上一篇文章,我們介紹了 Explainable AI,並使用公開資料集預測「自行車租賃的騎乘時間」。若您尚未閱讀,可以參考這篇部落格文章。
延續上篇介紹的內容,您還可以獲得關於部署到 AI 平台的客製化 TensorFlow 模型之解釋。以下我們會介紹如何利用將 AI Explanations 模型部署到 Google Cloud AI 平台,並用 What-If 將模型結果視覺化。
準備一個要部署的模型
當我們將 AI Explanations 模型部署到 AI 平台時,需要為模型選擇一個基準輸入 (baseline input)。在我們為表格式模型選擇基準時,可將其看作是來幫您識別資料集中的離群值。在此範例中,我們將基準值設為所有輸入值 (input values) 的中位數,該值是使用 Pandas 套件運算的。
由於我們在 AI 平台上使用的是客製化的 TensorFlow 模型,因此需要告訴 Explanations 服務「我們希望從 TensorFlow 的模型圖表獲得哪些 tensor 的解釋」。我們將 AI Explanations 的基準和 tensor 清單儲存在 explanation_metadata.json file 中,並將此檔案上傳到與 SavedModel 相同的 GCS 值區 (bucket)。
從 AI 平台獲取歸因值
一旦部署完附帶解釋的模型後,便可利用 AI 平台 Prediction API(預測 API)或 gcloud 來獲取預測結果和特徵歸因值。以下是向我們模型發送 API 請求的示意:
credentials = GoogleCredentials.get_application_default()
discovery_url = (
'https://%s/$discovery/rest?&version=%s'
% ('ml.googleapis.com', 'v1'))
