
在系列文的第一篇中,我們為大家科普了預測性維護 (predictive maintenance) ;預測性維護會識別感應器和產量資料中的特定模式,這些模式會顯示設備狀況的變化(特定的穿戴式裝備)。借助預測性維護功能,公司可以確定資產的剩餘量,並準確預測機器、組件或零件何時可能發生故障需要更換。
在我們的系列文的第二篇,我們將解釋一些資料探索技術,對機器學習的類別進行比較,並以範例來探討執行「預測性維護」時的一些公式和指標。
一、資料探索
資料探索 (data exploration) 階段的目標是確認你的資料有隱含特定模式 (pattern)。此階段也能幫您驗證解決問題的可行性:是否可以使用您擁有的資料集構建模型。
- 如果您想對「設備是否會發生故障」進行分類,那麼您可能會希望看到指示故障的信號提示。
- 如果您要預測「機器的剩餘壽命」,在資料探索階段,您就會期待看到一個類似下圖這樣壽命衰退的固定模式。


一般來說,隨著設備的老化,其速度、效率和工作效率都會下降。同樣,設備衰退老化時可能也會造成過熱、噪音或振動的情形。如果您在資料探索階段中有發現這樣的特定模式,則很有可能預測性維護模型,會被驗證是有效的。
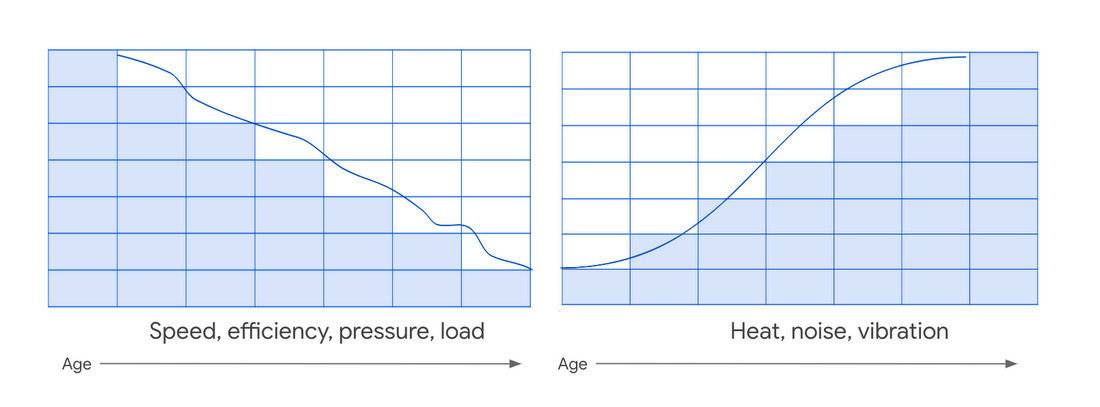
如果資料集在視覺化時,並未顯示明顯特徵,則您可以考慮在資料集或資料可視化中,添加更多特徵。
二、特徵工程 (feature engineering) 方法
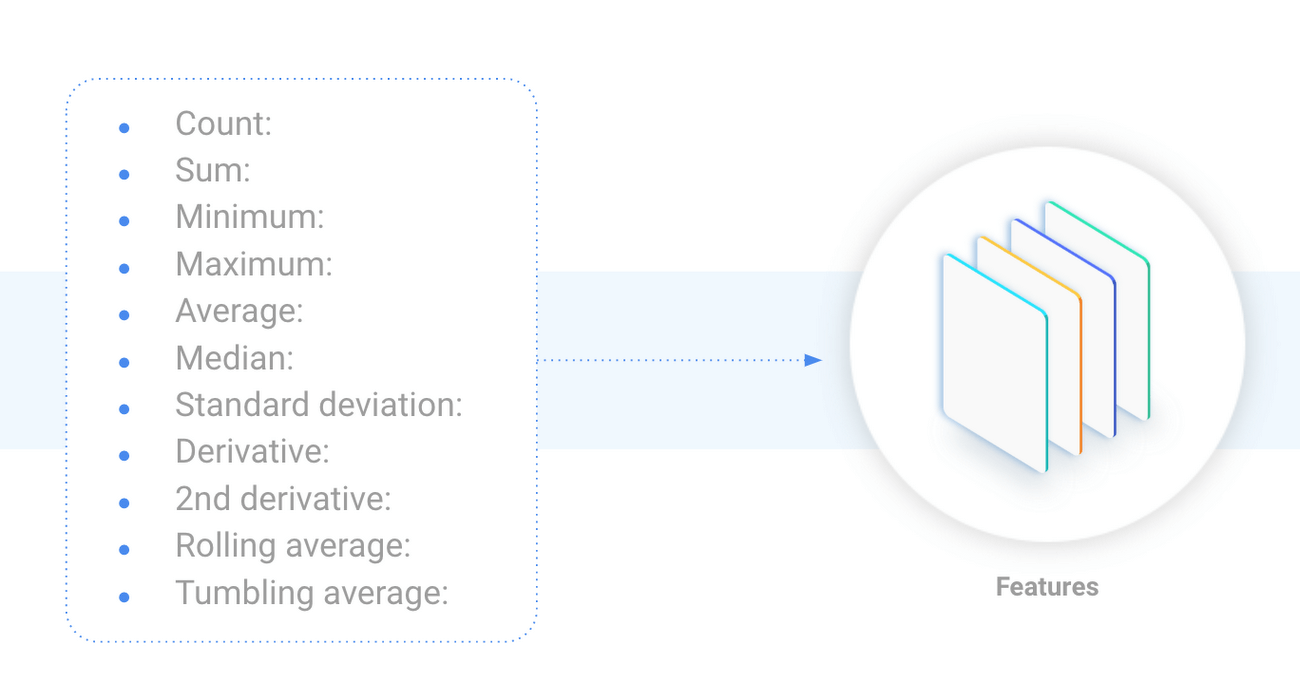
透過特徵工程,您可以將資料轉換為機器學習演算法可以使用的格式。例如:
- 設備的溫度可能會波動,但是隨著設備的退化,平均設備溫度可能會穩定上升。如果您計算一天中的機器平均溫度,則或許可以清楚地顯示出機器的壽命。
- 延長機器使用時間可能會增加最大
- 振動。一件設備可能會振動,但在故障發生前的最後幾天可能會顯示出強烈的振動。使用最大振動作為特徵將有助於您建立有用的模型。
- 移動平均值(重疊和不重疊)都可能隨著機器衰退老化而改變。

