本文是一份在 BigQuery 中計算 GA 指標的初心者指南,提供一些範例的查詢指令給讀者參考,希望能省去解讀在 ga_sessions_資料表中的「原始」匹配層級 (hit-level) 資料的時間。(譯註:不知道 GA 蒐集資料的層級、原始匹配層級 (hit-level) 資料是什麼嗎?可以先參考這篇文章的說明,或聯繫 iKala Cloud。)
此篇系列文將涵蓋以下內容,第一篇將針對前五點進行探討:
- BigQuery 中的 Google Analytics 資料簡介
- 查詢多個資料表
- 使用者
- 工作階段 (Session)
- 時間
- 流量來源
- 地理區域
- 平台或裝置
- 網頁追蹤
- 事件追蹤
- 目標追蹤
- 加強型電子商務(交易)
- 電子商務(產品)
- 加強型電子商務(產品)
- 自訂維度與自訂指標
- 自訂管道分組
- 日間 (intraday) 報表
- 即時報表與檢視
BigQuery 中的 Google Analytics 資料簡介
為何要用 BigQuery?
使用 BigQuery 來分析 GA 資料有以下幾項好處:
- 不再被抽樣
- 無限的維度可使用
- 將不同範圍的資料結合至一張報表
- 利用歷史資料計算目標達成數,自建管道分組,並更正數據錯誤
- 整合 GA 數據與第三方數據源
學習門檻高
不過當你發現很多在 GA 上熟悉的指標到 BigQuery 上都找不到時,你可能會非常挫折。BigQuery 讓 GA360 用戶感興趣的點在於,Google 能夠每天將 GA360 的原始未取樣數據匯出到 BigQuery;實現各種無法在 GA 報表內做的分析的同時,代表它並不提供任何像跳出率 (bounce rate) 這類基本的指標可用(來源)。
這將會導致:
難處:使用者必須計算查詢每一個「遺漏的」GA 指標
好處:則是我對於這些指標的概念理解大幅度地增加了。
此外,Standard SQL 語法是目前 BigQuery 建議使用的查詢語法,但很多 Stackoverflow 的文章又使用 Legacy SQL 語法,使用者花了非常多時間確認該下什麼 query 以取得我要的報表。而除了計算指標以外,還有另一個坑:巢狀與重複的結構。(延伸閱讀:BigQuery 教戰手冊)
這篇系列文章將展示如何建立工作階段、使用者等基本的報表,然後提供一些牽涉到匹配層級資料(如事件、pageview)的進階範例,由不同報表整合各種自訂維度、了解(加強型)電子商務資料,並將歷史資料與即時資料做結合。
若您沒有 GCP 的帳單帳戶,您也可以使用 BigQuery 沙箱,它提供你在不創建帳單帳戶的情況下使用 BigQuery。若要將 GA 的資料匯出至 BigQuery,你必須擁有 GA360 帳戶(為 Google Marketing Platform 的一部分)。
BigQuery 中的 Standard SQL
此篇系列文已假設讀者對 SQL 語法有基礎認知且擁有 BigQuery 資料庫,並著重在如何從 BigQuery 取得你想要的 GA 報表做分析。文中所有的查詢範例都是使用 Standard SQL。這篇文章中,我們會以 BigQuery 的 Google Analytics (分析) 樣本資料集作為範例,該資料集的數據來自 Google Merchandise Store。
不過,如果你想比較 GA 報表與自己的查詢結果,我建議讀者使用自己的 GA 資料集,因為我在使用 Google Merchandise Store 樣本資料集時,就發現 GA 報表與我在 BigQuery 查詢的數據有落差,而當我使用其他 GA 帳戶的資料做查詢時,數據就相當吻合。
匯出的欄位
為了更好地理解 BigQuery 中的 ga_sessions_資料表,我們先來看看 BigQuery Export 架構,讓我們對可用的 GA 原始資料有一些概念。即便你熟悉很多 GA 報表介面上的維度與指標,這份匯出架構應該還是很驚人。這份資料集有許多的巢狀欄位。以下示意圖顯示了 ga_sessions_資料表中的兩列資料 (兩個工作階段)。

圖片來源
巢狀欄位範例
你可以發現,當你想要查詢自訂維度、自訂指標或任何匹配層級的資料如:事件數、pageviews、產品等資料時就會遇到一些麻煩。以下我們來查詢一些巢狀資料樣本:
SELECT
*
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_20170801`
LIMIT
2
這樣我們能得到 2 列資料,呈現在表格中如下:
請注意,只有第 2 列與第 14 列是實際的資料列,其他的列數都為巢狀欄位,在大多數的情形下為空值,僅 hits.products 欄位有數值。為了處理這樣的資料結構以符合查詢需求,我們需要 UNNEST 的功能。(您可以閱讀這篇文章,它以 Firebase 的樣本資料集解釋了 UNNEST 的概念。)
你只需要 UNNEST 包含「重複欄位」的資料。它可能包含以下欄位:
使用者/工作階段層級
- customDimensions
