是相當重要的。方法之一就是,只專注於處理更動的數據,而非所有可用的數據,而這就是異動資料擷取 (CDC) 派上用場的地方。CDC 就是實現此種優化方法的技術。
Dataflow 的開發人員(Google Cloud 的串流數據處理服務)開發了一個解決方案,可讓用戶從 5.6 版本或更高版本的任何 MySQL 資料庫(自行管理、內部部署等)中接收更動的串流,並同步到 BigQuery 的資料集。Google 在 Dataflow 模板的公開數據庫上提供了解決方案。您可以在 GitHub 數據庫的 README 部分找到有關使用模版的指南。
CDC 會呈現串流中已變動的數據,使運算與處理著重在特定已變動的紀錄。CDC 可以應用在任何使用案例上。舉凡重要資料庫的複製、即時分析任務的優化、快取失效、交易性數據儲存,或資料倉儲類型儲存間的同步等,都屬於 CDC 的應用範圍。
Dataflow 的 CDC 解決方案如何將資料從 MySQL 搬移到 BigQuery
如下圖所示,部署的解決方案能夠與任何 MySQL 資料庫搭配使用,而該解決方案是建構於 Debezium 開發的連接器來監控。該連接器使用 Data Catalog(Google Cloud 的可擴展管理服務)儲存 table metadata,並將更新送到 Pub/Sub(Google Cloud 原生串流接收及訊息傳遞技術)。然後,Dataflow 管道 (pipeline) 會從 Pub/Sub 中獲得這些更新,並同步 MySQL 資料庫與 BigQuery 資料集。
此解決方案仰賴 Debezium,Debezium 是 CDC 的傑出開源工具。Google 基於此技術開發了一個可配置的連接器,讓用戶可在本地端或所擁有的 Kubernetes 環境中運行,以來推送變更的數據至 Pub/Sub。
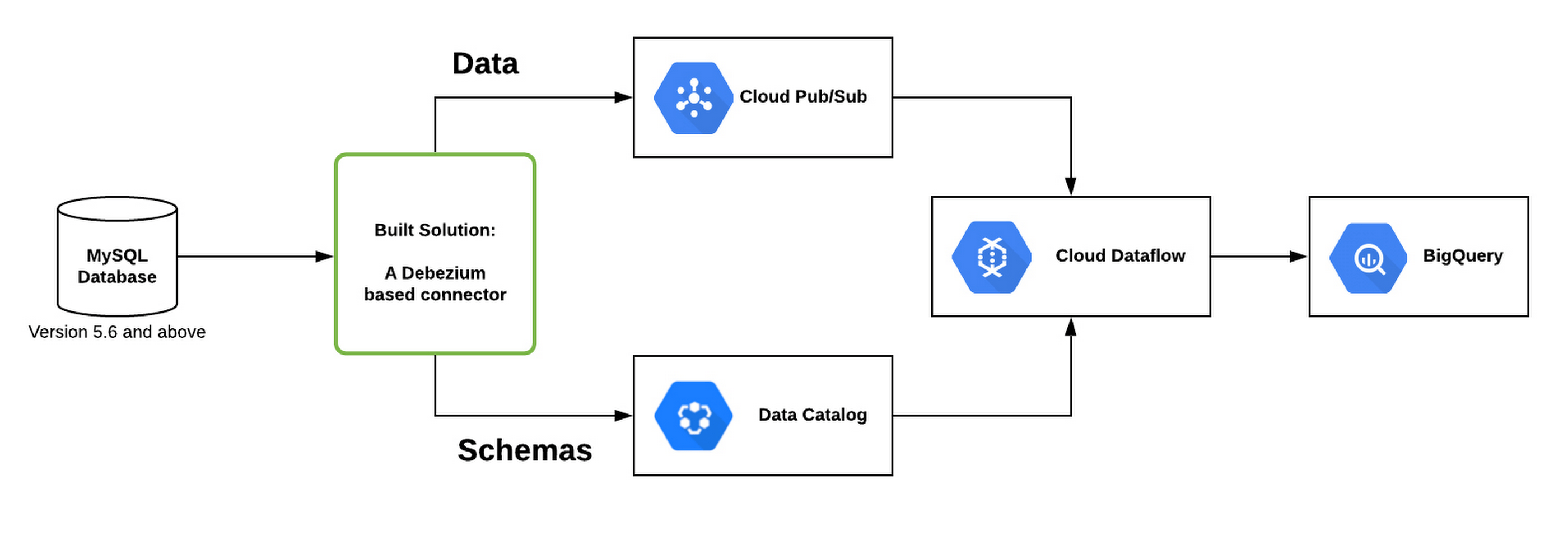
使用 Dataflow 的 CDC 解決方案