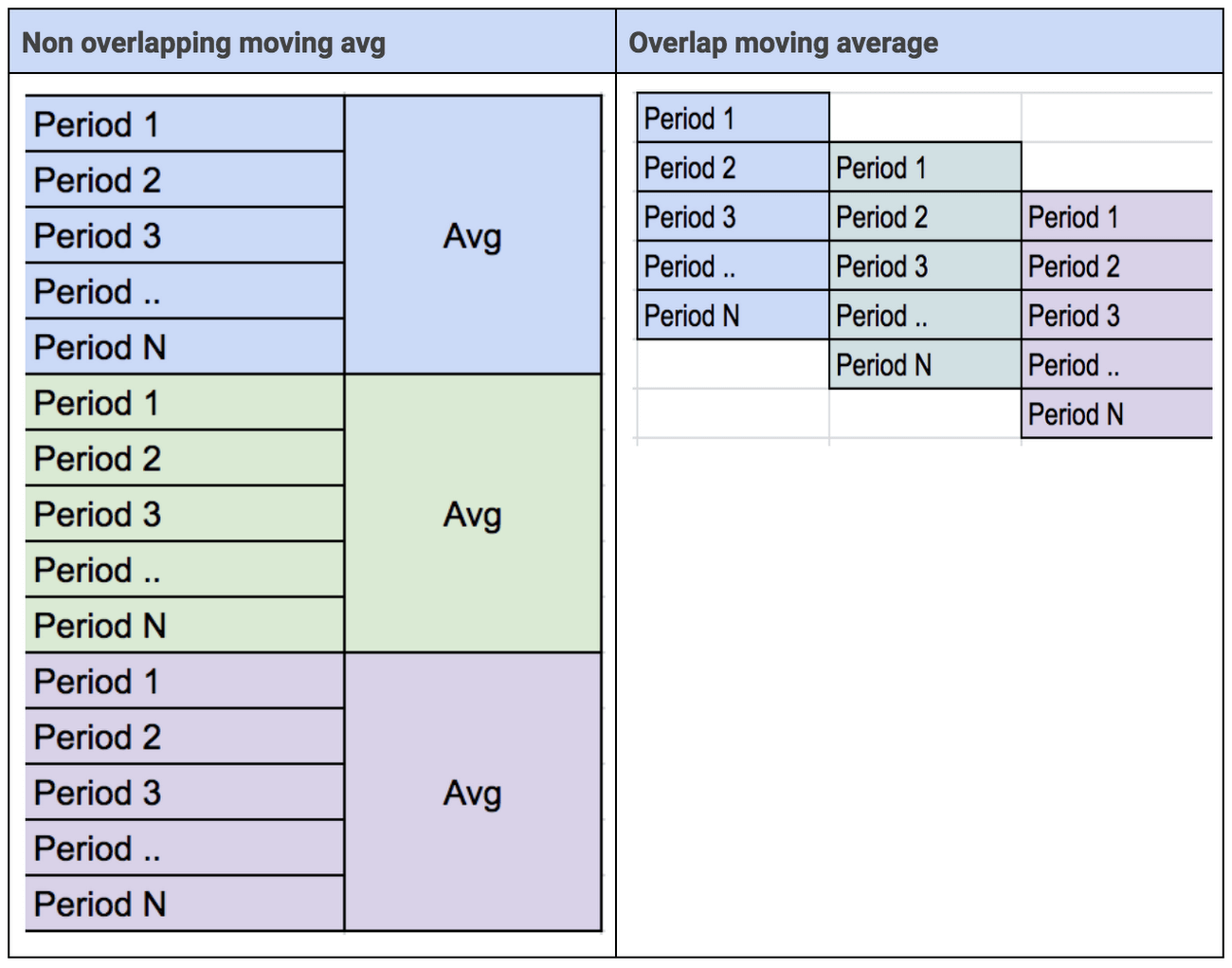
以下是一些您可以用來做特徵工程的簡單功能:
三、使用的模型架構和演算法
建立好特徵檢測器後,下一步就是決定你要在模型構建階段,使用什麼演算法。
根據您的使用情境,您應該決定以下:
- 監督式或非監督式學習方法 (supervised / unsupervised)
- 分類或迴歸方法 (classification / regression)
- 傳統機器學習或深度學習 (deep learning) 方法
監督式學習
如果您標記了資料集中的機器故障特徵,請使用監督學習。傳統 ML 會找尋資料集中的固定模式。深度學習可以找到在固定模式中的固定模式,甚至隱藏的固定模式。
關於監督式學習中最常見的「分類」與「迴歸」,您可以參考 iKala Cloud 的這篇文章。
傳統機器學習 v.s. 深度學習
傳統的 ML 或 DNN 模型可處理單個資料點值。有時,資料序列會顯示故障信號,例如尖峰。 為了找到這樣的模式,您需要一個可以在序列中找到模式的演算法。循環神經網絡 (RNN) 於 1980 年設計用於解決此特定問題:RNN 具有內部記憶體,可幫助其查找整個序列的模式,例如尖峰。
進階的深度學習模型
RNN 模型最初是為語言設計的,例如翻譯、語音和自然語言的應用情境。句子可以定義為單詞的序列,RNN 模型會透過記住這些單詞序列來處理前後文。
物聯網 (IoT) 資料通常也包含序列。從順序資料中學習時,自然會考慮使用 Hidden Markov Models 和 RNN 模型。前者可以根據當前狀態預測狀態。而 RNN 模型在使用所有先前狀態預測狀態時更有用,因為 RNN 可以在 t 個時間點的倒傳播中展開。

從這個意義上講,RNN 通常對時間序列資料有效。但是,RNN 在記住序列中很久以前發生的輸入可能會有難度。也就是說,RNN 難以維持長期的相依性。這是由於損失函數的梯度隨時間呈指數衰減。
