本文是一系列教學的第三部分,向您展示如何利用 Google Cloud Platform(GCP) 中的 TensorFlow 和 Cloud Machine Learning Engine 實作機器學習 (ML) 推薦系統。本文將會介紹如何利用 Google Analytics 360 收集的數據,透過 TensorFlow 建模做到網站的內容推薦。
這一系列教學包含以下內容:
- 總覽
- 建立系統 (一)
- 訓練和調校機器學習引擎 (二)
- 運用 Google Analytics 數據 (三) (本教程)
- 部署推薦系統 (四)
本文假設您已完成本系列教學的前兩部分。基於以下的內容,本文會向您展示如何利用 TensorFlow WALS 模型,爲內容網站提供推薦:
- 以用戶行為事件作為推薦模型的訓練輸入數據
- 每個事件代表用戶與網站某元件的互動
- 對內容網站而言,相關事件指的是用戶透過點擊文章連結來選擇要閱讀的文章
- 這些事件可以利用 Google Analytics 追蹤
下圖顯示的是本教學中會使用到的元件 (components):
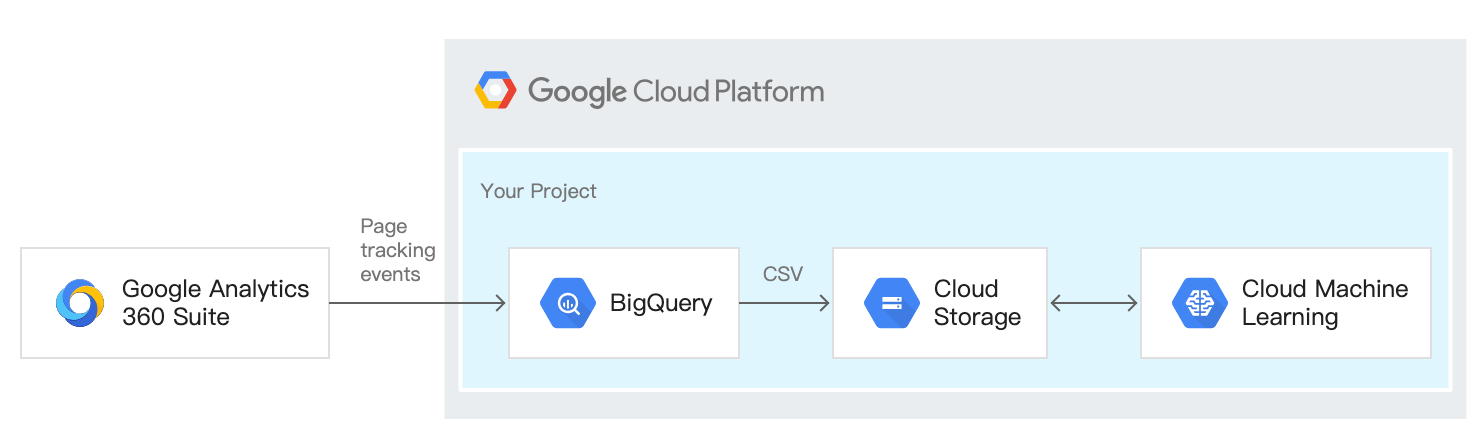
目標
- 從 BigQuery 取得 Google Analytics 數據
- 訓練推薦模型
- 調整模型的超參數
- 運行訓練好的 TensorFlow 模型,輸出內容推薦。
成本
本教學使用 Cloud Storage、Cloud Machine Learning Engine 和 BigQuery ,皆是計費服務。您可以使用 費用計算機 預先估算成本,本教學的預計成本為 $0.15 美金。如果您是新的 GCP 用戶,可以獲得 免費試用 的機會。
在開始之前
本教學假設您已完成本系列教學的前兩部分,且已經創建了一個 GCP project 和一個 Cloud Storage bucket。此外,也會假設您已經根據 第一部分教學 的說明完成模型安裝。
為了完成本篇教學, 您必須啟用 BigQuery API:
1. 選擇您在本系列教學的前幾部分所使用的 GCP project:
前往 PROJECT 頁面
2. 啟用 BigQuery API :
啟用 API
利用 Google Analytics 事件來建構推薦模型
這個部分將會概述如何利用 Google Analytics 事件來建構推薦模型。您不需要擁有 Google Analytics 帳戶也可以進行本教學, 因為本教學會提供 Google Analytics 範例數據,以及如何將該數據上傳到 BigQuery 的步驟。
如果您已經擁有 Google Analytics 360 帳戶,並希望設定此帳戶來提供推薦系統所需要的數據,請閱讀此部分。
查看 Google Analytics 事件字段
四個和推薦有關的 Google Analytics 點擊事件的字段:
- 時間戳記 — 事件的時間戳記。對內容推薦來說,您感興趣的點擊事件在 Google Analytics 中被稱作網頁追蹤匹配。所有匹配的時間戳記 Google Analytics 都會自動儲存。
- 用戶 ID — 用戶的唯一 ID 或 client 的唯一 ID。 Google Analytics 預設會使用 cookie 跟蹤用戶,cookie 會記錄瀏覽器 client 端在 web session 裡的唯一 ID。本文假設用戶的身份是基於這個 client ID。在用於 Google Analytics 360 的 BigQuery 結構 中,client ID 儲存在 fullVisitorId 欄位中。透過啟用 Google Analytics 的用戶 ID 功能(此功能可以追蹤用戶在所有裝置上的互動情況),可以讓推薦更準確。如果您想使用用戶 ID,必須要在 SQL 查詢中(在本文後面 準備數據 的部分會使用到),將原先參考fullVisitorId 的值改成參考 userId。
