集結國內外精選文章,掌握最新雲端技術新知與應用
Cloud Machine Learning 是 Google Cloud Platform 對於深度學習提供的管理服務。它可以讓您建立作用於任何大小、任何資料的學習模型,並藉由 TensorFlow 框架打造您的服務。您立即可以將訓練模型放置於全球的 prediction 平台,能支持成千上萬的使用者與 TB 等級的資料。除此之外,此項服務同時整合了 Cloud Dataflow, Cloud Storage 甚至 BigQuery。現在我們就來使用看看如何簡單的進行手把手 Cloud Machine Learning:
這一次我們使用花的 dataset 來實作客製化的辨識模型,以下將帶來四個部分:資料預處理、訓練模型、模型部署、預測結果。
部署環境限制,目前台灣 (asia-east1) 也已開放 Tensorflow 的服務。
https://cloud.google.com/ml-engine/docs/tensorflow/environment-overview#cloud_compute_regions
部署區域與價格
https://cloud.google.com/ml-engine/docs/pricing
打開 Google Cloud Shell 並從 GitHub 下載範例程式,以下的步驟使用者需要有 Editor 的權限才能運作。
解壓縮該檔案並移動路徑至 flowers 的目錄底下,以下的指令都需要再 flowers 的目錄底下執行:
wget https://github.com/GoogleCloudPlatform/cloudml-samples/archive/master.zip
unzip master.zip cd cloudml-samples-master/flowers
這邊需要特別注意,原先的教學使用的版本過舊,需要手動更新套件的版本
vim requirements.txt
更新 apach-beam 套件至 2.4.0,並儲存檔案
使用 pip 來下載所需要的套件
pip install --user -r requirements.txt
至 GCP Project 啟用 Cloud Machine Learning Engine and Compute Engine APIs
安裝並初始化 Cloud SDK
安裝 Tensorflow
pip install --user --upgrade tensorflow
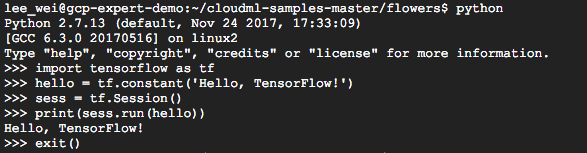
如果成功會出現以下的訊息
安裝完 Tensorflow 後可以照著此連結的步驟,測試 Tensorflow 是否成功安裝,結果如下:
設置 Cloud Storage Bucket 設置 Project 以及 Bucket 的環境變數 PROJECT_ID=$(gcloud config list project --format "value(core.project)") BUCKET_NAME=${PROJECT_ID}-mlengine 確認 Project id 以及 Bucket 的名稱是否正確 echo $PROJECT_ID echo $BUCKET_NAME 選定一個 可以跑Cloud ML service 的 Region (例如:us-central1) REGION=us-central1 新建一個 Bucket,成功結果如下圖 gsutil mb -l $REGION gs://$BUCKET_NAME 使用 gsutil list 查看是否成功創立,並注意之後都要在 us-central1 上執行其他 job 宣告變數 請注意 Bucket 名稱 與 Region 名稱需要使用者自行設定 declare -r BUCKET_NAME="gs://${BUCKET_NAME}" declare -r REGION="${REGION}" declare -r PROJECT_ID=$(gcloud config list project --format "value(core.project)") declare -r JOB_NAME="flowers_${USER}_$(date +%Y%m%d_%H%M%S)" declare -r GCS_PATH="${BUCKET_NAME}/${USER}/${JOB_NAME}" declare -r DICT_FILE=gs://cloud-ml-data/img/flower_photos/dict.txt declare -r MODEL_NAME=flowers declare -r VERSION_NAME=v1 echo "Using job id: " $JOB_NAME set -v -e 資料預先處理 本次教學所使用的資料都已經事先標籤完畢,並分為 10% 的 Evaluation data (訓練資料)以及 90% 的 Training data (預測資料)。運用 Google Cloud Dataflow 來進行 Evaluation data 的預處理 python trainer/preprocess.py \ --input_dict "$DICT_FILE" \ --input_path "gs://cloud-ml-data/img/flower_photos/eval_set.csv" \ --output_path "${GCS_PATH}/preproc/eval" \ --cloud 可以至 Dataflow 的 UI 介面查看目前 job 的運行狀況,或是開啟新的一個 Cloud Shell 輸入以下指令 gcloud dataflow jobs list export JOB_ID="上方指令印出的 JOB ID" gcloud beta dataflow logs list $JOB_ID --importance=detailed 接著進行 Training data 的預處理。