儘管 RNN 模型可以很好地處理序列資料,但在序列的長度存在局限性。Long Short Term Memory (LSTM) 是 RNN 模型架構的一種變體。給定的 LSTM 模型能夠學習資料序列中的長期相依性。如果您有一系列 IoT 資料,並且故障徵兆分佈在整個序列中,則 LSTM 模型架構可以識別這些模式並構建模型以對其進行檢測。
非監督式演算法
在很多情況下,您會希望識別出異常的行為或模式。當你在預期的模式時,識別異常的功能很有用。您可以監控系統的健康狀況,並在觀察到異常行為時觸發警報。有許多統計和機器學習方法可以識別系統中的異常。
傳統機器學習 v.s. 深度學習
自動編碼器 (Autoencoders) 是一種基於神經網絡的方法,通常用於查找複雜向量中的異常。他們使用倒傳遞並將目標值設置為等於輸入值。使用自動編碼器可以創建基准值或識別複雜向量中的異常。
指標
機器學習模型建構中最重要的設計決策(或問題)是:「要針對哪個指標進行優化?」您應該基於商業目標選擇一個指標。
如果您的資料集具有 99.5% 的良好資料和 0.5% 的失敗資料,您只需將每個資料分類為「良好」,就可以達到 99.5% 的準確度 (accuracy)。但這樣很顯然地,對於要識別「罕見故障」的情況,準確度 (accuracy) 可能不是合適的指標。
以下是您在回答業務問題時要考慮的幾個常見指標:
「二元分類」的常見指標
在此之前,讀者需要對「混淆矩陣」(confusion matrix) 有一定的理解。推薦您閱讀這篇文章。了解 TP、FP、FN、TN 各自的概念後,我們再來介紹在分類問題中,常見的判斷模型的指標。
以下,我們假設「正確地預測設備會故障」為 TP 來討論。
|
實際為真 |
實際為假 |
|
|
預測為真 |
TP (True Positive) |
FP (False Positive) |
|
預測為假 |
FN (False Negative) |
TN (True Negative) |
1. Precision
Precision 將回答以下問題:在被分類為「預測將故障」的設備中,有多少比例的預測是正確的?