- 文章 ID:文章的唯一 ID。如下一節所描述,建議透過在 Google Analytics 設定 自定義維度 來捕捉文章 ID。您也可以使用文章的 URL 作為唯一的識別碼,只要 URL 不會隨時間改變即可。如果您使用 URL 作為唯一的識別碼,請在下面的 SQL 查詢中用 hits.page.pagePath 取代 articleId。
- 網頁停留時間 — 用戶在網頁上查看文章所花的時間(以秒為單位)。 Google Analytics 的網頁追蹤事件不會明確追蹤網頁停留時間。本教學採用一般常見的假設來計算網頁停留時間:用戶訪問下一個網頁的追蹤事件時間減去用戶訪問當前網頁的追蹤事件時間。本文後面的 準備數據 部分會有更詳細的說明。
設定 Google Analytics 來捕捉事件
按照自訂維度在 Google Analytics 文件上的說明,新增一個 article ID 維度 (具有匹配層級範圍) 到網頁追蹤事件。 記下自訂維度的索引,因為稍後您從 BigQuery 導出事件數據時的 SQL 查詢會用到。此外,您還需要在 Google Analytics 中建立一個與要產生推薦的屬性相符的 view。
將 Google Analytics 的數據轉移到 BigQuery
如果您是使用 Google Analytics 360,可以直接將網頁追蹤事件的數據導入到 GCP 專案中的 BigQuery 資料庫。想了解如何設定,請參閱 BigQuery導出 的 Google Analytics 文件。
事件的數據每天都會從 Google Analytics 傳輸到和您在導出設定時選擇的 Google Analytics view 相符合的 BigQuery 數據集。每天的資料都會在數據集中產生一張獨立的表格。
從 BigQuery 準備用於訓練的數據
在本節中,你將上傳範例數據到 BigQuery,並導出作為訓練用的數據。
上傳 Google Analytics 範例數據
本教學附帶一個 Google Analytics 範例數據集,其中包含來自奧地利新聞網站的網頁追蹤事件Kurier.at. 。文件結構檔 ga_sessions_sample_schema.json 位在教學程式碼的 data 資料夾中,而數據檔 ga_sessions_sample.json.gz 則位在本教學相關的公開 Cloud Storage bucket 中。
要 上傳此數據集 到 BigQuery,您必須:
1. 在你的 shell 中,設定環境變數 BUCKET 為你在第二部分建立的 Cloud Storage bucket URL。
BUCKET=gs://[YOUR_BUCKET_NAME]2. 複製數據檔 ga_sessions_sample.json.gz 到您在 第二部分 建立的 Cloud Storage bucket 當中。
gsutil cp
gs://solutions-public-assets/recommendation-tensorflow/data/ga_sessions_sample.json.gz ${BUCKET}/data/ga_sessions_sample.json.gz
3. 前往 BigQuery 頁面
4. 選擇您 project 中的數據集,或是按照 BigQuery指南 建立新的數據集
5. 在導覽視窗中,將滑鼠移到數據集的名稱上,點選箭頭向下的圖示,再點擊 建立新表格。
6. 在 建立表格 頁上 數據來源 的部分,執行以下操作:
* 位置 的部分,請選擇 Google Cloud Storage ,並輸入以下以下路徑:
[YOUR_BUCKET_NAME]/data/ga_sessions_sample.json.gz
* 注意這個路徑不包含 gs:// 前綴字
* 資料格式 的部分,請選擇 JSON
7. 在 建立表格 頁上 目標表格 的部分,執行以下操作:
* 表格名稱 的部分,請選擇數據集,然後在表格名稱的欄位輸入表格名稱(例如:ga_sessions_sample)
* 確認 表格類型 設為 原始 Native table
8. 用文字編輯器打開 ga_sessions_sample_schema.json 文件結構檔,選取並複製所有內容
