說到確保應用程式的可用性,建立並監控服務層指標十分重要,而這也是 Google 網站可靠性工程 (Site Reliability Engineering, SRE) 團隊在 Google 的日常,他們 SRE 的基礎原則就是改善服務,進而優化使用者體驗。
SRE 的概念要從「測量指標應與商業目標密切相關」的這個想法開始,除了事業層級的服務水準合約 (SLA),在 SRE 的規畫實踐中,也會使用 SLO 與 SLI。接下來,我們就透過這篇文章帶您了解這三者的差異,幫助您了解 Google Cloud 的 SLI、SLO、SLA 是如何定義,而您又該如何著手制定適合您的指標。
定義網站可靠性工程 (SRE) 的專用術語
這些工具不只是一些抽象名詞,沒有它們,您無從得知您的系統是否可靠、可用、甚至是否有效。如果這些工具沒有回歸到您的商業目標,便無法透過這些工具得相關資料,您將無從得知您做的選擇對您的商業營運來說,究竟是幫助還是損害。
SRE 的概念首先提到「可用性是成功的先決條件」。一個不可用的系統無法執行其功能,自然而然會失敗。在 SRE 術語中,可用性定義了系統是否能夠在某個時間點執行其預期功能。除了作為報告工具的功用之外,可用性測量的歷史資料,還能夠描述您的系統在未來按預期計畫執行的機率。
接下來,我們就來看看以下 SLI、SLO 和 SLA 的介紹,就像 Google 的 SRE 團隊在部落格文章中所討論的。
一、服務水準指標 (Service-Level Indicator, SLI)
Google Cloud 的服務水準指標 (Service-Level Indicator, SLI) 是用來衡量服務的使用情況的量化指標,類似對服務的健康狀態設定效能衡量。
SLI 範例:
- 300ms 的請求延遲
- HTTP 狀態碼為 200 的回應次數,佔總回應次數的比率
像是 request latency、system throughput、failure per request 等,都是常見被用來了解服務效能的 SLI 指標。
藉由測量,SRE 就可以訂定閾值 (threshold),當指標達到某個數值時,則代表這個服務效能是好或壞。SRE 會查看 SLI 以了解其系統是否有符合一定的服務水準。如果它低於指定的該指標過低,可能就需要其他的方式來穩定系統,例如在不同的城市運行第二個 instance 並在兩者之間運行負載平衡。如果您想知道您的服務運行的穩定度,您必須能衡量成功和不成功查詢的比率作為您的 SLI。
延伸閱讀:自定義 Cloud Monitoring 儀表板,有效監控服務效能
二、服務水準目標 (Service-Level Objective, SLO)
測量了 SLI 之後,我們要為系統可用性設定一個更精確的目標,重點是要與一段時間做掛勾來衡量服務期望狀態、目標範圍,我們把這個命名為系統的服務水準目標 (Service-Level Objective , SLO)。
SLO 是由以下三種元素組成:SLI、一段時間區間、目標(通常以百分比呈現)。
在這三個要素中,制定「時間區間」與「目標」會比較困難。您可以先確定 SLI,並衡量其隨著時間的變化。而未來討論系統是否會可靠運行、以及是否需要任何設計或架構上的修改,都要遵循讓系統符合 SLO 此一原則。