Precision = tp/(tp+fp)
2. Recall / Sensitivity
Recall 會回答這樣的問題:在「實際發生故障」的設備中,有多少比例的預測是正確的?
Recall, or Sensitivity = tp/(tp+fn)
3. Accuracy
Accuracy 是指所有試驗的正確程度。它是「正確預測」與全部範例之間的比例。
如果多個類別的發生率保持平衡,則 Accuracy 是一個很好的衡量標準。但是,如果您要在故障總數很小的情況下嘗試查找故障,則 Accuracy 性不是一個好的指標。
Accuracy = tp+tn/(tp+tn+fp+fn)
4. F1 score
F1 score 是 Precision 和 Recall 這兩個值的調和平均數。
F1 = 2 *(precision*recall) / (precision + recall)
5. True positive rate
TPrate 指「被正確預測」的「故障實例」的百分比。
TPrate 又被稱為 Sensitivity 或 Recall,代表「預測為真且實際為真」佔實際為真的百分比。
TPrate = TP/(TP+FN)
6. True negative rate
TNrate 指「被正確預測」的「非故障實例」的百分比。
TNrate = TN/(TN+FP)
7. False positive rate
FPrate 指「被錯誤預測」的「非故障實例」的百分比。
FPrate = FP/(FP+TN)
8. False negative rate
FNrate 指「被錯誤預測」的「故障實例」的百分比。
FNrate = FN/(FN+TP)
ROC (receiver operating characteristic) curve
ROC (receiver operating characteristic) 曲線