9. 在 結構 的部分,點選以文字編輯 ,並將表格 結構 貼上到文字輸入框:
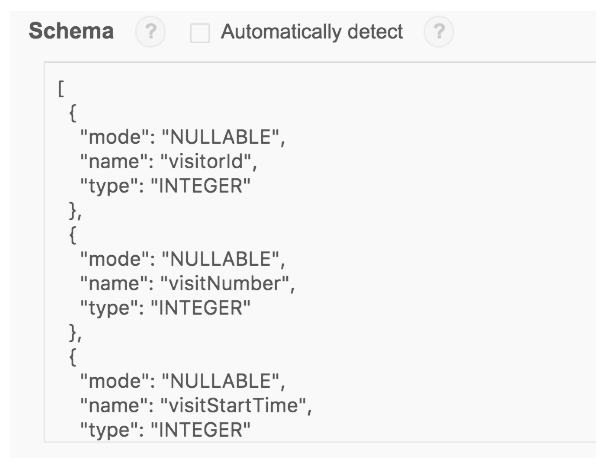
10. 點擊 建立表格
導出訓練數據
模型程式以 CSV 檔作為輸入,檔案的標題列需包含三個欄位:
* clientId
* contentId
* timeOnPage
要建立訓練數據,假設您已經導入範例數據集到名為 GA360_sample 的數據集下的 ga_sessions_sample table 。您可以按照以下的方式建立 CSV 訓練數據檔。
首先,執行 SQL 查詢,從 BigQuery 中的網頁追蹤事件表選出這些欄位,將查詢結果存到表格中:
- 前往 BigQuery 頁面
- 點選 撰寫查詢 按鈕
- 在 新建查詢 的文字區域,輸入以下查詢:
SELECT
fullVisitorId as clientId,
ArticleID as contentId,
(nextTime - hits.time) as timeOnPage,
FROM(
SELECT
fullVisitorId,
hits.time,
MAX(IF(hits.customDimensions.index=10,
hits.customDimensions.value,NULL)) WITHIN hits AS ArticleID,
LEAD(hits.time, 1) OVER (PARTITION BY fullVisitorId, visitNumber
ORDER BY hits.time ASC) as nextTime
FROM [GA360_sample.ga_sessions_sample]
WHERE hits.type = "PAGE"
) HAVING timeOnPage is not null and contentId is not null;
範例數據集中的文章 ID 儲存在索引值為10的自定義維度中。 這在內部的選擇子句中使用,來過濾事件。此外,請注意,網頁停留時間是某一用戶 ID fullVisitorId 當前網頁匹配事件到下一個事件所經過的時間。
1. 點選 顯示選項 按鈕
2. 在 目標表格 頁點選 選擇表格
3. 選擇和您導入數據相同的數據集
4. 輸入表格 ID(例如: recommendation_events),並點選 OK
5. 點選 執行查詢 按鈕
下一步則是將 目標表格導出 到您在 第二部分 建立的 Cloud Storage bucket 中的 CSV檔。
1. 前往 BigQuery 頁面
GO TO THE BIGQUERY PAGE
2. 在導覽視窗中,找到您將範例數據上傳的數據集,並將其展開,顯示以下內容
 3. 點選上一步目標表格旁箭頭向下的圖示
3. 點選上一步目標表格旁箭頭向下的圖示
4. 點選 導出表格。將會顯示 導出到 Google Cloud Storage 的對話框
5. 維持預設狀態 — 請確認 導出格式 設定為 CSV,壓縮 設定為 無
6. 在 Google Cloud Storage URI 欄位,輸入符合以下格式的 URL :
gs://[YOUR_BUCKET_NAME]/ga_pageviews.csv
[YOUR_BUCKET_NAME] 的部分,請使用您在第二部分建立的 Cloud Storage bucket 的名稱。
7. 點選 OK,導出表格。作業正在運行時,(解壓縮)會顯示在導覽列中表格名稱旁邊。
您可以在導覽列上方作業歷史中查找解壓縮作業,了解目前作業進度。
訓練推薦模型
1. 前往您在本系列教程 第一部分 安裝的模型程式碼
2. 確認 在 mltrain.sh script 中的 BUCKET 變數 指向您在 第二部分 建立的 Cloud Storage bucket。
BUCKET="gs://[YOUR_BUCKET_NAME]"
3. 執行 mltrain.sh script,傳入從 BigQuery 導出的 CSV 檔路徑,並將 data-type 參數設定為 web_views