匹配層級
- hits
- hits.customDimensions
- hits.customMetrics
產品層級
- hits.product
- hits.product.customDimensions
- hits.product.customMetrics
建議你可以查看這份視圖以了解 BigQuery 的資料結構。

(延伸閱讀:為何你需要一個 CDP?淺談企業管理會員數據的關鍵因素)
查詢多個資料表
GA 的資料會每天儲存至 BigQuery 中,如果你只需要查詢一天的資料,可以下這樣的條件:
SELECT
*
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_20160801`
在大多數的情況下你要查詢的是較長天數的資料,這時可以使用_table_suffix。這裡有更多資訊,不過要查詢多個資料表你只需要使用這些範例。你可以將固定與浮動的日期結合,或單獨查詢固定(譯註:如 2019 年 1/1-1/31)/浮動日期(譯註:如過去 90 天),也能結合 intraday 報表的資料。
固定日期範圍
當你要針對某段絕對的日期範圍進行分析,你可以使用以下方法。我們以「2016 年 8 月 1 日到 2017 年 8 月 1 日」為例:
SELECT
*
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_table_suffix BETWEEN '20160801' AND '20170801'
浮動日期範圍
以下我們以「過去 30 天」為例:
SELECT
*
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_table_suffix BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY))
AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
結合固定日期與浮動日期
我們的資料集有 366 天的資料,所以我們可以使用一個固定日期做查詢(20170801),但通常我習慣使用結合的查詢方式,以固定日期作為開始並以浮動日期作為結束(如:今天-1)。如此一來,一旦有新的資料進來,新的資料就會自動涵蓋在我們的查詢範圍內。以下我以「2016 年 8 月 1 日至昨天」為例:
SELECT
*
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_table_suffix BETWEEN '20160801'
AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
使用者
以下的查詢範例包含所有的 GA 維度與指標。如果你只需要一個維度或指標,請看查詢範例中的註解 (–開頭表註解) 並由 SELECT 複製你要的欄位。另外,為確保查詢資料正確,請確認有加入其他必要的條件(在 FROM, WHERE, GROUP BY 與 ORDER BY)。
使用者:維度
- 使用者類型
- 工作階段數
使用者:指標
- 使用者
- 新使用者
- 新工作階段比例
- 每位使用者的工作階段數
- 匹配數
查詢範例
查詢範例結果
註一:GA v.s. BigQuery 的使用者數
在 GA 報表介面與 BigQuery 中的使用者數差距幾乎都會有 1-2% 的差距。這是因為 GA 報表介面中,除了未取樣報表以外,都是使用一種專門的演算法計算使用者數,而在 BigQuery 中計算使用者數時,則是去計算 distinct fullVisitorIds。因此,可能會有多達 2% 左右的落差。(來源)
註二:涵蓋每一列的資料
計算使用者數時,GA 會將每一列的資料都納入做計算。因此在計算使用者數時,請避免加上 totals.visits = 1 的條件。(來源)
工作階段 (Session)
以下的查詢範例包含所有的GA維度與指標。如果你只需要一個維度或指標,請看查詢範例中的 # comments 並由 SELECT 複製你要的欄位。另外,為確保查詢資料正確,請確認有加入其他必要的條件(在 FROM, WHERE, GROUP BY 與 ORDER BY)。
工作階段:維度
–
工作階段:指標
- 工作階段數
- 跳出
- 跳出率
- 平均工作階段時長
查詢範例
查詢範例結果

註一:有/沒有互動匹配的工作階段 (Session)
GA 報表介面與 BigQuery 之間工作階段數的差距──在 GA 報表介面中,一個工作階段只會在有匹配時才會被計算。如果該工作階段的互動數為 0,則它就不會被 GA 計為有效工作階段。然而 BigQuery 有所有匹配層級的資料,互動數為0的資料也能收至 BigQuery。因此,若要有效比較 GA 報表介面與 BigQuery 之間的工作階段數,應計算有互動匹配數的工作階段。(來源)
註二:為什麼不能用 totals.visits?
假設我們想看每個國家 2016 年 8 月 1 日的工作階段數。
SELECT
geoNetwork.country AS Country,
SUM(totals.visits) AS Sessions
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_20160801`
GROUP BY
1
ORDER BY
2 DESC
LIMIT 5
一如預期,大部分的工作階段都在美國。
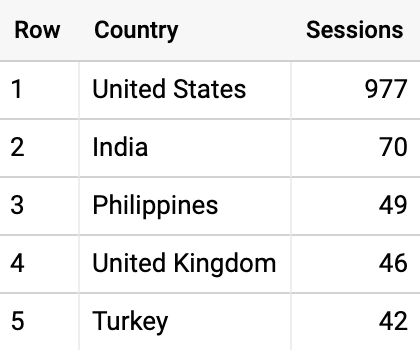
但這是唯一一種查詢工作階段數的方式嗎?不。還有其他可能的方式,每一個都有自己的定義。可參考這裡的解釋。
因為個人還是喜歡知道得比較詳細,所以我在算工作階段數的時候會用 COUNT(DISTINCT CONCAT(fullVisitorId, CAST(visitStartTime AS STRING))),因為這樣能處理午夜工作階段更新的問題,在各種情況下都能使用,包括 UNNEST 的情況(因 UNNEST 可能影響表格中的列數而有重複計算工作階段數的問題):
SELECT
geoNetwork.country AS Country,
COUNT(DISTINCT CONCAT(fullVisitorId, CAST(visitStartTime AS STRING))) AS Sessions
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_20160801`
WHERE
totals.visits = 1
GROUP BY
Country
ORDER BY
Sessions DESC
LIMIT
5
請注意,這邊加了一個 WHERE 條件,我們只計算 totals.visits = 1,也就是有互動的工作階段。因為與 GA 報表介面不同的是,ga_sessions 資料表中的資料會涵蓋「全部的工作階段」,包含 totals.visits = 0 沒有互動的工作階段。
時間
以下的查詢範例包含所有的 GA 維度與指標。如果你只需要一個維度或指標,請看查詢範例中的註解 (–開頭表註解) 並由 SELECT 複製你要的欄位。另外,為確保查詢資料正確,請確認有加入其他必要的條件(在 FROM, WHERE, GROUP BY 與 ORDER BY)。
時間:維度
日期
年
ISO 年
月份數
週數 (全年第幾週)
ISO 週數
天數(每月)
天數(每週)
小時
分鐘
小時數(每天)
當日小時與分鐘
時間:指標
–
查詢範例
查詢範例結果
註一:時區格式
Bigquery 通常使用 UTC 時區格式,這可能會在格式化時間的時候造成問題。請記得先轉換時區以解決相關問題。(來源)
下一篇系列文將針對「流量來源」、「地理區域」、「平台或裝置」、「網頁追蹤」做說明。
(原文翻譯自此。)