ROC 曲線顯示了當使用不同的決策閾值時,給定模型的預測如何產生不同的 TP 與 FP 率。當我們降低閾值時,我們可能會有更多的 FP,但也會增加我們發現的 TP 數量。
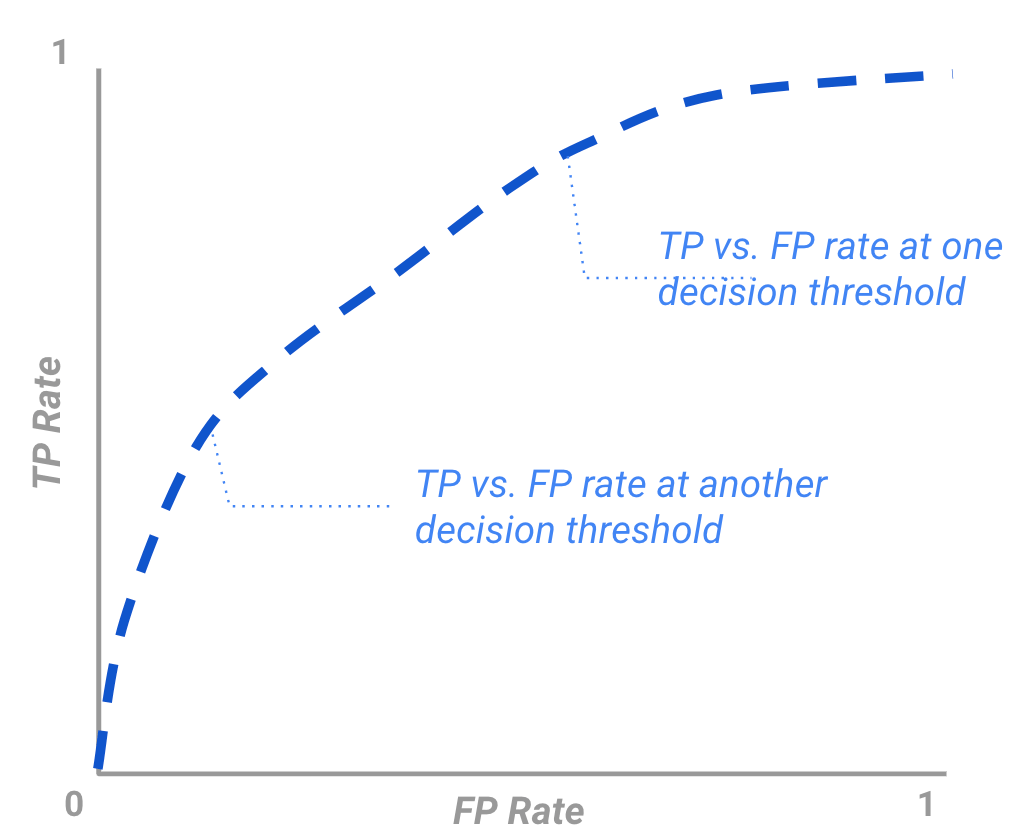
「多類別分類」的常見指標
要評估多類別分類模型的機器學習模型的質量,也可以使用「混淆(誤差)矩陣」(confusion (error) matrix)。在多類別分類的混淆矩陣中,每一行代表真實類別的實例數,每一列代表預測類別獲得的實例數。 因此,對角線方格中的值,代表預測數量等於真實數量(正確預測)的點數。同理,非對角線方格中的值,則是那些被分類器「貼錯標籤」(錯誤預測)的點數。
非對角線方格中的較高值表示模型的預測不正確。應該在此類方格上進行錯誤分析,以了解該模型如何在不同類別之間產生分類錯誤。
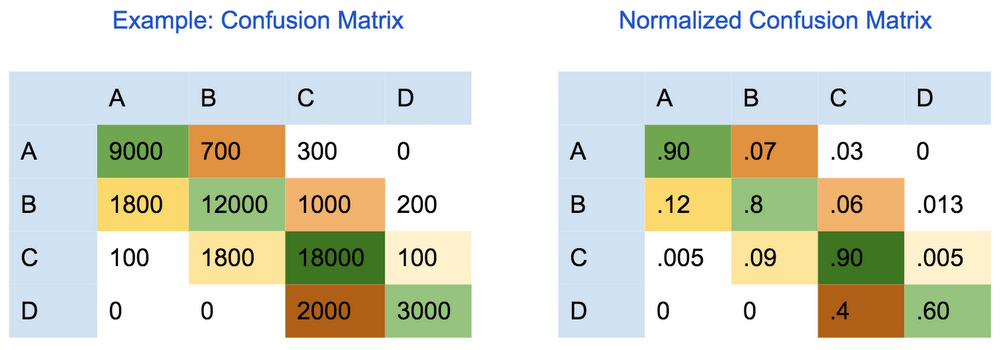
宏觀和微觀平均值的 Precision、Recall 與 Accuracy
Precision、Recall 與 Accuracy 是二元分類問題中的重要指標。而當處理多類別分類問題時,通常有 2 種方法來計算 Precision、Recall 與 Accuracy。
1. Micro-precision/recall
這裡是為每個「實例」分配相等的權重。在這種方法中,微平均值將在計算平均值時匯總所有類別的貢獻。也就是說,您對各個 TP、FP、TN、FN 值求和。因此,所有實例在計算 precision 和 recall 時都具有同等的權重。
2. Macro-precision/recall
這邊則是為每個「類別」分配相同的權重。使用 Macro-precision/recall,您可以計算每個類的 precision 和 recall,然後取平均值。
迴歸問題的常見指標
若要預測設備的剩餘使用壽命,通常使用迴歸指標。常見指標包含:
1. 平均絕對誤差
平均絕對誤差 (mean absolute error, MAE) 測量預測值和實際值之間的差異,並獲得平均差異。 您應該使用絕對差,將其求和,然後除以樣本數。