舉例來說:要在AI平台訓練模型,需要使用下面 URL 的 CSV 檔:
gs://[YOUR_BUCKET_NAME]/ga_pageviews.csv
4. 使用以下指令:
./mltrain.sh train $BUCKET ga_pageviews.csv --data-type web_views
訓練完成後,模型數據會保存在訓練任務的工作目錄下名稱為 model 的子目錄。這個數據是由幾個陣列所組成的,陣列都是 numpy 格式:
- 用戶因子矩陣,存在 row.npy 中
- 行因子矩陣,存在 col.npy 中
- 評級矩陣列索引和 client ID 的配對,存在 user.npy 中
- 評級矩陣行索引和 article ID 的配對,存在 item.npy 中
有關行列因子矩陣的說明,請參閱教學的 概述。
工作目錄的路徑由三個部分組成,包含在 mltrain.sh script 中的 BUCKET 變數、 /jobs/以及訓練任務的識別碼。訓練任務的識別碼也是設定 在mltrain.sh script 中。識別碼預設為 wals_ml_train ,加上起始日期和時間。舉例來說:假如 BUCKET 變數為 gs://my_bucket,模型檔案會儲存到以下路徑:
gs://my_bucket/jobs/wals_ml_train_20171201_120001/model/row.npy
gs://my_bucket/jobs/wals_ml_train_20171201_120001/model/col.npy
gs://my_bucket/jobs/wals_ml_train_20171201_120001/model/user.npy
gs://my_bucket/jobs/wals_ml_train_20171201_120001/model/item.npy
調整 Google Analytics 數據的模型超參數
本系列教學的第二部分說明了如何利用AI平台超參數調整功能幫模型調整參數。為了讓推薦更準確,應該不斷重複對 Google Analytics 數據集執行此過程,因為頁面停留時間和第二部分用的 MovieLens 評級,兩者的規模和分佈有很大的差異。
要對 Google Analytics 數據調整超參數,請執行 mltrain.sh script 並附帶 tune 選項,傳入從 BigQuery 導出的 CSV 檔路徑,並將 data-type 參數設定為 web_views。
./mltrain.sh tune data/ga_pageviews.csv --data-type web_views
mltrain.sh script 使用 config/config_tune_web.json 設定檔來調整超參數。特徵權重因子不是調整超參數的一部分,因為頁面停留數據需要用指數型觀察權重。有關調整設定的更多資訊,請參閱本系列教學的第二部分。
下表總結了範例數據的超參數調整結果:
| 超參數名稱 | 描述 | 調整發現的值 |
| latent_factors | 潛在因子 K | 30 |
| regularization | L2 正規化常數 | 5.05 |
| unobs_weight | 未觀察到的權重 | 0.01 |
| feature_wt_factor | 觀察到的權重(線性) | N/A |
| feature_wt_exp | 特徵權重指數 | 5.05 |
(表1.) 利用AI平台調整範例 Google Analytics 數據發現的超參數值
執行模型程式碼來產生推薦
在本教學提供的程式檔 model.py 中有一個叫 generate_recommendations 的 方法,用已訓練模型產生一系列推薦時可以用此方法。想了解利用行列因子產生預測的理論基礎,請參閱本系列教學的概述。
generate_recommendations 方法需要以下參數:
- 評級矩陣中的用戶列索引
- 用戶已經評級過的項目索引列表(即用戶先前看過的文章的項目索引)
- 訓練模型產生的行列因子
- 所需建議的數量