您可以透過以下四個步驟,部署 CDC 解決方案:
- 部署資料庫(若已有資料庫則跳過此步驟)
- 替每個欲匯出的資料表建立 Pub/Sub 主題
- 部署基於 Debezium 的連接器
- 啟動 Dataflow pipeline,以使用來自 Pub/Sub 的數據並同步到 BigQuery
假設您已有一個運行在任何環境上的 MySQL 資料庫。對於此資料庫中每個您欲匯出的資料表,都必須建立一個 Pub/Sub 主題,以及與該主題相對應的訂閱 (subscription)。
當設定完 Pub/Sub 主題及資料庫後,就可以運行 Debezium 連接器。該連接器可以在任何環境中運行:從本地來源端建構、透過 Docker 容器,或在 Kubernetes 叢集上。若需要參考 Debezium 連接器和此解決方案的詳細解說,讀者可參考這份 README 檔案。
一旦 Debezium 連接器開始運行並從 MySQL 獲得更動,它會推送這些更動至 Pub/Sub。使用 Data Catalog,它也會更新與每個 MySQL 資料表相應的 Pub/Sub 主題的 schema。
完成以上步驟後,您就可以啟用 Dataflow pipeline 來使用來自 Pub/Sub 的更動數據及同步到 BigQuery 資料表。Dataflow 任務能夠以命令提示字元模式來啟用。啟動後的畫面如下:
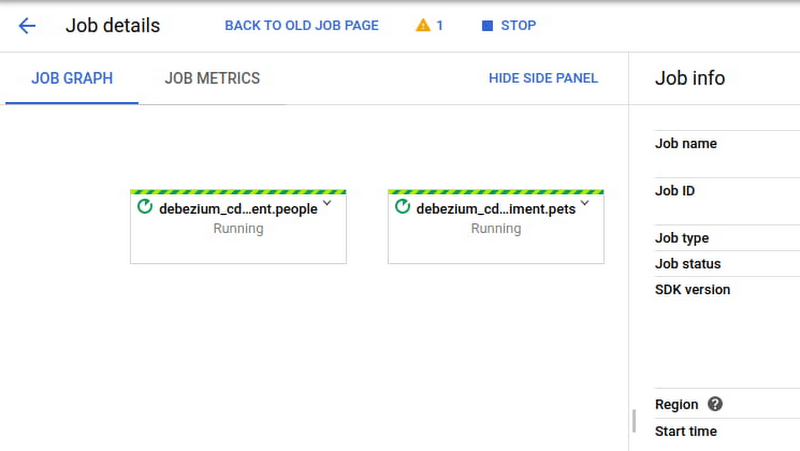
當連接器和 pipeline 開始運行後,您只需監控進度,確保一切正常運作即可。
立即開始執行
有符合 Dataflow CDC 功能的案例嗎?假如您有優化既存的即時分析任務的需求,歡迎嘗試一下 Dataflow 的 CDC 解決方案!首先,您可以使用這個程式碼來開始在 Dataflow 建構您的第一個 CDC pipeline,並在 GitHub issue tracker 上與 Dataflow 團隊分享反饋。
(原文翻譯改編自 Google Cloud。)