SLO 範例:在一個月之中,99.9% 的請求延遲有在 300ms 內
為何 SLO 的百分比不是越高越好?我們為什麼不設定一個 100% 的目標呢?請記住,服務越可靠,運作成本就越高。先定義每個服務的使用者可接受的最低可靠性水準,然後將其指定為您的 SLO。每個服務都應該有一個 SLO —— 沒有它的話,您的團隊和您的利害關係人就無法對您的服務做出判斷像是:讓服務變得更可靠(增加成本並拉長開發時程)或是要降低可靠性(容許更快的開發速度)。過度的可用性已變成預期中的狀況的話,這可能會造成問題。如果您的使用者對於服務的體驗並不需要過高的可靠性,請不要讓您的系統過度可靠,尤其是當您不保證服務會一直達到該水準時。
以 Google Cloud 來說,Google Cloud 對某些服務會實施定期停機,以防止服務的可用性過度。您也可以嘗試對前端伺服器實施間歇性、有計劃的停機,如同我們對我們其中一個內部系統所做的。這樣的作法,可能幫您找出伺服器使用不恰當的服務。有了這些資訊,您就可以將工作負載,移到更合適的位置,並且將伺服器保持在正確的可用性水準。
三、服務水準協議 (Service-Level Agreement, SLA)
SLA 通常是關乎對服務使用者的承諾,是一項基於 SLO 制定的商業合約,當中會承諾其 SLO 應在一段時間內達到特定水準,若未達到一段時間內保證的目標則會產生罰則,比如向客戶退款,或免費提供客戶更長的服務訂閱時間等。超出 SLO 會傷害到整體業務團隊,因此服務應努力保持在 SLO 內。
正因如此,而且出於可用性不應高於 SLO 太多的原則,通常在 SLA 中訂定的可用性 SLO,會設定得比內部的可用性 SLO 更寬鬆。這可能會以可用性的數值表示:例如,一個月內的可用性 SLO 為 99.9%,而內部可用性 SLO 為 99.95%。或者,SLA 可能僅指定一些內部 SLO的測量指標。
如果您 SLA 中的 SLO 與您的內部 SLO 不同(大部分的情況),那麼您的監控軟體必須明確地測量 SLO 的合規性。理想上,您要能夠查看系統在 SLA 工作排程中的情況,並查看是否有超出 SLO 的危險範圍。
建議您也需要透過 log 分析,來對合規性進行精確的測量。舉例來說,由於 Google Cloud 對付費客戶有一組額外的義務(在 SLA 中有提到),因此他們需要把從付費使用者收到的查詢資料與其他查詢資料分開測量。這是建立 SLA 的另一個好處 —— 明確地區分流量的優先順序。
在定義 SLA 的可用性 SLO 時,需注意哪些查詢是您定義為合法的。例如,如果客戶因為發布了錯誤版本的行動裝置軟體而超出配額,您可以考慮從您的 SLA 額度中排除所有「超額」的程式。
如果您是重新開始構建系統,請確保 SLI 和 SLO 為系統的必要要求。如果您已經有一個生產系統,但還沒有被明確定義,那麼這將會是您最優先的工作。
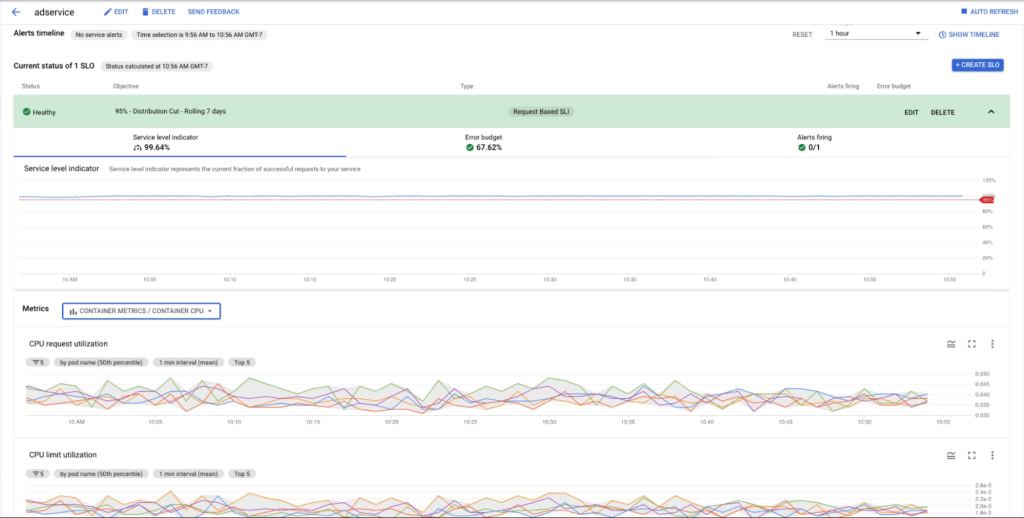
您可以在此處了解如何在 Cloud Monitoring 中設置 SLO,或透過這份指南了解更多設定 SLO 的方式。如果對於 Google Cloud 的服務有任何問題,也歡迎聯繫 iKala Cloud 由專人為您服務。
(本文翻譯改編自 Google Cloud。)
參考資料