在評級矩陣中用戶的列索引和 client ID 不同。要取得用戶的列索引,您可以在 Google Analytics 的 client ID 和評級矩陣列索引的配對陣列中尋找。同樣地,評級矩陣中文章的行索引也和文章 ID 不同,必須要在配對文章 ID 和行索引的陣列中尋找。
generate_recommendations 方法 透過爲使用者尚未拜訪的網頁生成預測評級(本案例是預測網頁停留時間)來產生推薦。 對預測結果進行排序,並返回前 K 項, K 值是所需的推薦數量。
產生推薦的範例
假設您有一個模型數據存在 /tmp/model 目錄下。您想產生五個推薦給 client ID 1000163602560555666 ,這個 ID 代表之前瀏覽過 295436355、295044773 和 295195092 文章的一位用戶。以下是用 Python 所撰寫的程式碼,用來產生推薦:
import numpy as np
from model import generate_recommendations
client_id = 1000163602560555666
already_rated = [295436355, 295044773, 295195092]
k = 5
user_map = np.load("/tmp/model/user.npy")
item_map = np.load("/tmp/model/item.npy")
row_factor = np.load("/tmp/model/row.npy")
col_factor = np.load("/tmp/model/col.npy")
user_idx = np.searchsorted(user_map, client_id)
user_rated = [np.searchsorted(item_map, i) for i in already_rated]
recommendations = generate_recommendations(user_idx, user_rated, row_factor, col_factor, k)
使用 np.searchsorted 方法在用戶和項目的配對陣列上尋找先前被閱讀過的文章的用戶索引和行索引。返回的建議值是文章的行索引列表,可以利用 item map 找回對應的文章 ID:
article_recommendations = [item_map[i] for i in recommendations]
利用生產系統產生推薦
一個生產系統要根據 Google Analytics 數據產生推薦,還需要以下要素:
- 定期訓練推薦模型,像是:每晚
- 用 API 的方式提供推薦服務
在本系列教學的第四部分會說明如何在 GCP 上部署生產系統,去執行這些任務。
清除
如果您想繼續進行本系列教學,直接繼續第四部分教學即可,不需要清除已建立的東西。但如果您不想繼續本系列教學,請刪除您先前在 GCP 帳戶中建立的資源,以免產生費用。
刪除專案
避免計費最簡單的方式,是直接刪除您為了本系列教學所建立的專案。要刪除專案:
警告:刪除專案會產生以下結果:
1. 如果您一開始是在既有的專案操作本系列教學,在刪除此專案的同時,也會刪除您在專案中的其他工作。
2. 無法再使用同一個專案 ID。如果您未來還會再使用建立的專案 ID,請刪除專案內的資源,不要刪除整個專案,這是為了確保有使用到此專案 ID 的 URL,像是appspot.com URL,仍可以存取。
如果您還要持續進行更多課程或快速入門的教學,重用專案可以避免超出專案配額。
1. 在 GCP 控制台前往 專案頁面
2. 在專案清單中,選擇您想要刪除的專案,並點選 刪除專案
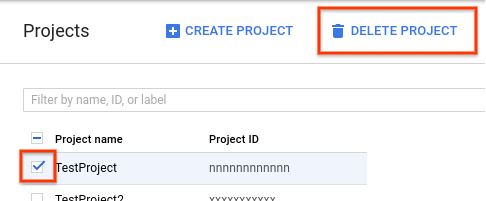
3. 在對話框中輸入專案 ID ,並點選 關閉,以刪除專案
下一步是什麼?
- 下個教學,部署推薦系統(第四部分) 會教您如何在 GCP 上部署生產系統來提供推薦
- 深入了解 GCP上的機器學習
(原文翻譯自 Google Cloud。)