2. 根均方誤差
均方根誤差 (Root Mean Square Error, RMSE) 與 MAE 相似,不同之處在於它會更大程度地懲罰較大的誤差。RMSE 對預測值和實際值之間的差異求平方,計算平均差異,然後取該平均差異的平方根。
3. 平均絕對百分比誤差
平均絕對百分比誤差 (Mean absolute percentage error, MAPE) 以百分比的形式衡量誤差的大小,因此 MAPE 更易於理解。當實際值不一致時,可以使用 MAPE 更好,並且,您可以使用百分比對值進行正規化。
結論
在建立用於預測性維護的機器學習模型時,重要的是,要驗證資料是否具有能顯示設備隨著使用年限或使用情況而退化的固定模式。
要開始預測性維護專案,請先定義系列文第一篇中提到的應用案例,確定您對設備故障的定義。然後,確保您已經擁有或可以生成與用例匹配的資料集。為了驗證資料集是否具有用於構建模型的匹配模式,您可以使用簡單的資料探索技術,來確定資料是否包含衰退或故障的特定模式。一旦找到了模式的證據,就可以開始構建模型了。
如果原始資料 (raw data) 未顯示出衰退的模式,則您可以執行特徵工程並將資料置於突出顯示機械退化的狀態(形狀)中。如果您可以在資料探索期間看到衰退模式,則機器學習模型很的精準度應該也會相當之高。
此外,深度學習技術則能夠查找以一般資料探索技術所看不見的潛藏特定模式。您可以考慮使用深度學習,因為它可以在傳統機器學習無法找到的模式中找到模式。
通常,原始資料不會直接顯示出模式,但是隱含模式存在於尖峰或其他序列類型中。深度學習提供了很好去處理序列的 RNN 和 LSTM 建模架構。
當您準備好資料後,請選擇演算法來訓練您的機器學習模型。構建模型的初始版本後,請專注於微調模型以根據您選擇的指標獲得更高的準確性。選擇適合您團隊和業務目標的正確指標相當重要。
在系列文的最後一篇,我們將提供一些有用的範例,來說明各種類型的模型,其實際應用情況。
(本文翻譯改編自 Google Cloud。)
延伸閱讀: