GA 的 Vertex Pipelines,讓你可以快速可靠的複製、分享你的 ML 工作流程。身為 MLOps 的重點產品,可以用 Kubeflow Pipelines 和 TensorFlow Extended 定義你的管線流程;無伺服器的服務,讓你不需要預先準備或是手動擴展你的訓練機器。
擴展機器學習 (ML) 工作流程的最佳方法是將它們作為管線執行,其中每個管線步驟都是 ML 流程的不同部分。 管線是組織運作ML 工作流程的最佳工具,包含生產、分享和可靠地以及可重複使用 。 它們也是 MLOps 的關鍵——通過管線,您可以構建系統來自動重新訓練和部署模型。 在這篇文章中,我們將展示您可以使用 Vertex Pipelines 做什麼,最後我們將分享一個範例管線來幫助您入門。
Vertex Pipelines介紹
讓我們簡單討論 ML 管線的作用。 機器學習管線是封裝為一系列步驟(也稱為元件)的 ML 工作流程。 管線中的每一步都是一個容器,每一步的輸出都可以作為下一步的輸入。 這帶來了兩個挑戰:
- 為此,您需要一種將各個途徑步驟轉換為容器的方法
- 這將需要設置基礎設施來大規模運行您的途徑
為了解決第一個挑戰,有一些很棒的開源資料庫可以處理將管線步驟轉換為容器並管理整個管線中的輸入和輸出工件流程,使您能夠專注於構建每個管線步驟的功能。 Vertex Pipelines 支持兩種流行的開源資料庫 – Kubeflow Pipelines (KFP) 和 TensorFlow Extended (TFX)。 這意味著您可以使用這些資料庫來定義您的管線並在 Vertex Pipelines 上運行它。
其次,Vertex Pipelines 是完全無伺服器。 當您上傳並運行 KFP 或 TFX 途徑時,Vertex AI 將處理配置和擴展基礎設施以執行您的管線。 這意味著您只需為管線執行時使用的資源付費, 並且資料科學家可以專注於 ML,而不必擔心基礎設施的建置。
Vertex Pipelines 與 Vertex AI 和 Google Cloud 中的其他工具整合:您可以從 BigQuery 導入數據、使用 Vertex AI 訓練模型、將管線產出物儲存在 Cloud Storage、獲取模型評估指標並將模型部署到 Vertex AI 端點,所有步驟都在您的 Vertex Pipeline。
為了更容易操作,我們為 Vertex Pipelines 創建了一個預建元件庫。這些預先構建的元件有助於簡化在管線步驟中使用 Vertex AI 其他部分的過程,例如創建資料庫或訓練 AutoML 模型。 要使用它們,請導入預建的元件庫並直接在您的管線定義中使用元件庫中的元件。
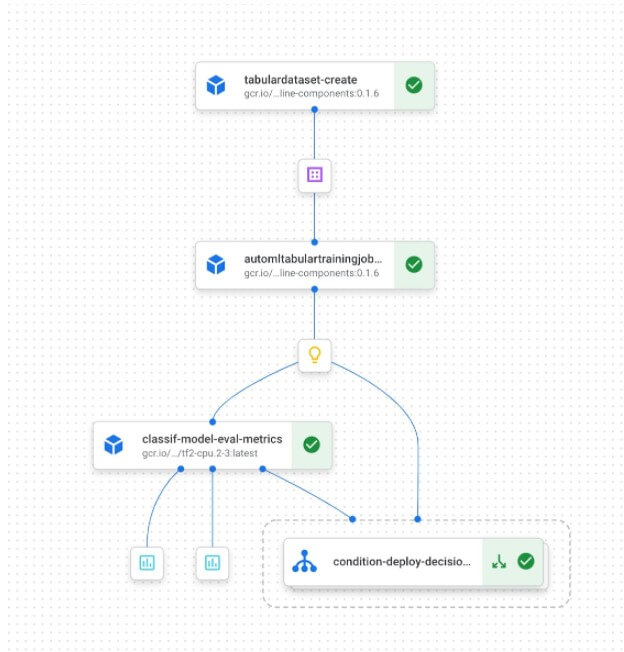
例如下圖是一個管線,該管線創建指向 BigQuery 中數據的 Vertex AI 資料庫,訓練 AutoML 模型,如果其準確性高於某個閾值,則將訓練後的模型部署到端點:
ML Metadata & Vertex Pipelines
通過管線執行的每個步驟產生的輸出,重要的是要有一種機制來追蹤管線執行中的產出物和評量指標。 當您的團隊中有多人參與開發並在不同的管線步驟中,或者為不同的 ML 任務管理多個管線時,這變得特別有用。 為了解決這個問題,Vertex Pipelines 直接與 Vertex ML Metadata整合,以實現自動化產出物、沿襲和指標追蹤。
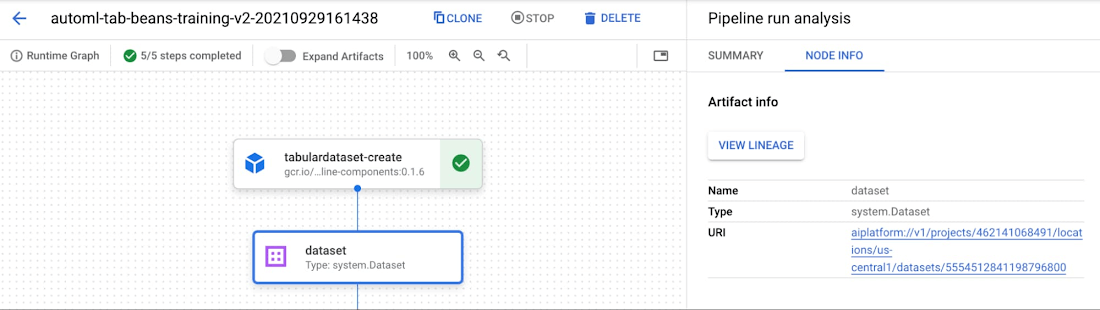
您可以在 Vertex AI 控制台和 Vertex AI SDK 中檢查Metadata途徑。 要在控制台中查看Metadata和元件,請先在查看途徑圖時單擊“擴展元件”滑塊。 然後,您可以單擊單個產出物以查看詳細信息並查看每個產出物的儲存位置:
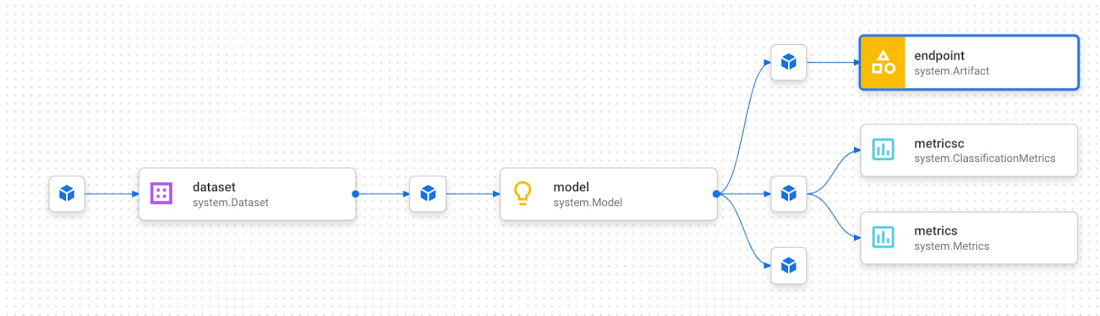
在查看輸出的產出物時,在管線的上下文中理解單個產出物也很有幫助。 為此,Vertex Pipelines 提供沿襲追蹤。 在控制台中查看元件時,單擊“查看沿襲”按鈕。 例如,對於下面的端點,我們可以看到部署到端點的模型,以及用於訓練該模型的資料集。 我們還可以在此圖中看到產生每個產出物的管線步驟:
有多種方式可以以寫程式的方式與管線元資料進行互動。 使用 Vertex ML Metadata API,您可以通過屬性或沿襲,查詢Metadata儲存中的任何產出物或執行內容。 您還可以使用 Vertex AI SDK 中的 get_pipeline_df 方法創建一個 Pandas DataFrame,其中包含來自每個管線執行的指標。 還有用於獲取產出物沿襲和過濾產出物的 SDK 方法,您可以使用它們來創建自定義儀表板來追踪您的管線。
了解更多 AI/ ML 技術,聯絡 iKala Cloud 加速企業產品與服務創新!
創建一個範例途徑
要查看 Vertex Pipelines 的執行情況,讓我們看一個使用 Kubeflow Pipelines SDK 構建的範例。 您可以在此 codelab 中找到此範例的完整管線程式碼,在這裡我們將展示一些亮點。 我們的範例途徑將使用 Google Cloud 的預建元件,並將執行以下操作:
- 在 Vertex AI 中創建資料集
- 在該資料集上訓練自定義模型
- 使用訓練好的模型做批次預測
要構建和運行此管線,我們將首先導入一些 Python 套件:
from kfp.v2 import compiler, dsl
from kfp.v2.dsl import pipeline
from google.cloud import aiplatform
from google_cloud_pipeline_components import aiplatform as gcc_aip
我們使用三個函式庫在 Vertex AI 上構建和執行這個管線:
- Kubeflow Pipelines SDK 用於構建我們的元件並將它們連接到一個管線中
- Vertex AI SDK 在 Vertex Pipelines上執行我們的管線
- Google Cloud components library 利用預建的元件與各種Google Cloud services互動
因為我們正在使用第一方預建的元件,所以我們不需要編寫樣板程式碼來執行每一個任務。 反之,我們可以直接在管線設定中將配置檔案中的變量傳遞給元件。 你可以在 codelab 中看到完整的定義,我們在下面展示了一些亮點:
@pipeline(name="custom-training-pipeline",
pipeline_root=PIPELINE_ROOT)
def pipeline(
bq_source: str = "bq://your-project.your_bq_dataset.your_bq_table",
display_name: str = "pipeline-train",
project: str = "YOUR_PROJECT_HERE",
gcp_region: str = "us-central1",
api_endpoint: str = "us-central1-aiplatform.googleapis.com",
):
dataset_create_op = gcc_aip.TabularDatasetCreateOp(
display_name=display_name,
bq_source=bq_source,
project=project
)
training_op = gcc_aip.CustomContainerTrainingJobRunOp(
display_name="pipeline-beans-custom-train",
container_uri="gcr.io/YOUR_PROJECT_HERE/your_gcr_uri:tag",
project=project,
location=gcp_region,
dataset=dataset_create_op.outputs["dataset"],
…
bigquery_destination="bq://your_cloud_project",
model_display_name="beans-model-pipeline",
)
batch_predict_op = gcc_aip.ModelBatchPredictOp(
project=project,
location=gcp_region,
job_display_name="beans-batchpred",
model=training_op.outputs["model"],
gcs_source_uris=["gs://path/to/test-examples.csv"],
instances_format="csv",
…
gcs_destination_output_uri_prefix="gs://your-bucket/batchpredresults"
)
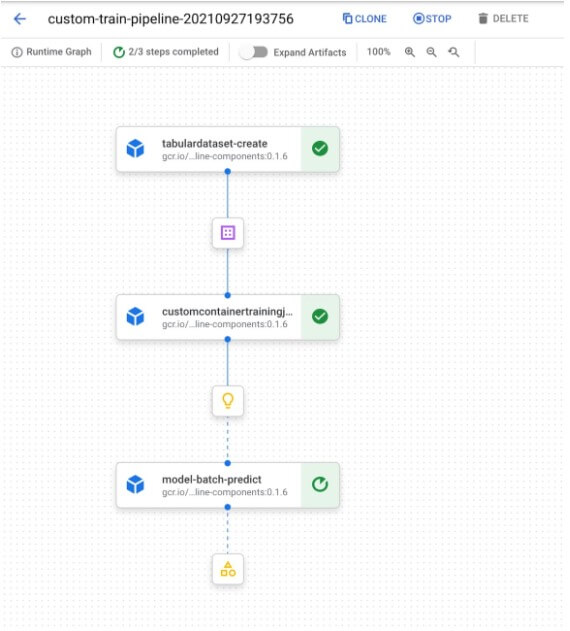
該管線首先使用 TabularDatasetCreateOp元件在 Vertex AI 中創建資料集,傳入BigQuery 資料集中的 資料表。 然後,創建的資料集將傳遞給我們的CustomContainerTrainingJobRunOp 元件,並在我們的 scikit-learn 模型訓練任務中使用。 我們已經傳遞了指向 Container Registry 中一個容器的設定參數,我們已經在其中部署了我們的 scikit-learn 訓練程式碼。 該元件的輸出是 Vertex AI 中的模型。 在此管線的最後一個元件中,我們通過提供一個我們想要進行預測的範例- CSV 文件,在此模型上運行批次預測任務。
當我們在 Vertex AI 上編譯和執行這個管線時,我們可以在它執行時在控制台中檢查管線圖:
開始使用 AI/ ML 提升運營效能,聯繫 iKala Cloud 諮詢!
開始使用 Vertex Pipelines 構建
準備好在 Vertex AI 上執行您的可擴展 ML 管線了嗎? 查看以下資源並開始使用:
- Vertex Pipelines 文件
- GitHub 上的官方範例途徑
查看這個 codelab 以了解 Vertex Pipelines 的介紹,以及了解 Vertex Pipelines 如何與 Vertex ML Metadata配合使用。
(本文翻譯改編自 Google Cloud。)