service = build(service_name, api_version,
credentials=credentials,
discoveryServiceUrl=discovery_url)
parent = 'projects/%s/models/%s/versions/%s' % (PROJECT, MODEL, VERSION)
response = service.projects().explain(body={'instances': prediction_json}, name=parent).execute()
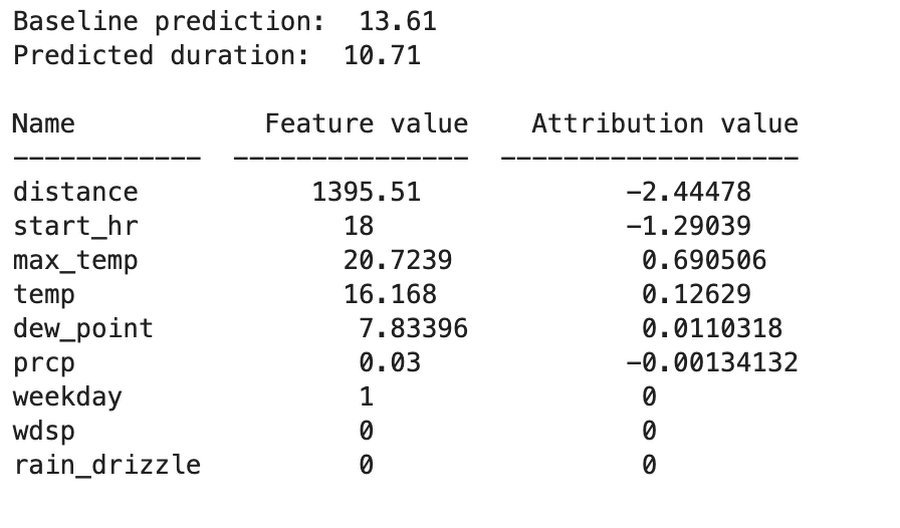
如以下範例,模型回傳以下的歸因值,這些歸因值都與我們模型的基準值有關。觀察這些歸因值可以發現,距離 (distance) 是最重要的特徵,因為它使模型的預測值從基準下降了 2.4 分鐘。此外,歸因值還顯示,騎乘的開始時間(start time,18:00 或 6:00pm)使模型預測的騎乘時間縮短 1.2 分鐘。
接下來,我們將使用 What-If 工具 來查看模型在更大量的測試範例資料集中的表現,並將歸因值視覺化。
利用 What-If 工具視覺化表格歸因值
What-If 工具是一套開源的視覺化工具,可以用來檢查各種機器學習模型。除此之外,最新釋出的版本還包含了專門給部署在 AI 平台上的 AI Explanations 模型使用的功能。您可以在這個 notebook 中找到將 What-If 工具和您的 AI 平台模型連結的程式碼。
下圖是利用我們的測試資料集與模型子集初始化 What-If 工具時,點擊數據時會看到的內容:
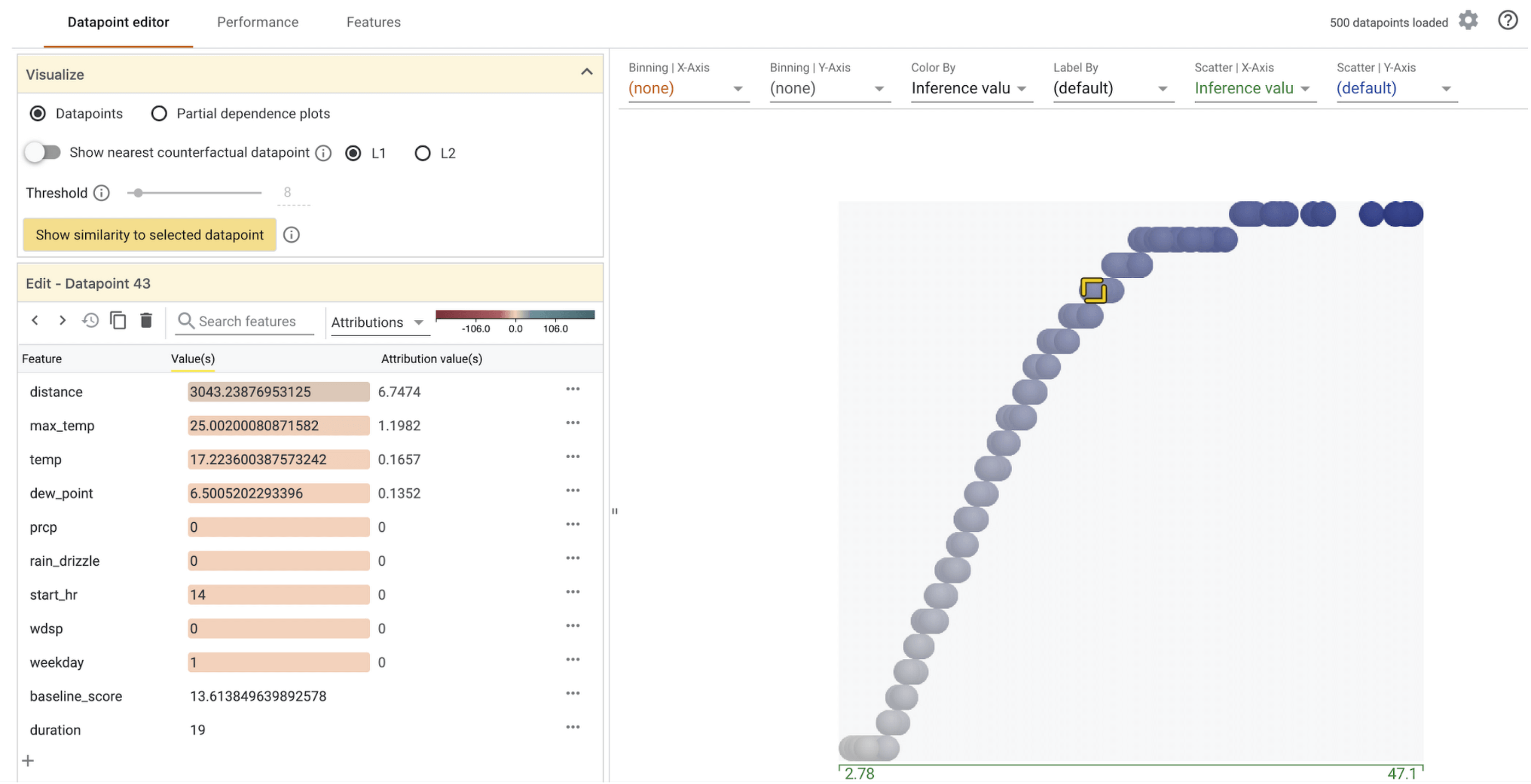
透過 What-If 工具,我們可以在右手邊查看所有 500 筆測試資料的分佈情形。Y 軸代表模型針對這些值所預測的騎乘時間。而當我們點擊單筆資料時,可以看到該筆數據的所有特徵值和每個特徵值的歸因值。What-If 工具的這個功能還能讓您自由更改特徵值,並重跑預測模型,以了解新的特徵值如何影響模型的預測:
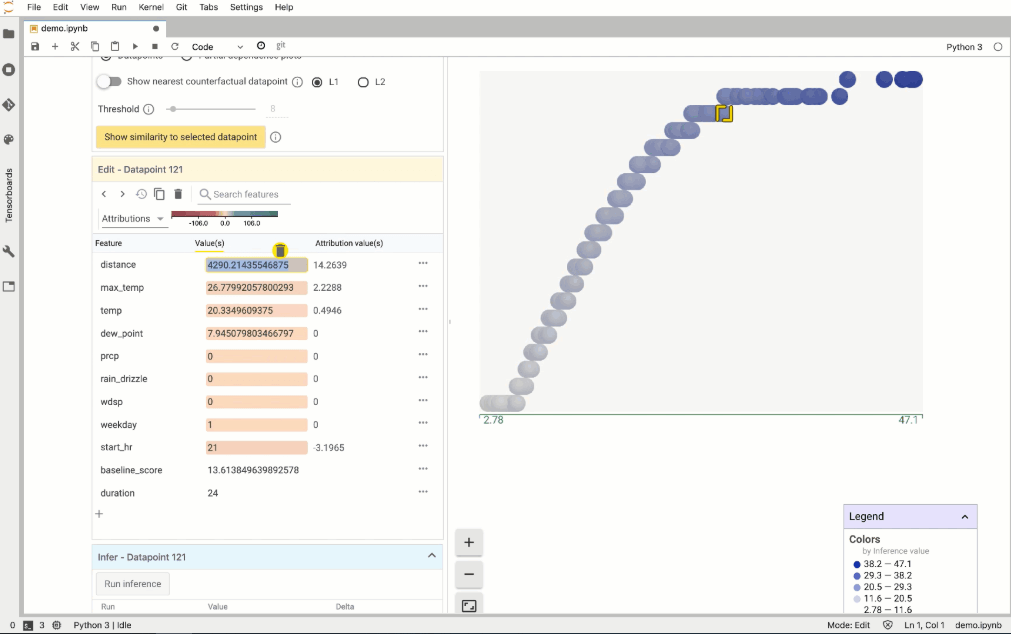
What-If 還有一項實用的功能,就是它能建立客製化圖表和散佈圖,另外,從 AI 平台回傳的屬性資料也非常好用。舉例來說,如下圖所示,我們建立一個客製化的圖表,X 軸為騎乘距離的歸因值,Y 軸則為最高溫度的歸因值:
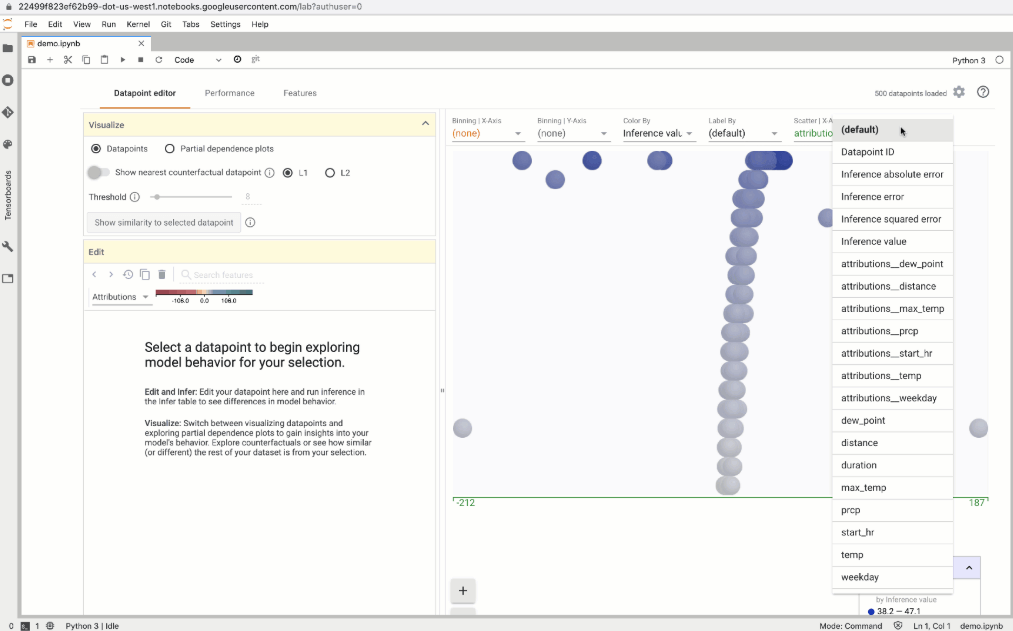
這可以幫助我們識別離群值。在這個案例中,發現了一個離群值,可以發現當騎乘距離為 0 時,自行車卻被使用了 34 分鐘,這使模型預測的騎乘時間比實際更長。
在 What-If 工具和 AI 平台歸因值中有許多值得探索之處,像是以公平的角度分析我們的模型、確保資料分布平衡等等。
實作資源請參考!
準備好進一步研究程式碼了嗎?以下資源可以協助您使用 AutoML Tables 和 AI 平台上的 AI Explanations:
- AutoML Table 文件和更多有關局部特徵重要性運算的詳細資訊
- AI 平台的 Explanations 文件
- 這篇 notebook 協助您建立表格式模型並部署到 AI 平台
- 這篇部落格文章教您從筆記本使用 AutoML Tables
- 這篇 notebook教您如何使用 AutoML Tables Python 客戶端函式庫獲取預測解釋
- 關於 What-If 工具的系列影片
- AI Explanations 的主題演講
如果您想使用與本文範例相同的資料集,可以使用 BigQuery 中倫敦共享單車的數據。本文範例將其與一部分的 NOAA 天氣資料集結合,該資料近期已更新,包含更多可用的數據。
(原文改編翻譯自 Google Cloud。)