如果需要查看 job 的運行狀況,如同上方的步驟。 python trainer/preprocess.py \ --input_dict "$DICT_FILE" \ --input_path "gs://cloud-ml-data/img/flower_photos/train_set.csv" \ --output_path "${GCS_PATH}/preproc/train" \ --cloud 訓練模型 準備好要訓練的資料後,即可以在 Cloud ML Engine 上執行訓練的動作 gcloud ml-engine jobs submit training "$JOB_NAME" \ --stream-logs \ --module-name trainer.task \ --package-path trainer \ --staging-bucket "$BUCKET_NAME" \ --region "$REGION" \ --runtime-version=1.4\ -- \ --output_path "${GCS_PATH}/training" \ --eval_data_paths "${GCS_PATH}/preproc/eval*" \ --train_data_paths "${GCS_PATH}/preproc/train*" submit 成功會出現以上訊息,訓練機器大約需要等待 15 分鐘 部署並預測與檢驗成果 建立一個 Cloud ML Engine model gcloud ml-engine models create "$MODEL_NAME" \ --regions "$REGION" 建立第一個版本的模型,此步驟促使訓練好的模型部署到一個 Cloud instance,進而準備讓使用者預測。部署一個新的版本需要等待大約 10 分鐘 gcloud ml-engine versions create "$VERSION_NAME" \ --model "$MODEL_NAME" \ --origin "${GCS_PATH}/training/model" \ --runtime-version=1.4 部署完模型之後,複製一張測試圖片以進行預測請求 gsutil cp \ gs://cloud-ml-data/img/flower_photos/daisy/100080576_f52e8ee070_n.jpg \ daisy.jpg 新增一個 JSON 的請求檔案並把圖片進行 base64 encode python -c 'import base64, sys, json; img = base64.b64encode(open(sys.argv[1], "rb").read()); print json.dumps({"key":"0", "image_bytes": {"b64": img}})' daisy.jpg &> request.json 呼叫預測的 API,並出現以下的結果:(雛菊 – 0, 蒲公英 – 1, 玫瑰 – 2, 向日葵 – 3, 鬱金香 – 4) 本次預測為 99.936% 為 雛菊 gcloud ml-engine predict --model ${MODEL_NAME} --json-instances request.json 清除資料 清除剛剛創建的 Cloud Storage Bucket gcloud ml-engine predict --model ${MODEL_NAME} --json-instances request.jsongsutil rm -r gs://$BUCKET_NAME/$JOB_NAME 結語 這次實作的部分是最基礎的應用,Cloud Machine Learning 完美的和 TensorFlow 搭配,必定還有夠多樣的殺手級應用等您挖掘。請繼續關注 GCP專門家 – 中文技術部落格的最新消息! (原文翻譯自 Google Cloud。)
設置 Project 以及 Bucket 的環境變數
PROJECT_ID=$(gcloud config list project --format "value(core.project)") BUCKET_NAME=${PROJECT_ID}-mlengine
確認 Project id 以及 Bucket 的名稱是否正確
echo $PROJECT_ID echo $BUCKET_NAME
選定一個 可以跑Cloud ML service 的 Region (例如:us-central1)
REGION=us-central1
新建一個 Bucket,成功結果如下圖
gsutil mb -l $REGION gs://$BUCKET_NAME
使用 gsutil list 查看是否成功創立,並注意之後都要在 us-central1 上執行其他 job
請注意 Bucket 名稱 與 Region 名稱需要使用者自行設定
declare -r BUCKET_NAME="gs://${BUCKET_NAME}" declare -r REGION="${REGION}" declare -r PROJECT_ID=$(gcloud config list project --format "value(core.project)") declare -r JOB_NAME="flowers_${USER}_$(date +%Y%m%d_%H%M%S)" declare -r GCS_PATH="${BUCKET_NAME}/${USER}/${JOB_NAME}" declare -r DICT_FILE=gs://cloud-ml-data/img/flower_photos/dict.txt declare -r MODEL_NAME=flowers declare -r VERSION_NAME=v1 echo "Using job id: " $JOB_NAME set -v -e
本次教學所使用的資料都已經事先標籤完畢,並分為 10% 的 Evaluation data (訓練資料)以及 90% 的 Training data (預測資料)。運用 Google Cloud Dataflow 來進行 Evaluation data 的預處理
python trainer/preprocess.py \ --input_dict "$DICT_FILE" \ --input_path "gs://cloud-ml-data/img/flower_photos/eval_set.csv" \ --output_path "${GCS_PATH}/preproc/eval" \ --cloud
可以至 Dataflow 的 UI 介面查看目前 job 的運行狀況,或是開啟新的一個 Cloud Shell 輸入以下指令
gcloud dataflow jobs list export JOB_ID="上方指令印出的 JOB ID" gcloud beta dataflow logs list $JOB_ID --importance=detailed
接著進行 Training data 的預處理。如果需要查看 job 的運行狀況,如同上方的步驟。
python trainer/preprocess.py \ --input_dict "$DICT_FILE" \ --input_path "gs://cloud-ml-data/img/flower_photos/train_set.csv" \ --output_path "${GCS_PATH}/preproc/train" \ --cloud
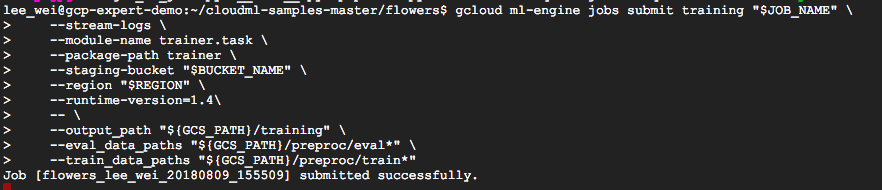
準備好要訓練的資料後,即可以在 Cloud ML Engine 上執行訓練的動作
gcloud ml-engine jobs submit training "$JOB_NAME" \ --stream-logs \ --module-name trainer.task \ --package-path trainer \ --staging-bucket "$BUCKET_NAME" \ --region "$REGION" \ --runtime-version=1.4\ -- \ --output_path "${GCS_PATH}/training" \ --eval_data_paths "${GCS_PATH}/preproc/eval*" \ --train_data_paths "${GCS_PATH}/preproc/train*"
submit 成功會出現以上訊息,訓練機器大約需要等待 15 分鐘
建立一個 Cloud ML Engine model
gcloud ml-engine models create "$MODEL_NAME" \ --regions "$REGION"
建立第一個版本的模型,此步驟促使訓練好的模型部署到一個 Cloud instance,進而準備讓使用者預測。部署一個新的版本需要等待大約 10 分鐘
gcloud ml-engine versions create "$VERSION_NAME" \ --model "$MODEL_NAME" \ --origin "${GCS_PATH}/training/model" \ --runtime-version=1.4
部署完模型之後,複製一張測試圖片以進行預測請求
gsutil cp \ gs://cloud-ml-data/img/flower_photos/daisy/100080576_f52e8ee070_n.jpg \ daisy.jpg
新增一個 JSON 的請求檔案並把圖片進行 base64 encode
python -c 'import base64, sys, json; img = base64.b64encode(open(sys.argv[1], "rb").read()); print json.dumps({"key":"0", "image_bytes": {"b64": img}})' daisy.jpg &> request.json
呼叫預測的 API,並出現以下的結果:(雛菊 – 0, 蒲公英 – 1, 玫瑰 – 2, 向日葵 – 3, 鬱金香 – 4) 本次預測為 99.936% 為 雛菊
gcloud ml-engine predict --model ${MODEL_NAME} --json-instances request.json
清除資料 清除剛剛創建的 Cloud Storage Bucket gcloud ml-engine predict --model ${MODEL_NAME} --json-instances request.jsongsutil rm -r gs://$BUCKET_NAME/$JOB_NAME 結語 這次實作的部分是最基礎的應用,Cloud Machine Learning 完美的和 TensorFlow 搭配,必定還有夠多樣的殺手級應用等您挖掘。請繼續關注 GCP專門家 – 中文技術部落格的最新消息! (原文翻譯自 Google Cloud。)
清除剛剛創建的 Cloud Storage Bucket
gcloud ml-engine predict --model ${MODEL_NAME} --json-instances request.jsongsutil rm -r gs://$BUCKET_NAME/$JOB_NAME
這次實作的部分是最基礎的應用,Cloud Machine Learning 完美的和 TensorFlow 搭配,必定還有夠多樣的殺手級應用等您挖掘。請繼續關注 GCP專門家 – 中文技術部落格的最新消息!
(原文翻譯自 Google Cloud。)